OpenCL™, a maturing set of programming languages and APIs from the Khronos Group, enables software developers to efficiently harness the profusion of diverse processing resources in modern SoCs, in an abundance of applications including embedded vision.
Computer scientists describe computer vision, the use of digital processing and intelligent algorithms to interpret meaning from still and video images, as a class of applications that is "embarrassingly parallel." This is because significant portions of typical vision applications can be partitioned to run in parallel. As computer vision finds increasing use in a wide range of applications, exploiting parallel processing has become an important technique for obtaining cost-effective and energy-efficient real-time implementations of vision algorithms.
Historically, this efficient leverage of available processor resources was an extremely challenging engineering exercise, especially for software developers aspiring to create a single code base intended to run on a variety of system implementations. Looking first at CPUs, three primary architectures (ARM, MIPS, and x86) now exist in the market, along with a host of secondary alternatives. Each of these architectures comes in multiple generations' worth of core implementation forms, with varying instruction sets, features, and performance capabilities. And modern SoCs now commonly offer multiple (and varying) CPU core counts, even going so far as to combine multiple CPU architectures on a single chip.
These same SoCs, and the systems containing them, also comprise a constellation of coprocessors potentially well suited to accelerate vision processing, typically including a graphics processing unit (GPU), digital signal processor (DSP), and function-specific accelerators (Figure 1). The diversity of coprocessor architectures creates a further dilemma for vision application developers; the types of tasks they need to perform are often just the types of tasks that such coprocessors are designed to execute efficiently. But hundreds of different SoCs exist, along with countless variations of systems, each with a different complement of CPUs and coprocessors. A deeply embedded system may be able to focus on a single hardware platform implementation, although the ability to re-use existing code in a divergent next-generation design is still appealing. But an application developer targeting PCs, smartphones and/or tablets, for example, cannot ignore the multiplicity of both CPUs and coprocessors that exist in the target market.
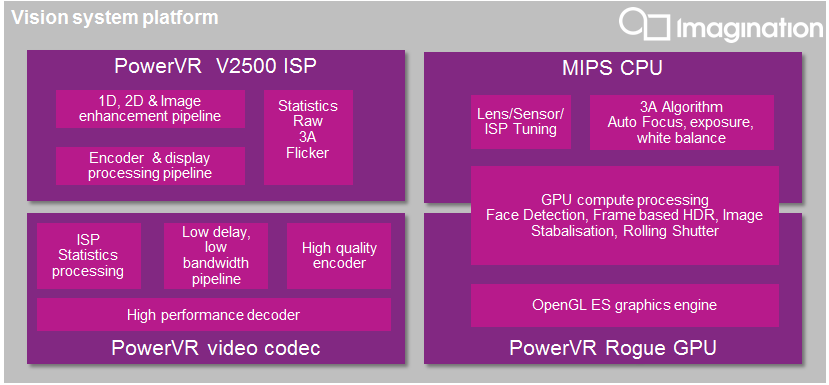
Figure 1. Modern SoCs contain a diversity of primary and coprocessor cores, all potential candidates for running portions of vision algorithms.
It should be possible to create application programming interfaces (APIs) that abstract the details of the parallel processing resources included in a specific system. This would enable a software developer to write an application once and have it run in many different systems, harnessing whatever parallel processing resources are available in each case. In practice, however, such APIs have historically been mostly missing, or have been too hardware implementation-focused for widespread and longstanding adoption. These limitations have been a key impediment to large numbers of developers making full use of the available acceleration resources inside systems.
OpenCL Overview
Fortunately, this situation is beginning to change with the emergence of OpenCL, an open standard created and maintained by the not-for-profit Khronos Group industry consortium. OpenCL has emerged as a promising solution to the needs of developers across a broad range of applications. Unlike application-domain-specific APIs such as the graphics-focused OpenGL® and DirectX, OpenCL is a set of programming languages and APIs for heterogeneous parallel programming that can be used for any application that is parallelizable.
OpenCL was originally developed to enable personal computer application developers to harness the massive parallel computing power of systems with multiple CPU cores and modern GPUs, the latter when used for tasks other than rendering 3D graphics. This concept, often called “GPU computing” or “general-purpose GPU (GPGPU),” was pioneered by AMD with its Stream API and NVIDIA with its CUDA technology. But both of those APIs are proprietary and run only on the specific manufacturers' chips.
