An ISP (image signal processor) in combination with one or several vision processors can collaboratively deliver more robust computer vision processing capabilities than vision processing is capable of providing standalone. However, an ISP operating in a computer vision-optimized configuration may differ from one functioning under the historical assumption that its outputs would be intended for human viewing purposes. How can such a functional shift be accomplished, as well as handling applications in which both computer vision and human viewing functions require support? This article discusses the implementation options involved in heterogeneously leveraging an ISP and one or more vision processors to efficiently and effectively execute both traditional and deep learning-based computer vision algorithms.
ISPs, whether in the form of a standalone IC or as an IP core integrated into a SoC or image sensor, are common in modern camera-inclusive designs (see sidebar “ISP Fundamentals“). And vision processors, whether to handle traditional- or deep learning-based algorithms, or a combination of the two, are increasingly common as well, as computer vision adoption becomes widespread. Sub-dividing the overall processing of computer vision functions among the collaborative combination of an ISP and vision processor(s) is conceptually appealing from the standpoint of making cost-effective and otherwise efficient use of all available computing resources.
However, ISPs are historically “tuned” to process images intended for subsequent human viewing purposes; as such, some ISP capabilities are unnecessary in a computer vision application, while others are redundant with their vision processor-based counterparts and the use of others may actually be detrimental to the desired computer vision accuracy and other end results. The situation is complicated even further in applications where an ISP’s outputs are used for both human viewing and computer vision processing (see sidebar “Assessing ISP Necessity“).
This article discusses the implementation options involved in combining an ISP and one or more vision processors to efficiently and effectively execute traditional and/or deep learning-based computer vision algorithms. It also discusses how to implement a design that handles both computer vision and human viewing functional requirements. It provides both general concept recommendations and detailed specific explanations, the latter in the form of case study examples. And it also introduces readers to an industry alliance created to help product creators incorporate vision-enabled capabilities into their SoCs, systems and software applications, along with outlining the technical resources that this alliance provides (see sidebar “Additional Developer Assistance“).
Dynamic Range Compression Effects on Edge Detection
The following section from Apical Limited (now owned by Arm, who is subsequently implementing Apical’s ISP technologies in its own IP cores), explores the sometimes-undesirable interaction between an ISP and traditional computer vision functions, as well as providing suggestions on how to resolve issues encountered.
In general, the requirements of an ISP to produce natural, visually accurate imagery and the desire to produce well-purposed imagery for computer vision are closely matched. However, it can be challenging to maintain accuracy in uncontrolled environments. Also, in some cases the nature of the image processing applied in-camera can have an unintended and significant detrimental effect on the effectiveness of embedded vision algorithms, since the data represented by a standard camera output is very different from the raw data recorded by the camera sensor. Therefore, it’s important to understand how the pixels input to the vision algorithms have already been pre-processed by the ISP, since this pre-processing may impact the performance of those algorithms in real-life situations.
The following case study will illustrate a specific instance of these impacts. Specifically, we’ll look at how DRC (dynamic range compression), a key processing stage in all cameras, affects the performance of a simple threshold-based edge detection algorithm. DRC, as explained in more detail in the sidebar “ISP Fundamentals“, is the process by which an image with high dynamic range is mapped into an image with lower dynamic range. Most real-world situations exhibit scenes with a dynamic range of up to ~100 dB, and the eye can resolve details up to ~150 dB. Sensors exist which can capture this range (or more), which equates to around 17-18 bits per color per pixel. Standard sensors capture around 70 dB, which corresponds to around 12 bits per color per pixel.
We would like to use as much information about the scene as possible for embedded vision analysis purposes, which implies that we should use as many bits as possible as input data. One possibility is just to take this raw sensor data in as-is in linear form. Often, however, the raw data isn’t available, since the camera module may be separate from the computer vision processor, with the communication channel between them subsequently limited to 8 bits per color per pixel. Some kinds of vision algorithms also work better if presented with images exhibiting a narrower dynamic range since, as a result, less variation in scene illumination needs to be taken into account.
