
This article is an expanded version of one originally published at EE Times' Embedded.com Design Line. It is reprinted here with the permission of EE Times.
In order for robots to meaningfully interact with objects around them as well as move about their environments, they must be able to see and discern their surroundings. Cost-effective and capable vision processors, fed data by depth-discerning image sensors and running robust software algorithms, are transforming longstanding autonomous and adaptive robot aspirations into realities.
By Brian Dipert
Editor-in-Chief
Embedded Vision Alliance
and
Yves Legrand
Automation and Robotics Global Market Director, Vertical Solutions Marketing
Freescale Semiconductor
and
Bruce Tannenbaum
Principal Product Marketing Manager
MathWorks
Robots, as long portrayed both in science fiction and shipping-product documentation, promise to free human beings from dull, monotonous and otherwise undesirable tasks, as well as to improve the quality of those tasks' outcomes through high speed and high precision. Consider, for example, the initial wave of autonomous consumer robotics systems that tackle vacuuming, carpet scrubbing and even gutter-cleaning chores. Or consider the ever-increasing prevalence of robots in a diversity of manufacturing line environments (Figure 1).


Figure 1. Autonomous consumer-tailored products (top) and industrial manufacturing systems (bottom) are among the many classes of robots that can be functionally enhanced by the inclusion of vision processing capabilities.
First-generation autonomous consumer robots, however, employ relatively crude schemes for learning about and navigating their surroundings. These elementary techniques include human-erected barriers comprised of infrared transmitters, which coordinate with infrared sensors built into the robot to prevent it from tumbling down a set of stairs or wandering into another room. A built-in shock sensor can inform the autonomous robot that it's collided with an immovable object and shouldn't attempt to continue forward or, in more advanced mapping-capable designs, even bother revisiting this particular location. And while manufacturing robots may work more tirelessly, faster, and more exactly than do their human forebears, their success is predicated on incoming parts arriving in fixed orientations and locations, thereby increasing the complexity of the manufacturing process. Any deviation in part position and/or orientation will result in assembly failures.
Humans use their eyes (along with other senses) and brains to discern and navigate through the world around them. Conceptually, robotic systems should be able to do the same thing, leveraging camera assemblies, vision processors, and various software algorithms. Historically, such technology has typically only been found in a short list of complex, expensive systems. However, cost, performance and power consumption advances in digital integrated circuits are now paving the way for the proliferation of vision into diverse and high-volume applications, including an ever-expanding list of robot implementations. Challenges remain, but they're more easily, rapidly, and cost-effectively solved than has ever before been possible.
Software Techniques
Developing robotic systems capable of visually adapting to their environments requires the use of computer vision algorithms that can convert the data from image sensors into actionable information about the environment. Two common tasks for robots are identifying external objects and their orientations, and determining the robot’s location and orientation. Many robots are designed to interact with one or more specific objects. For situation-adaptive robots, it's necessary to be able to detect these objects when they are in unknown locations and orientations, as well as to comprehend that these objects might be moving.
Cameras produce millions of pixels of data per second, a payload that creates a heavy processing burden. One common way to resolve this challenge is to instead detect multi-pixel features, such as corners, blobs, edges, or lines, in each frame of video data (Figure 2). Such a pixel-to-feature transformation can lower the data processing requirement in this particular stage of the vision processing pipeline by a factor of a thousand or more; millions of pixels reduce to hundreds of features that a robot can then productively use to identify objects and determine their spatial characteristics (Figure 3).

Figure 2. Four primary stages are involved in fully processing the raw output of a 2D or 3D sensor for robotic vision, with each stage exhibiting unique characteristics and constraints in terms of its processing requirements.