OpenCL, in contrast, can be enabled by any GPU supplier that chooses to do so. It has been embraced not only by traditional desktop and laptop GPU suppliers such as AMD, Intel and NVIDIA, but also by mobile graphics technology developers like ARM, Imagination Technologies, Qualcomm, and Vivante. While the GPUs found in mobile application processors may not match the processing power of desktop GPUs, they are nevertheless powerful, as well as energy-efficient.
In addition to its applicability to a wide range of applications, and to its broad support among silicon providers, OpenCL has another important attribute: it is not architecture-specific. Though originally targeted at heterogeneous systems with CPUs and GPUs, OpenCL can be supported on a variety of parallel processing architectures, including FPGAs, DSPs, and dedicated vision processors. This could not come at a better time for embedded vision applications. (We use the term "embedded vision" to refer to the practical implementation of computer vision in mobile devices, PCs, embedded systems and the cloud.)
The emergence of very powerful, low-cost, and energy-efficient processors is spurring the rapid proliferation of embedded vision in applications like augmented reality, automotive safety and security. These applications have extremely diverse requirements; for example, some do all or most of their processing in the cloud, while others do all of their processing locally, under severe power consumption constraints. Given this diversity, it shouldn’t be surprising that many types of processors are being used for embedded vision. And particularly in the nascent days of a new application area, it’s difficult to know which processor (or mix of processors) will ultimately be most effective. So, having the flexibility OpenCL provides to migrate parallelized software from one processor type to another, without having to start over each time, can be extremely valuable.
Admittedly, OpenCL isn't a one-for-all panacea for vision applications, at least not yet. For example, not every vision algorithm (either in part or in entirety) is a viable candidate for parallelization acceleration on a GPU, FPGA, DSP or vision processor. Google's Android is one notable example of an operating system that currently doesn't directly support OpenCL; it instead supports Renderscript, although many silicon vendors are adding OpenCL support to Android systems. OpenCL's relative immaturity versus API alternatives or more general traditional software development practices on CPUs translates into non-uniform quality of tool chains, drivers and other development resources for various platforms; programming practices that work well with one OpenCL compiler may not work so well with another.
Some tradeoff between code portability and performance is still inevitable; creating an optimally efficient OpenCL implementation requires knowledge of specific hardware details such as amount of local storage and SIMD width, and may also require the use of platform-specific extensions. But over time, many of these lingering issues will continue to be addressed; note, for example that C++ programming techniques are available in the latest version of OpenCL.
GPU Acceleration
Take a look at the modern SoCs inside desktop and mobile computers, smartphones and tablets, all driving high-definition displays with 3D visual computing, and you’ll discover that almost half of the die area is allocated to the GPU and its memory subsystem. Why not take advantage of all the parallel computing hardware in the integrated GPU for vision processing algorithm acceleration, when GPU compute units are not needed for 3D rendering? Many vision application developers may not yet use OpenCL directly, but still already benefit from a middleware engine, API or computer vision function library that uses OpenCL to harness platform acceleration.
For example, the popular OpenCV (open-source computer vision) library and the OpenVX™ vision processing API (also maintained by the Khronos Group) can both use OpenCL to accelerate vision functions. The latest version of OpenCV delivers transparent GPU acceleration capabilities; at runtime, if OpenCL support is available and enabled, OpenCV 3.0 will use OpenCL by default for OpenCV algorithms with an OpenCL implementation (which is very often the case with the imgproc module, for example). OpenCV library users, by simply declaring their variables as the UMat type, can reap the benefits of transparent acceleration that works on all OpenCL-supported platforms, including both integrated and discrete GPUs. Since the OpenCL runtime is loaded dynamically, programmers need only build their code only once for each operating system configuration. The runtime is also independent of which IDE is used to compile the “host” code.
Measuring the benefit of GPU acceleration in OpenCV is straightforward, since a vision processing application can disable OpenCL simply by changing an environment variable. With OpenCL disabled, the OpenCV libraries will instead use the native versions of their algorithms, running solely on the CPU. As Figure 2 illustrates, almost every OpenCV kernel in the imgageproc module can run substantially faster (an average of 3.5x, and up to 17x) by tapping into the parallel processing horsepower provided by the GPU. These particular tests employed an OpenCL 1.2 runtime driver on 64-bit Windows 7. With more recent versions of OpenCL and additional performance optimization, the GPU speedup could be even higher than what is shown.
