This introductory article discusses implementing machine learning algorithms on FPGAs, achieving significant performance improvements at much lower power. Newly available middleware IP, together with the SDAccel programming environment, enables software developers to implement convolutional neural networks (CNNs) in C/C++, leveraging an OpenCL platform model.
Machine Learning in the Cloud: A Tipping Point
The transformation of the data center to cloud computing driven by advances in storage, networking and computing and enabled by virtualization is underway. Simultaneously rapid advances in machine learning which require massive computational resources and the availability of large data sets driven by consumer and IoT devices have created a "tipping point" for machine learning to be applied in a range of applications.
Machine learning is based on algorithms that can learn from data without relying on rules-based programming. It came into its own as a scientific discipline in the late 1990s, as steady advances in digitization and cheap computing power enabled data scientists to stop building finished models and instead train computers to do so. The unmanageable volume and complexity of the big data that the world is now swimming in have increased the potential of machine learning—and the need for it.
In 2007 Fei-Fei Li, the head of Stanford’s Artificial Intelligence Lab, gave up trying to program computers to recognize objects and began labeling the millions of raw images that a child might encounter by age three and feeding them to computers. By being shown thousands and thousands of labeled data sets with instances of, say, a cat, the machine could shape its own rules for deciding whether a particular set of digital pixels was in fact, a cat (Reference 1). In November 2014, Li’s team unveiled a program that identifies the visual elements of any picture with a high degree of accuracy. IBM’s Watson machine relied on a similar self-generated scoring system among hundreds of potential answers to crush the world’s best Jeopardy! players in 2011.
Within the field of machine learning, a class of algorithms called deep learning is generating a lot of interest because of its excellent performance in large datasets. In deep learning, a task can be learned by the machine from a large amount of data either in supervised or unsupervised manner. While large-scale supervised learning has been very successful in tasks like image recognition and speech recognition, unsupervised learning is also becoming an interesting field by identifying patterns in big data.
Since deep learning techniques use a large amount of data for training, the models created as a result of training are also large. This has motivated engineers to move towards specialized hardware like GPUs for training and classification purposes. As the amount of data increases further, machine learning will move to the cloud where large machine learning models would be implemented on CPUs. While GPUs are a better alternative in terms of performance for deep learning algorithms, the prohibitive power requirements have limited the use of GPUs to high performance computing (HPC) clusters. Therefore, there is a dire need for a processing platform that can accelerate algorithms without substantial increase in power consumption. In this context, FPGAs seem to be an ideal choice, with their inherent capability to facilitate launching of a large number of concurrent processes without any substantial increase in power consumption.
In this article, the focus is on implementation of a convolutional neural network (CNN) on a FPGA. A CNN is a class of deep neural networks that has been very successful for large-scale image recognition tasks and other similar machine learning problems. Enabling software developers to "just program" their networks using C/C++ and familiar programming frameworks (CAFFE, Minerva, Theano, Torch, etc.) is now possible through the SDAccel Development Environment and AuvizDNN, a library of functions that implement CNN’s in an optimized manner.