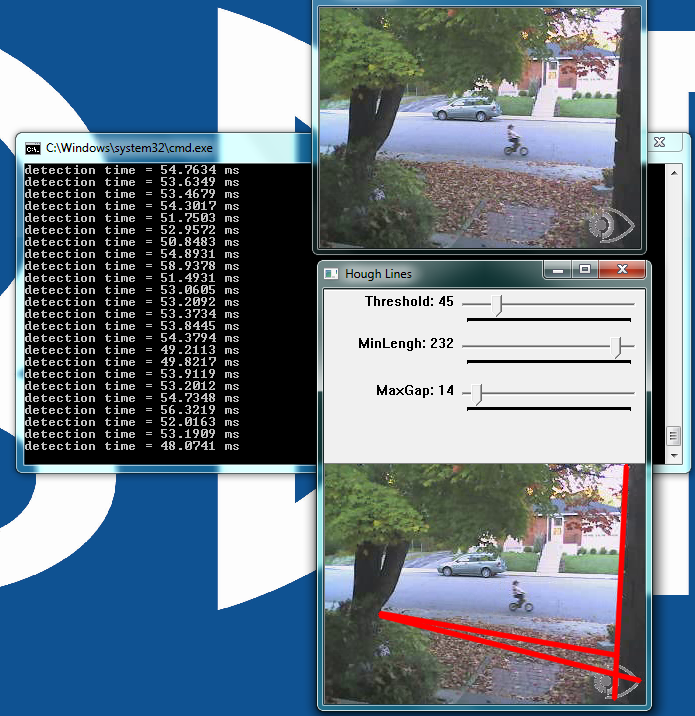
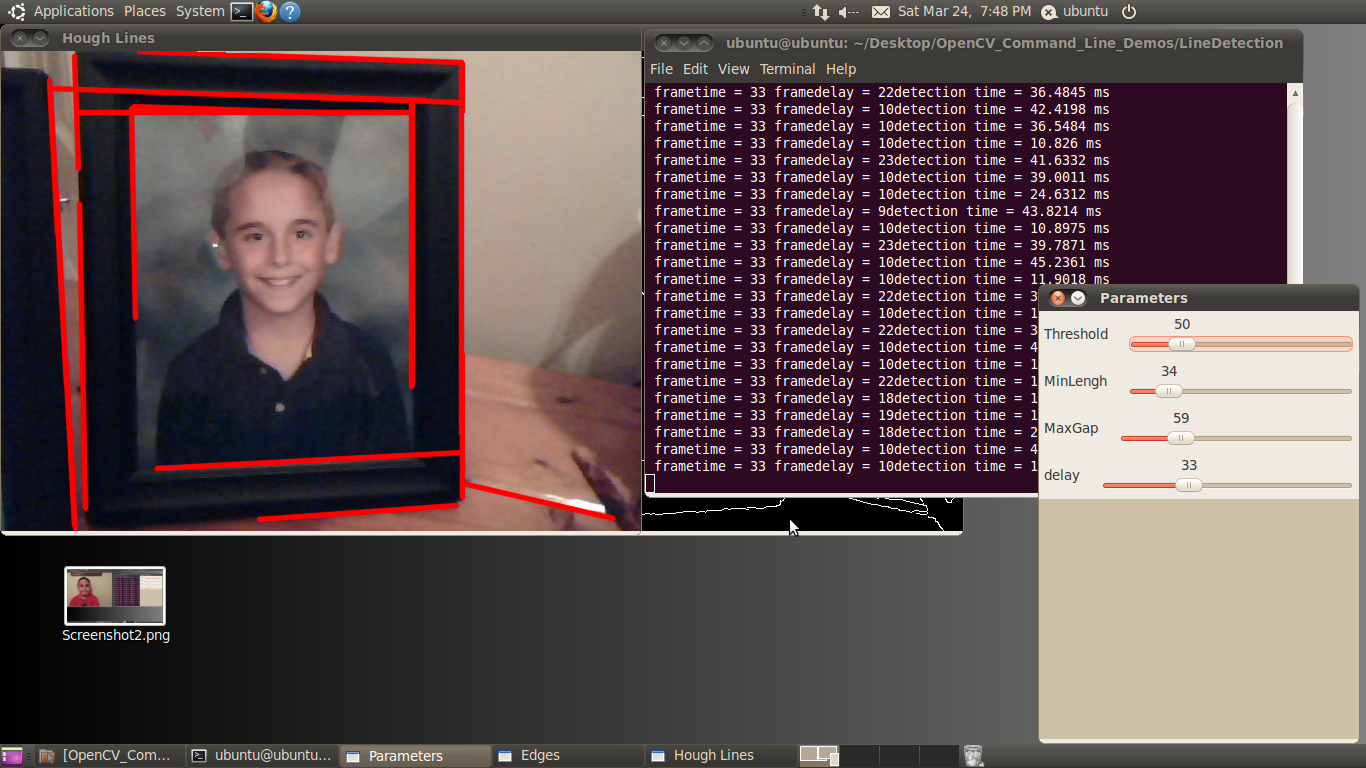

Figure 3. Common feature detection algorithm candidates include the MSER (Maximally Stable Extremal Regions) method (top), the SURF (Speeded Up Robust Features) algorithm (middle), and the Shi-Tomasi technique for detecting corners (bottom) (courtesy MIT).