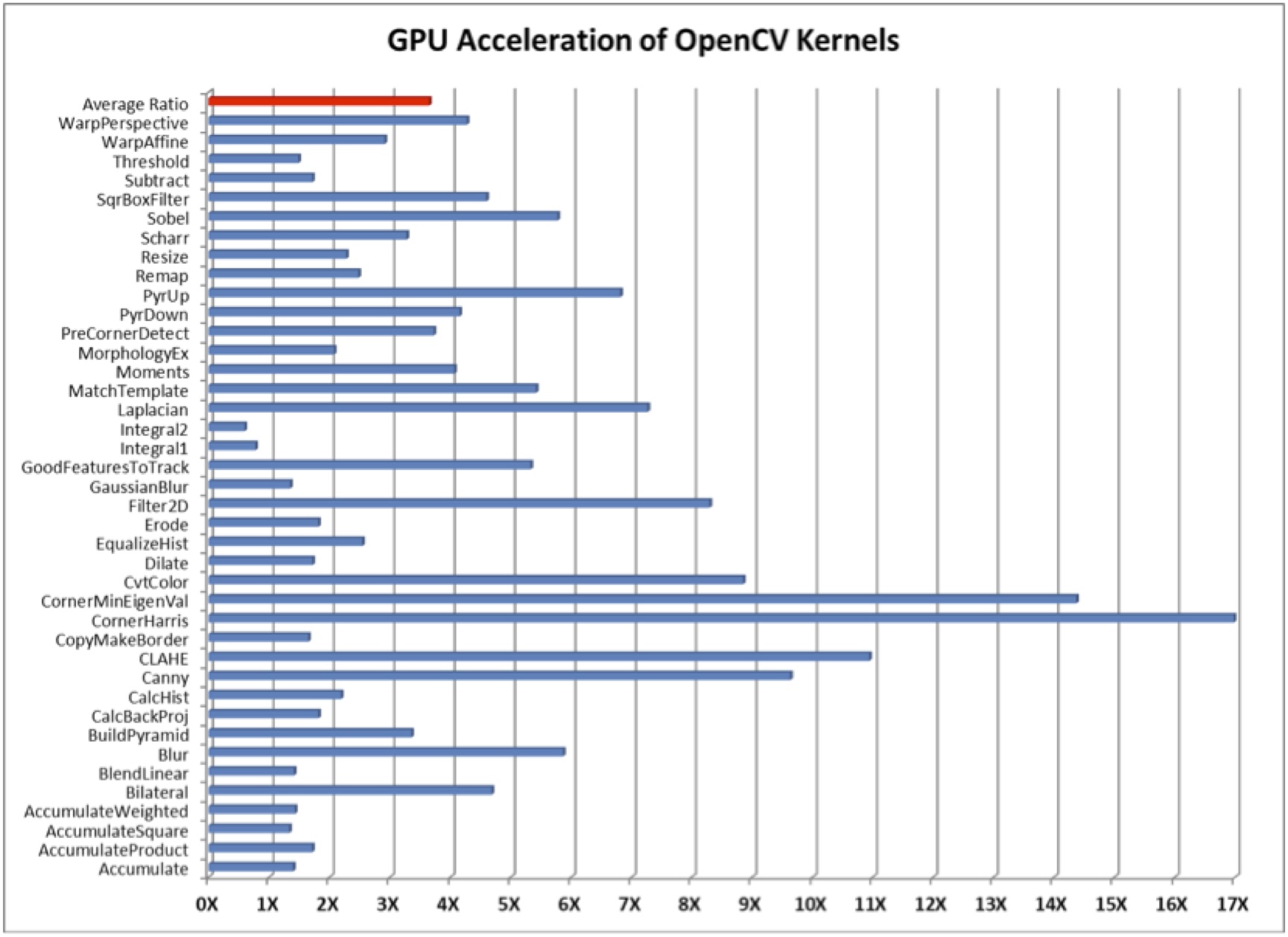
Figure 2. GPU acceleration of OpenCV 3.0 uses a 35W AMD embedded APU, the RX-427BB with 8 OpenCL compute units, and an OpenCL 1.2 runtime driver on 64-bit Windows 7.