CNNs and AlexNet
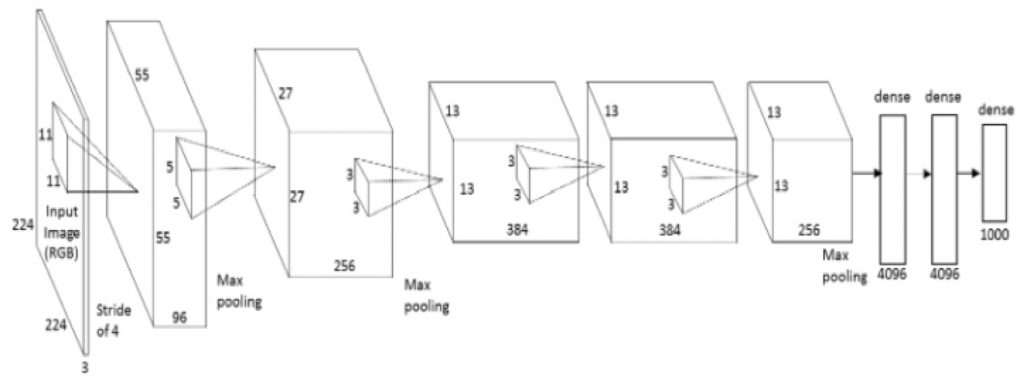
CNNs more generally have been used recently for a variety of recognition tasks. Image recognition, speech recognition, and natural language processing are a few popular applications of CNNs. In 2012, Alex Krishevsky and others from the University of Toronto proposed a deep architecture based on CNNs that won the Imagenet Large Scale Visual Recognition Challenge (Reference 2). The model achieved substantial improvement in recognition in comparison with its competitors as well as models from previous years. Since then, AlexNet has become the benchmark for comparison for all image recognition tasks. AlexNet consists of five convolution layers, followed by three dense layers. Each convolution layer convolves the set of input feature maps with a set of weight filters resulting in a set of output feature maps. The dense layers are fully connected layers, where every output is a function of all the inputs.
The resulting network can handle 1.2 million images and classify them into one of 1000 classes. Implementing AlexNet on a CPU or GPU requires access to a library of functions implemented in C/C++ on an OpenCL kernel. Reconfiguring the network and its parameters (weights, filters, etc.) is done through an API. The CudaDNN library for GPU’s has become the de facto standard for functionality and the API for implementing these networks. AuvizDNN is equivalent to CudaDNN but optimized for FPGA architectures.
Implementing AlexNet on an FPGA provides developers with a compatible library for their GPU based algorithms while delivering lower latency and higher performance per watt. Applications requiring fewer data sets and object classes (i.e. traffic sign recognition) can be readily Implemented using the same library.
Implementation Challenges
Companies like Microsoft and Baidu have published results of their efforts to program FPGAs as accelerators in the Data Center. To date these have been done by hardware developers and programmed in RTL (register transfer language), which requires hardware design expertise and a deep understanding of the FPGA architecture. Just optimizing the system memory bandwidth requires an indepth understanding of the application, the hardware IP (memory controllers, DMA, etc.) and the BSPs (board support packages) provided by the board vendors. Furthermore, the low level of abstraction coupled with slow simulation times means that it can take man months to reprogram the network. Algorithm developers must be able to quickly change the network and its parameters as the training process evolves. Leveraging the programmability of the FPGA is a huge benefit, but a different approach is needed. The rapid adoption of OpenCL and its programming model of leveraging optimized kernels together with SDAccel and AuvizDNN make this possible.
SDAccel: For Software Developers
SDAccelTM is a development environment for OpenCL applications targeting PCIe® based Virtex®-7, and Kintex®-7 FPGA accelerator cards.