Detecting objects via features first involves gathering a large number of features, taken from numerous already-captured images of each specified object at various angles and orientations. Then, this database of features can find use in training a machine learning algorithm, also known as a classifier, to accurately detect and identify new objects. Sometimes this training occurs on the robot; other times, due to the high level of computation required, the training occurs off-line. This complexity, coupled with the large amount of training data needed, are drawbacks to machine learning-based approaches. One of the best-known object detection algorithms is the Viola-Jones framework, which uses Haar-like features and a cascade of Adaboost classifiers. This algorithm is particularly good at identifying faces, and can also be trained to identify other common objects.
To determine object orientation via features requires an algorithm such as the statistics-based RANSAC (Random Sampling and Consensus). This algorithm uses a subset of features to model a potential object orientation, and then determines how many other features fit this model. The model with the largest number of matching features corresponds to the correctly recognized object orientation. To detect moving objects, you can combine feature identification with tracking algorithms. Once a set of features has been used to correctly identify an object, algorithms such as KLT (Kanade-Lucas-Tomasi) or Kalman filtering can track the movement of these features between video frames. Such techniques are robust in spite of changes in orientation and occlusion, because they only need to track a subset of the original features in order to be successful.
The already described algorithms may be sufficient for stationary robots. For robots on the move, however, you will also need to employ additional algorithms in order for them to safely move within their surroundings. SLAM (Simultaneous Localization and Mapping) is one category of algorithms that enables a robot to build of a map of its environment and keep track of its current location. Such algorithms require methods for mapping the environment in three dimensions. Many depth-sensing sensor options exist; one common approach is to use a pair of 2D cameras configured as a “stereo” camera, acting similarly to the human visual system.
Stereo cameras rely on epipolar geometry to derive a 3D location for each point in a scene, using projections from a pair of 2D images. As previously discussed from a 2D standpoint, features can also be used to detect useful locations within the 3D scene. For example, it is much easier for a robot to reliably detect the location of a corner of a table than the flat surface of a wall. At any given location and orientation, the robot can detect features that it can then compare to its internal map in order to locate itself and/or improve the map's quality. Given that objects can and often do move, a static map is not often useful for a robot attempting to adapt to its environment.
Processing Options