FPGA Acceleration
FPGAs offer highly parallel "fabric" architectures that are also programmable, making them feasible options for vision algorithm acceleration. Since it's possible to stream data directly into, between, and out of one or multiple FPGAs without the need for host-side caching or other interaction, memory requirements and latency are reduced, and scalability and overall bandwidth are increased versus alternative implementations that require such interaction (Figure 3). Modern FPGAs also optionally offer multiple on-die processor cores; this increased integration further improves performance, lowers latency, and reduces power consumption versus the use of a discrete CPU, while maintaining cache coherency between the host and accelerator.
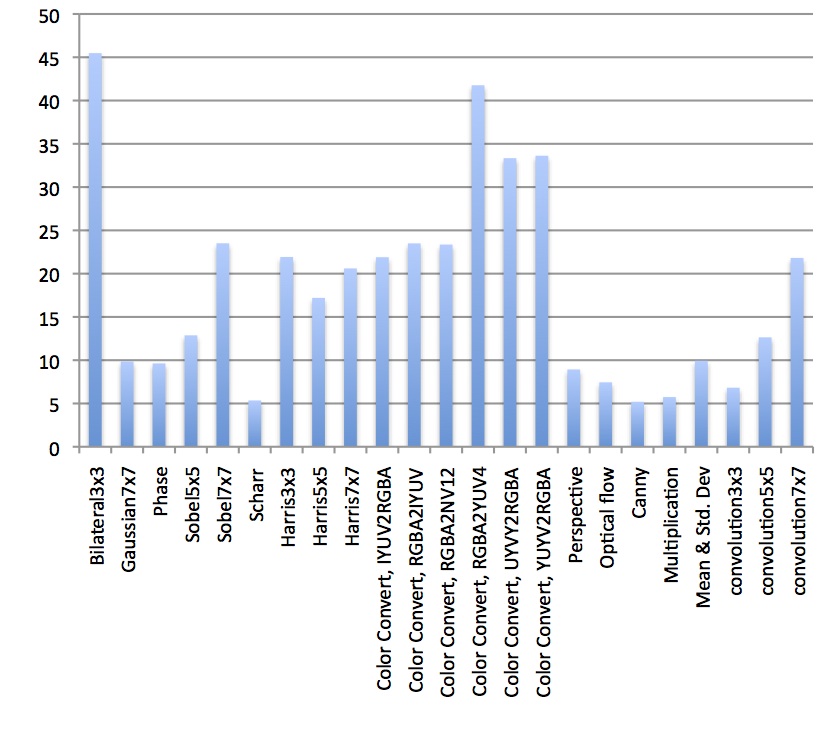
Figure 3. FPGA acceleration of various vision functions uses a Xilinx Virtex-7 690T in combination with Auviz Systems' AuvizCX library, as compared to an Intel i7-4770 CPU.
Consider, for example, the need to keep up with the ever-increasing data rates generated by ever-higher resolution image sensors in computer vision applications. This trend is driving the migration from centralized to "edge" processing, as close as possible to the sensor source, for (at minimum) image enhancement and other pre-processing functions, such as using convolutional neural networking to perform object detection and recognition. FPGAs, particularly with embedded processor cores, are platforms being increasingly adopted for implementing such "edge" processing. OpenCL simplifies the functional partitioning of the total vision algorithm chain between these programmable logic devices and other available system processing resources. And FPGA suppliers are even now delivering full OpenCL-based and application-tailored "environments" to accelerate development time and increase ease of use.
Middleware offerings can fill any gaps in the OpenCL-aware vision algorithm libraries already available from FPGA suppliers, as an alternative to developing such code yourself. Auviz Systems' AuvixCV library, for example, leverages OpenCL and currently supports approximately 40 of the most commonly used OpenCV and OpenVX functions, with more under development. Users can select either area- or performance-optimized versions of each function and can also call multiple functions sequentially, streaming data from one to another in building up the image pipeline, and reducing latency by minimizing memory transfers between the FPGA and CPU.
DSPs, Vision Processors, and a System-on-Chip Perspective
The typical modern SoC encapsulates the essence of heterogeneous computing: multi-core CPUs (in some cases a mix of high-performance and energy-efficiency tuned cores), GPUs, DSPs, and processors and fixed-function logic blocks for vision and other functions. A vision processor core, for example, typically delivers optimum performance, power consumption, and silicon area efficiency results, but only for the specific use cases for which it is designed. A DSP core, being multimedia-tailored but not vision-specific, provides an intermediary efficiency-vs-flexibility alternative to a CPU or vision processor. A blend of such processor architectures, when combined on a single chip, provides a complete computational platform. Modern computational frameworks such as OpenCL aim to provide a unified, accessible and portable approach to parallel programming of such heterogeneous architectures: a single runtime, language and API framework to program the whole system.