Often, therefore, some kind of DRC will be performed between the raw sensor data (which may in some cases be very high dynamic range) and the standard RGB or YUV output provided by the camera module. This DRC will necessarily be non-linear; one familiar example of the technique is gamma correction, which is more correctly described as dynamic range preservation. The intention is to match the gamma applied in-camera with an inverse function applied at the display, in order to recover a linear image at the output (as in, for example, the sRGB or rec709 standards for mapping 10-bit linear data into 8-bit transmission formats).
The same kind of correction is also frequently used for DRC. For the purposes of this vision algorithm example, it’s optimal to work in a linear domain, and in principle, it would be straightforward to apply an inverse gamma and recover the linear image as input. Unfortunately, though, the gamma used in the camera does not always follow a known standard. This is for good reason; the higher the dynamic range potential of a sensor, the larger the amount of non-linear correction that needs to be applied to those images captured by the sensor that exhibit high dynamic range. Conversely, for images captured by the sensor that don’t fit the criteria i.e., images of scenes that are fairly uniform in illumination, little or no correction needs to be applied.
As a result, the non-linear correction needs to be adaptive. This means that the algorithm’s function depends on the image itself, as derived from an analysis of the intensity histogram of the component pixels, and it may need also to be spatially varying, meaning that different transforms are applied in different image regions. The overall intent is to try to preserve as much information as accurately as possible, without clipping or distortion of the content, and while mapping the high input dynamic range down to the relatively low output dynamic range. Figure 1 gives an example of what DRC can achieve; the left-hand image retains the contrast of the original linear sensor image, while the right-hand post-DRC image is much closer to what the eye and brain would perceive.