As we begin to consider how to create an efficient implementation of robot vision, it can be useful to divide the required processing steps into stages. Specifically, the processing encompassed by the previously discussed algorithms can be divided into four stages, with each stage exhibiting unique characteristics and constraints in terms of its processing requirements (Reference 1). A wide variety of vision processor types exist, and different types may be better suited for each algorithm processing stage in terms of performance, power consumption, cost, function flexibility, and other factors. A vision processor chip may, in fact, integrate multiple different types of processor cores to address multiple processing stages' unique needs (Figure 4).
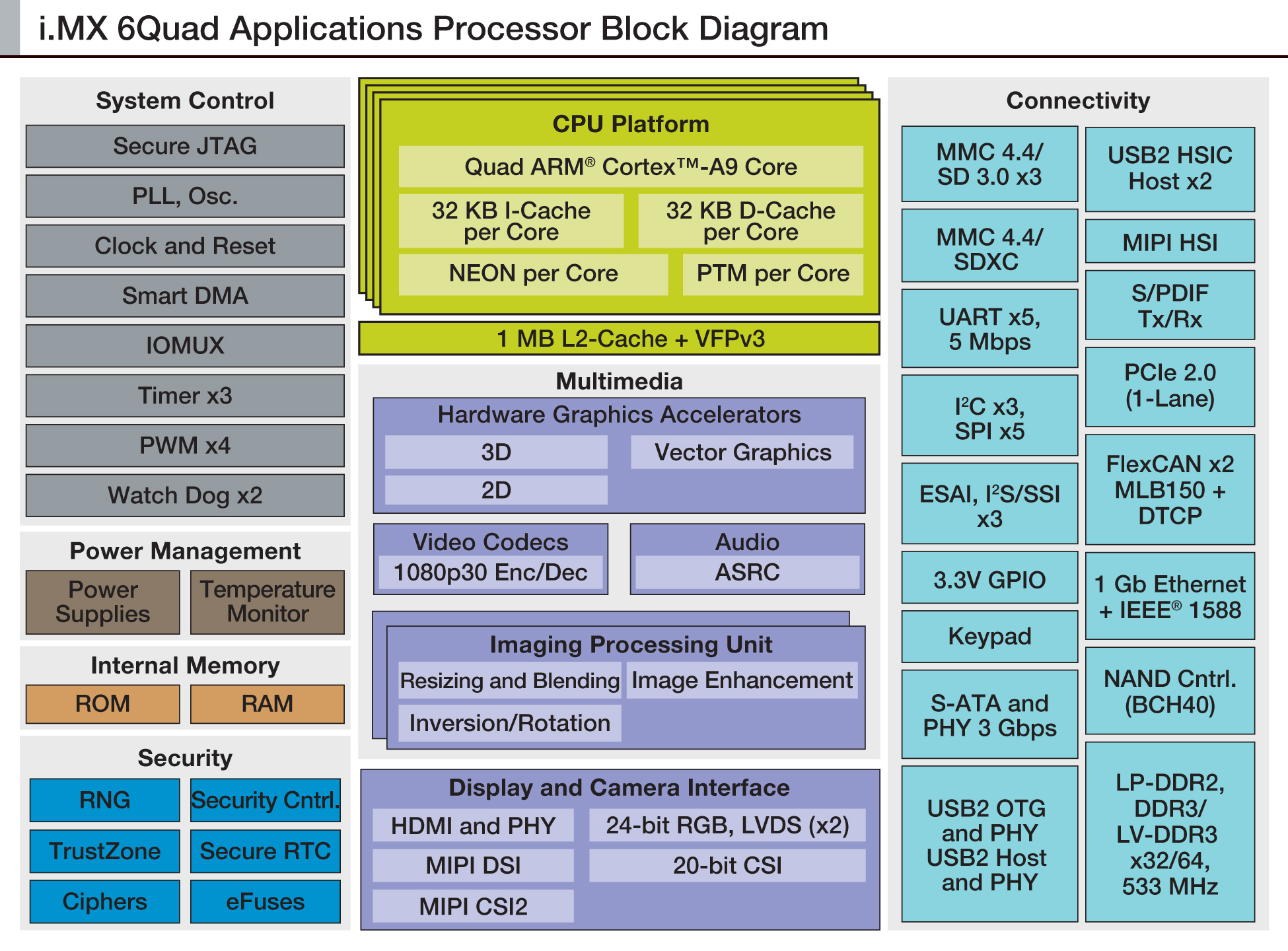
Figure 4. A vision processor may integrate multiple types of cores to address multiple processing stages' unique needs.
The first processing stage encompasses algorithms that handle various sensor data pre-processing functions, such as:
- Resizing
- Color space conversion
- Image rotation and inversion
- De-interlacing
- Color adjustment and gamut mapping
- Gamma correction, and
- Contrast enhancement
Each pixel in each frame is processed in this stage, so the number of operation per second is tremendous. And in the case of stereo image processing, the two image planes must be simultaneously processed. One processing option for these kinds of operations is a dedicated hardware block, sometimes referred to as an IPU (Image Processing Unit). Recently introduced vision processors containing IPUs are able to handle two simultaneous image planes, each with 2048×1536 pixel (3+ million pixel) resolution, at robust frame rates.
The second processing stage handles feature detection, where (as previously discussed) corners, edges and other significant image regions are extracted. This processing step still works on a pixel-by-pixel basis, so it is well suited for highly parallel architectures, this time capable of handling more complex mathematical functions such as first- and second-order derivatives. DSPs (digital signal processors), FPGAs (field programmable gate arrays), GPUs (graphics processing units), IPUs and APUs (array processor units) are all common processing options. DSPs and FPGAs are highly flexible, therefore particularly appealing when applications (and algorithms used to implement them) are immature and evolving. This flexibility, however, can come with power consumption, performance and cost tradeoffs versus alternative approaches.
On the other end of the flexibility-versus-focus spectrum is the dedicated-function IPU or APU, developed specifically for vision processing tasks. It can process several dozen billion operations per second but, by being application-optimized, it is not a candidate for more widespread function leverage. An intermediate step between the flexibility-versus-function optimization spectrum extremes is the GPU, historically found in computers but now also embedded within application processors used in smartphones, tablets and other high-volume applications. Floating-point calculations such as the least squares function in optical flow algorithms, descriptor calculations in SURF (the Speeded Up Robust Features algorithm used for fast significant point detection), and point cloud processing are well suited for highly parallel GPU architectures. Such algorithms can alternatively run on SIMD (single-instruction multiple-data) vector processing engines such as ARM's NEON or the AltiVec function block found within Power architecture CPUs.