Dynamically choosing the best processor for the task at hand is often essential to enable efficient resource usage across the entire system. Computer vision algorithms are typically comprised of complex multistage operation pipelines (pre-processing, feature extraction, object classification, object tracking, etc.), and a framework such as OpenCL enables optimal distribution of such tasks across the multiple processors available in the system. In some cases, offload from the CPU may be used to improve execution performance ("I can detect an object faster"). In other cases, offload may be more energy efficient ("I can detect an object while draining the battery less"). There may also be situations where all of the CPU's processing capabilities are required for other tasks, making it necessary to migrate vision-related workloads to another processor to avoid CPU overload ("I can do other things on the CPU while the object is being detected on the GPU").
Another benefit of offloading vision tasks from the CPU is the ability to carry out more total computations within the same time, thermal and/or energy budget. Doing so can help improve the quality of results ("I can detect more objects, or I can be more accurate at detecting the same number of objects"). In one case study, for example, developers were able to improve the poor-light detection accuracy and other robustness measures of their gesture interface vision middleware by harnessing OpenCL-enabled CPU-plus-GPU processing. The same principle can be applied to a variety of other applications.
Sometimes computer vision applications overwhelm the computational capability of the CPU and, unless GPU-based or other acceleration is harnessed, would only be able to be implemented in a non-real-time fashion. Video stabilization, for example, leverages the same principles as the motion vectors found in media codecs with optical flow for motion analysis. By using OpenCL to tap into additional system processors, such applications can be deployed in real time ("I can detect faces in the live video stream, discern each person's gender and apply a chain of filters to improve various image aspects via dynamic parameter fine-tuning").
Latest OpenCL Developments
The OpenCL standard continues to evolve, to meet industry and developer needs. In March, Khronos announced the ratification and public release of the OpenCL 2.1 provisional specification. OpenCL 2.1 is a significant evolutionary step for the specification, as it defines a new kernel language based on a subset of C++14 for significantly enhanced programmer productivity, re-usable optimized libraries and performance portability. OpenCL 2.1 also supports the new Khronos SPIR-V™ intermediate language, which eliminates the need for a built-in high-level language source compiler to significantly reduce driver complexity.
SPIR-V will enable a diversity of front-ends, including image and vision processing domain-specific languages and frameworks. Additionally, a standardized intermediate language provides kernel IP protection and accelerated kernel load times, and enables developers to use a common language front-end across multiple implementations, improving kernel reliability and portability. The provisional release of the OpenCL 2.1 specification enables developers and implementers to provide feedback at the OpenCL forums prior to specification finalization.
Developer Assistance
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products. And it can provide significant new markets for hardware, software and semiconductor suppliers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform this potential into reality. Altera, AMD, ARM, Auviz Systems, BDTI, Imagination Technologies, NVIDIA and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance.
First and foremost, the Alliance's mission is to provide product creators with practical education, information, and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV. Access is free to all through a simple registration process.
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2014, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Alliance website. The next Embedded Vision Summit will take place on May 12, 2015 in Santa Clara, California; accompanying half- and full-day workshops will occur on May 11 and May 13. Please reserve a spot on your calendar and plan to attend. Online registration and additional Embedded Vision Summit information are available on the Alliance website.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Jeff Bier
Founder, Embedded Vision Alliance
Co-Founder and President, BDTI
Bill Jenkins
Product Marketing Lead for Advanced Programming Languages, Altera
Harris Gasparakis
OpenCV Manager, AMD
Roberto Mijat
Visual Computing Marketing Manager, ARM
Nagesh Gupta
CEO and Founder, Auviz Systems
Peter McGuinness
Director of Multimedia Technology Marketing, Imagination Technologies
Neil Trevett
Vice President of Mobile Ecosystems, NVIDIA
President, Khronos Group
Dan Isaacs
Director of Corporate Strategy, Xilinx
Vinay Singh
Senior Product Marketing Manager, SDAccel Development Environment for OpenCL, C and C++, Xilinx
OpenCL is a trademark of Apple Inc. used by permission by the Khronos Group. OpenVX and SPIR are trademarks of the Khronos Group. OpenGL is a trademark or registered trademark of Silicon Graphics, Inc. in the United States and other countries.