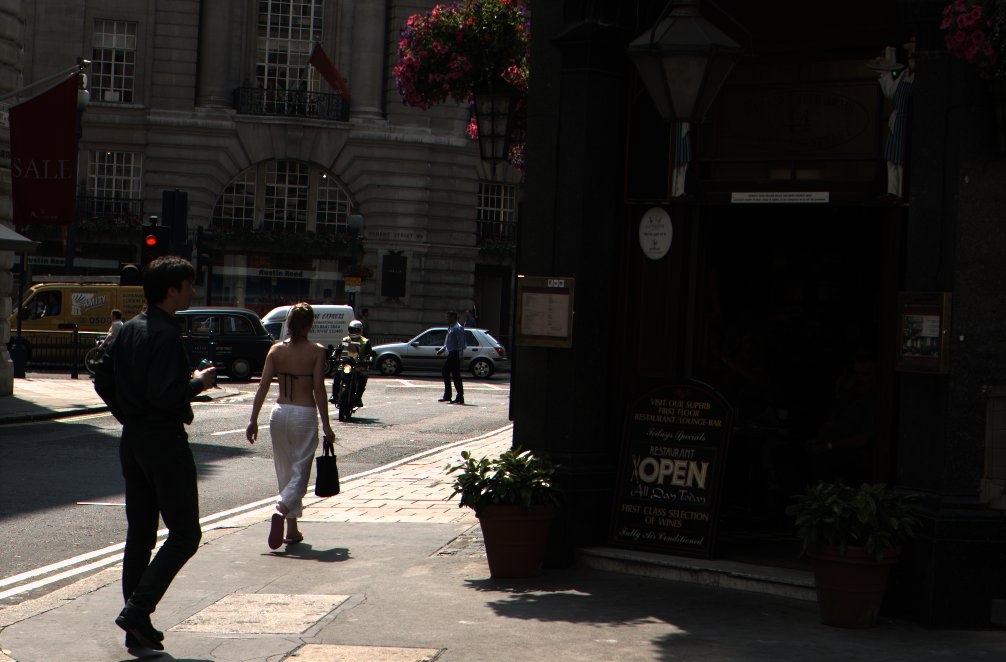 |
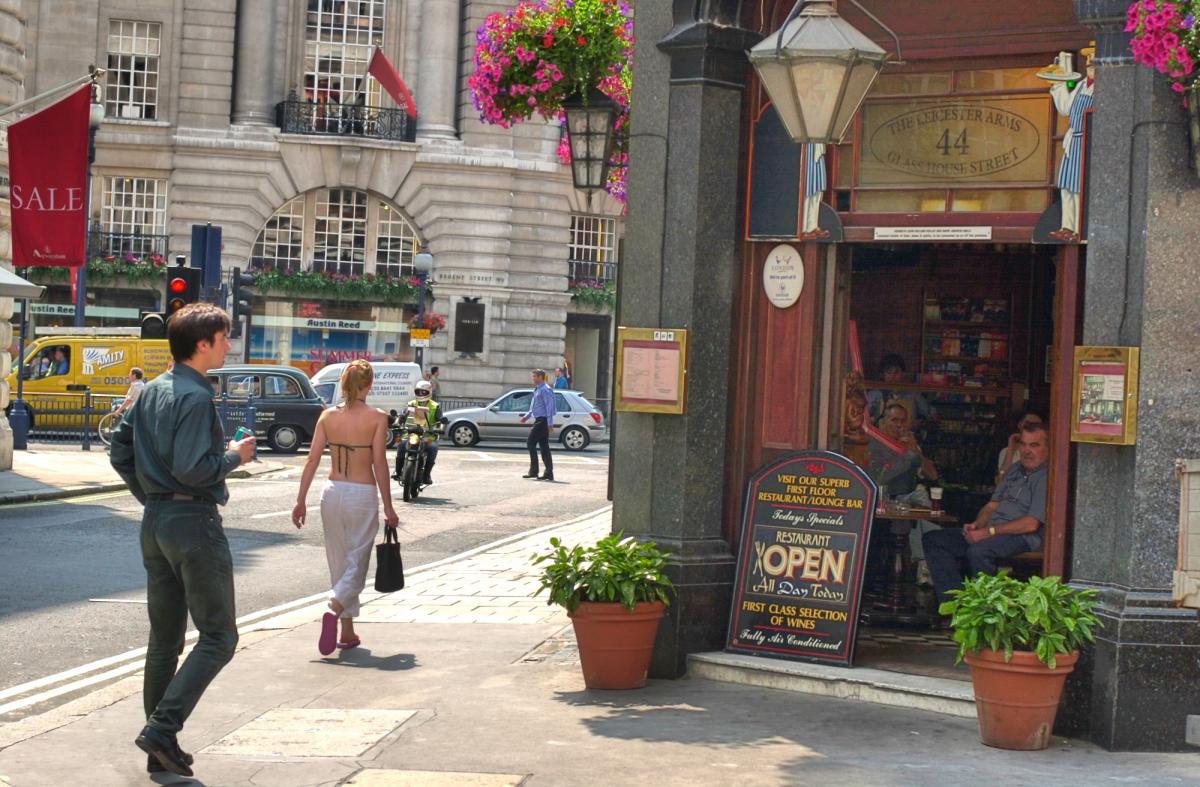 |
Figure 1. An original linear image (left) transforms, after dynamic range compression, into a visual representation much closer to what the eye and brain would perceive (right) (courtesy Apical).
Now let’s envision working with this same sort of non-linear image data as input to a vision algorithm, a normal situation in many real-world applications. How will the edge detection algorithm perform on this type of data, as compared to the original linear data? Consider a very simple edge detection algorithm, based on the ratio of intensities of neighboring pixels, such that an edge is detected if the ratio is above a pre-defined threshold. Also consider the simplest form of DRC, which is gamma-like, and might be associated with a fixed exponent or one derived from histogram analysis (i.e., “adaptive gamma”). What effect will this gamma function have on the edge intensity ratios?
The gamma function is shown in Figure 2 at top right. Here, the horizontal axis is the pixel intensity in the original image, while the vertical axis is the pixel intensity after gamma correction. This function increases the intensity of pixels in a variable manner, such that darker pixels have their intensities increased more than do brighter pixels. Figure 2 at top left shows an edge, with its pixel intensity profile along the adjacent horizontal line. This image is linear; it has been obtained from the original raw data without any non-linear intensity correction. The edge corresponds to a dip in the intensity profile; assume that this dip exceeds the edge detection threshold by a small amount.