In the third image processing stage, the system detects and classifies objects based on feature maps. In contrast to the pixel-based processing of previous stages, these object detection algorithms are highly non-linear in structure and in the ways they access data. However, strong processing "muscle" is still required in order to evaluate many different features with a rich classification database. Such requirements are ideal for single- and multi-core conventional processors, such as ARM- and Power Architecture-based RISC devices. And this selection criterion is equally applicable for the fourth image processing stage, which tracks detected objects across multiple frames, implements a model of the environment, and assesses whether various situations should trigger actions.
Development environments, frameworks and libraries such as OpenCL (the Open Computing Language), OpenCV (the Open Source Computer Vision Library) and MATLAB can simplify and speed software testing and development, enabling you to evaluate sections of your algorithms on different processing options, and potentially also including the ability to allocate portions of a task across multiple processing cores. Given the data-intensive nature of vision processing, when evaluating processors, you should appraise not only the number of cores and the per-core speed but also each processor's data handling capabilities, such as its external memory bus bandwidth.
Industry Alliance Assistance
With the emergence of increasingly capable processors, image sensors, memories, and other semiconductor devices, along with robust algorithms, it's becoming practical to incorporate computer vision capabilities into a wide range of embedded systems. By "embedded system," we're referring to any microprocessor-based system that isn’t a general-purpose computer. Embedded vision, therefore, refers to the implementation of computer vision technology in embedded systems, mobile devices, special-purpose PCs, and the cloud.
Embedded vision technology has the potential to enable a wide range of electronic products (such as the robotic systems discussed in this article) that are more intelligent and responsive than before, and thus more valuable to users. It can add helpful features to existing products. And it can provide significant new markets for hardware, software and semiconductor manufacturers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower engineers to transform this potential into reality.
Freescale and MathWorks, the co-authors of this article, are members of the Embedded Vision Alliance. First and foremost, the Alliance's mission is to provide engineers with practical education, information, and insights to help them incorporate embedded vision capabilities into new and existing products. To execute this mission, the Alliance has developed a website (www.Embedded-Vision.com) providing tutorial articles, videos, code downloads and a discussion forum staffed by a diversity of technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter (www.embeddedvisioninsights.com), among other benefits.
Also consider attending the Alliance's upcoming Embedded Vision Summit, a free day-long technical educational forum to be held on October 2, 2013 in the Boston, Massachusetts area and intended for engineers interested in incorporating visual intelligence into electronic systems and software. The event agenda includes how-to presentations, seminars, demonstrations, and opportunities to interact with Alliance member companies. The keynote presenter will be Mario Munich, Vice President of Advanced Development at iRobot. Munich's previous company, Evolution Robotics (acquired by iRobot) developed the Mint, a second-generation consumer robot with vision processing capabilities. For more information on the Embedded Vision Summit, including an online registration application form, please visit www.embeddedvisionsummit.com.
Transforming a robotics vision processing idea into a shipping product entails careful discernment and compromise. The Embedded Vision Alliance catalyzes conversations in a forum where tradeoffs can be rapidly understood and resolved, and where the effort to productize advanced robotic systems can therefore be accelerated, enabling system developers to effectively harness various vision technologies. For more information on the Embedded Vision Alliance, including membership details, please visit www.Embedded-Vision.com, email [email protected] or call 925-954-1411.
References:
- Embedded Low Power Vision Computing Platform for Automotive” Michael Staudenmaier, Holger Gryska, Freescale Halbleiter Gmbh, Embedded World Nuremberg Conference, 2013.
Biographies
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance. He is also a Senior Analyst at BDTI (Berkeley Design Technology, Inc.), which provides analysis, advice, and engineering for embedded processing technology and applications, and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. Brian has a B.S. degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years at EDN Magazine.
Yves Legrand is the global vertical marketing director for Industrial Automation and Robotics at Freescale Semiconductor. He is based in France and has spent his professional career between Toulouse and the USA where he worked for Motorola Semiconductor and Freescale in Phoenix and Chicago. His marketing expertise ranges from wireless and consumer semiconductor markets and applications to wireless charging and industrial automation systems. He has a Masters degree in Electrical Engineering from Grenoble INPG in France, as well as a Masters degree in Industrial and System Engineering from San Jose State University, CA.
Bruce Tannenbaum leads the technical marketing team at MathWorks for image processing and computer vision applications. Earlier in his career, he was a product manager at imaging-related semiconductor companies such as SoundVision and Pixel Magic, and developed computer vision and wavelet-based image compression algorithms as an engineer at Sarnoff Corporation (SRI). He holds a BSEE degree from Penn State University and an MSEE degree from the University of Michigan.