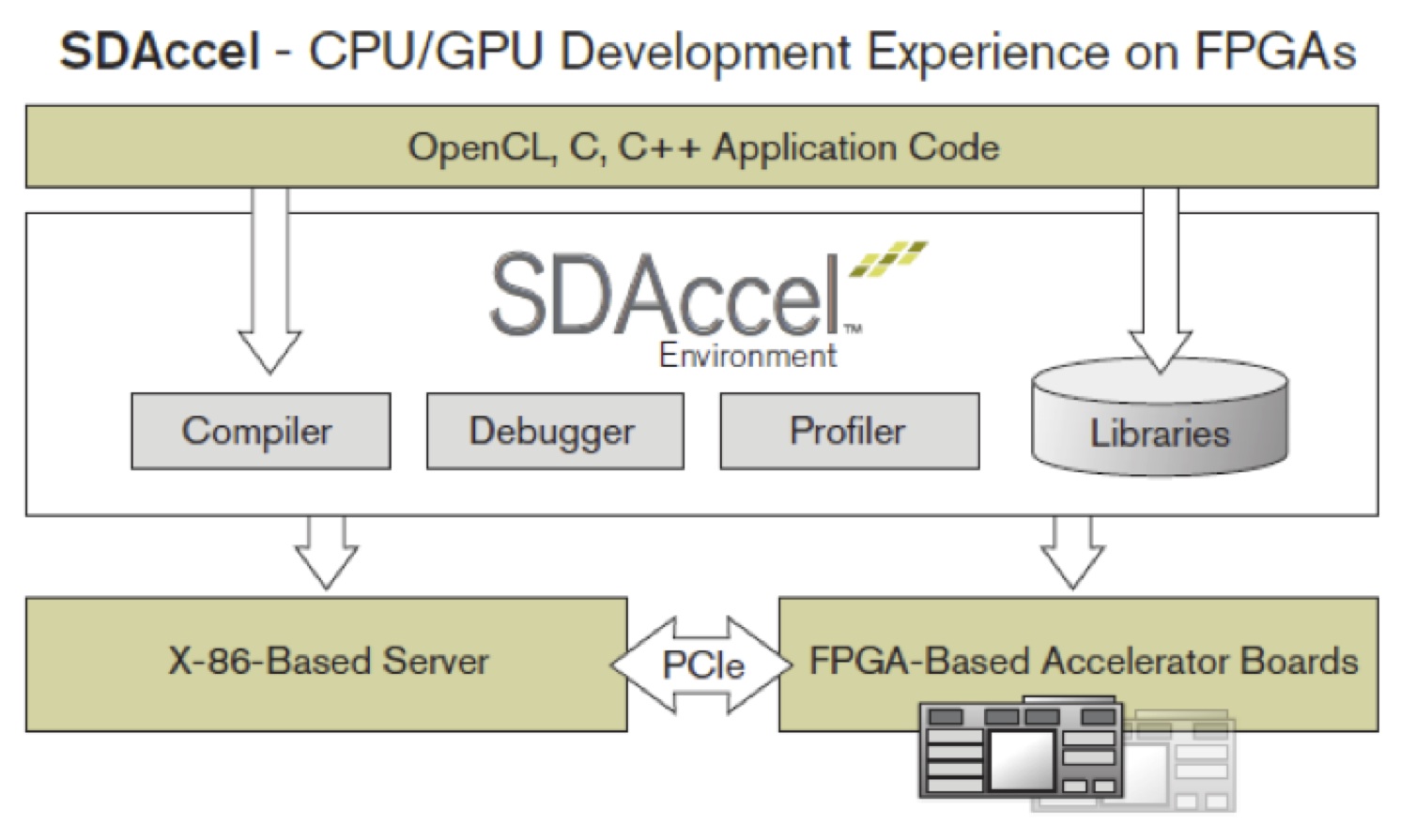
This environment enables concurrent programming of the system processor and the FPGA logic without the need for RTL design experience. The application is captured as a host program written in C/C++ and a set of computation kernels expressed in C, C++, or the OpenCL C language. SDAccel’s architecturally optimizing compiler is capable of building optimized libraries such as AuvizDNN. It provides integration with software frameworks such as CAFFE and AlexNet. It leverages FPGA acceleration platforms from Alpha Data, Micron and Pico Computing. Auviz Systems has recently demonstrated AlexNet running on an Alpha Data board, with development done in SDAccel. Achieving the best optimization from the SDAccel compiler is done best by leveraging optimized libraries like AuvizDNN tuned for SDAccel and the target hardware.
AuvizDNN: A Library for Implementing Convolutional Neural Networks
A more detailed article and presentation is available which discusses AlexNet, CNNs, the math behind them and their optimizations in AuvizDNN. AuvizDNN provides functionality similar to CudaDNN and is optimized for performance and area through the SDAccel Compiler. AuvizDNN was developed by FPGA hardware experts and algorithm developers and makes it easy to replace your existing FPU functions. Creating any CNN using AuvizDNN is a matter of just calling the functions with appropriate parameters. Function calls are made to create each of the convolution layers, followed by the dense layers and finally the softmax layer as shown below.
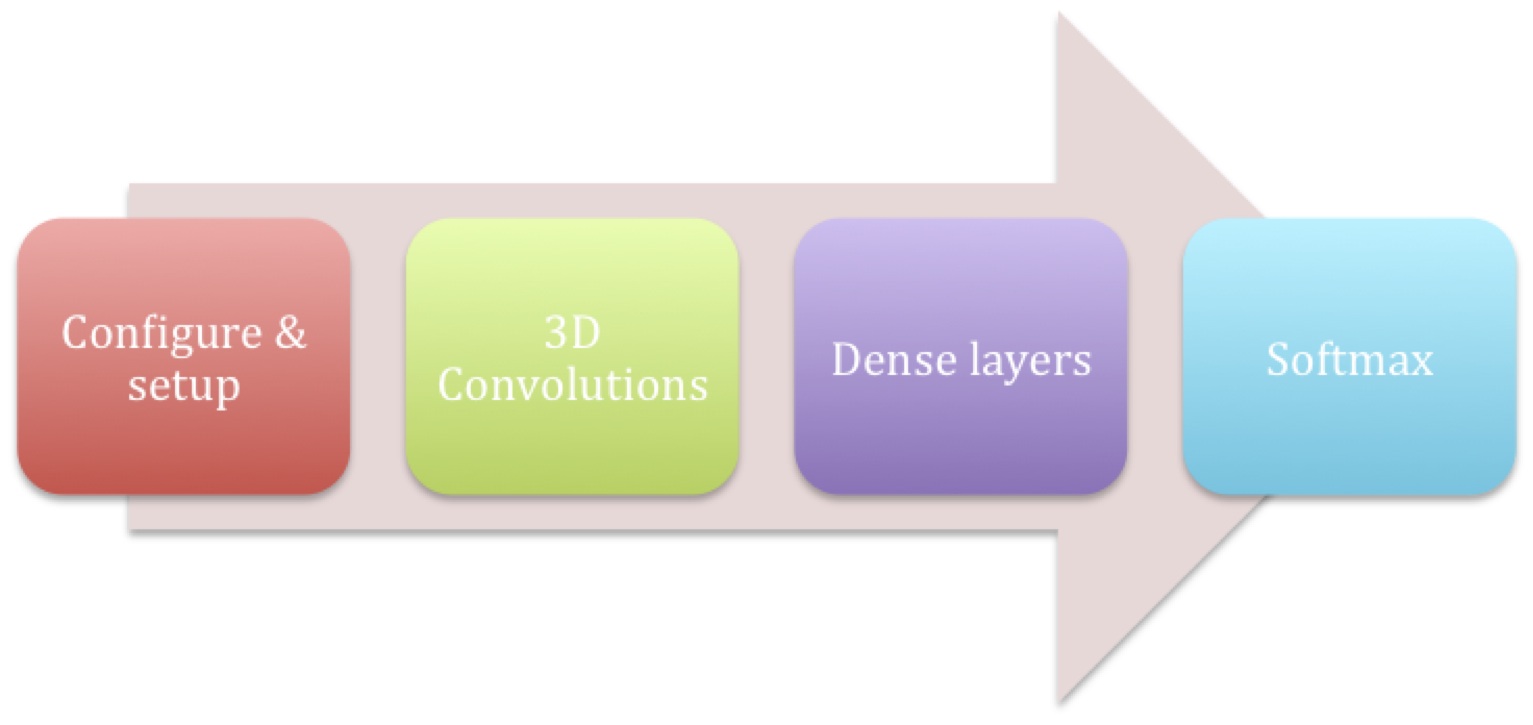
Since AuvizDNN provides all the required objects, classes, and functions to implement CNNs, the user just needs to supply the required parameters to create different layers. For example, the code snippet below shows how the first layer in AlexNet can be created.
Performance
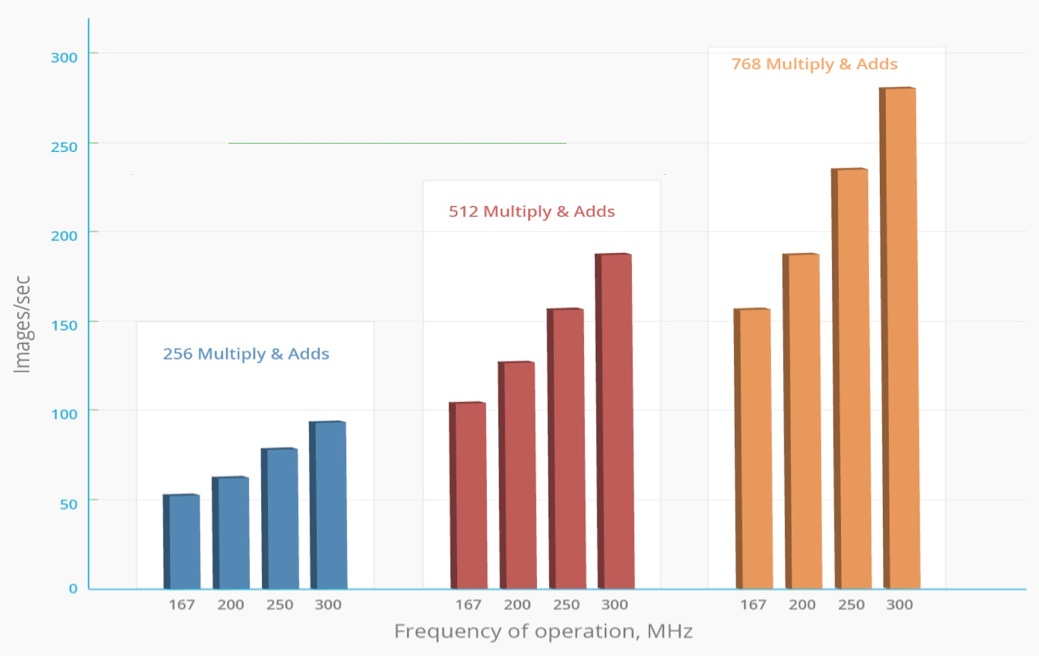
FPGAs have a large number of LUTs (look up tables), DSP blocks, and on-chip memory, which make them a good choice to implement very deep CNNs. More important than the actual performance is performance/watt in the context of data centers. Data centers require high performance but at a power profile that is within the limits of data center server requirements.
FPGAs such as Xilinx Kintex Ultrascale can provide greater than 14 images/sec/watt results, making them a great choice for data center applications. The Figure below provides an idea of the achievable performance with different classes of FPGAs

Summary
It’s clear that machine learning i.e. deep learning is poised to surge as a differentiating technology in a wide range of applications. Furthermore, the competitive significance of new business models turbocharged by machine learning will be disruptive. In fact, management author Ram Charan suggests that "any organization that is not a math house now or is unable to become one soon is already a legacy company" (Reference 3).
To achieve the highest performance in the data center, companies are turning to FPGA acceleration. Software tools like SDAccel and AuvizDNN provide a great platform to get started and to learn how to implement machine learning. SDAccel offers a viable path to implementation for software developers, and AuvizDNN libraries abstract hardware specific coding styles and tool. Auviz can also provide additional optimizations and customization on specific algorithms allowing algorithm developers to focus on their application.
References
- Fei-Fei LI, “How We’re Teaching Computers to Understand Pictures,” TED, March 2015, www.ted.com
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet Classification with Deep Convolutional Neural Networks," Advances in Neural Information Processing Systems, 2012.
- Ram Charan, "The Attacker’s Advantage: Turning Uncertainty Into Breakthrough Opportunities," New York: PublicAffairs, February 2015
By Vin Ratford
Co-Founder, Auviz Systems
Executive Director, Embedded Vision Alliance