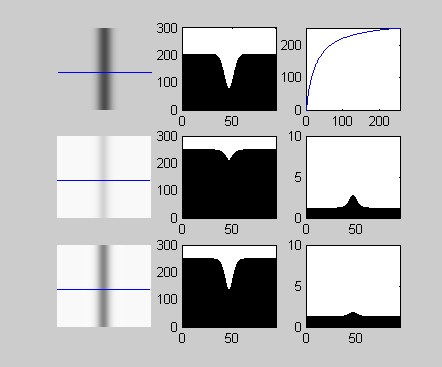
Figure 2. DRC has variable effects on an edge depending on the specifics of its implementation. The original edge is shown in the top-left corner, with the gamma-corrected result immediately below it. The intensity profile along the blue horizontal line is shown in the middle column. The result of gamma correction is shown in the middle row, with the subsequent outcome of applied local contrast preservation correction shown in the bottom row (courtesy Apical).
Now consider the same image after gamma correction (top right) as shown in Figure 2, middle row. The intensity profile has been smoothed out, with the amplitude of the dip greatly reduced. The image itself is brighter, but the contrast ratio is lower. The reason? The pixels at the bottom of the dip are darker than the rest, and their intensities are therefore relatively increased more by the gamma curve than the rest, thereby closing the gap. The difference between the original and new edge profiles is shown in the right column. The dip is now well below our original edge detection threshold.
This outcome is problematic for edge detection, since the strengths of the edges present in the original raw image are reduced in the corrected image. Even worse, they’re reduced in a totally unpredictable way based on where the edge occurs in the intensity distribution. Making the transform image-adaptive and spatially variant further increases the unpredictability of how much edges will be smeared out by the transform. There is simply no way to relate the strength of edges in the output to those in the original linear sensor data. On the one hand, DRC is necessary to pack information recorded by the sensor into a form that the camera can output. However, this very same process also degrades important local pixel information needed for reliable edge detection. Such degradation could, for example, manifest as instability in the white line detection algorithm for an automotive vision system, particularly when entering or exiting a tunnel, or in other cases where the scene’s dynamic range changes rapidly and dramatically.
Fortunately, a remedy exists. The fix arises from an observation that an ideal DRC algorithm should be highly non-linear on large length scales on the order of the image dimensions, but should be strictly linear on very short scales of a few pixels. In fact this outcome is also desirable for other reasons. Let’s see how it can be accomplished, and what effect it would have on the edge problem. The technique involves deriving a pixel-dependent image gain via the formula Aij = Oij/D(Iij), where i,j are the pixel coordinates, O denotes the output image and I the input image, and D is a filter applied to the input image which acts to increase the width of edges. The so-called amplification map, A, is post-processed by a blurring filter which alters the gain for a particular pixel based on an average over its nearest neighbors. This modified gain map is multiplied with the original image to produce the new output image. The result is that the ratio in intensities between neighboring pixels is precisely preserved, independent of the overall shape of the non-linear transform applied to the whole image.
The result is shown in the bottom row of Figure 2. Although the line is brighter, its contrast with respect to its neighbors is preserved. We can see this more clearly in the image portion example of Figure 3. Here, several edges are present within the text. The result of standard gamma correction is to reduce local contrast, thereby “flattening” the image, while the effect of the local contrast preservation algorithm is to lock the ratio of edge intensities, such that the dips in the intensity profile representing the dark lines within the two letters in the bottom image and the top image are identical.
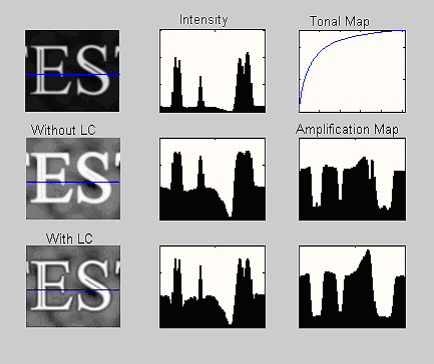
Figure 3. Showing a portion of an image makes the DRC effects even more evident. The original linear image is in the top-left corner, with the gamma-corrected result immediately below it. The effect of local contrast preservation is shown in the bottom-left corner (courtesy Apical).
In summary, while non-linear image contrast correction is essential for forming images that are viewable and transmissible, such transforms should retain linearity on small scales important for edge analysis. Note that our earlier definition of the amplification map as a pixel position-dependent quantity implies that such transforms must be local rather than global (i.e., position-independent). It is worth noting that unfortunately, the vast majority of cameras in the market employ only global processing and therefore have no means of controlling the relationship between edges in the original linear sensor data and the camera output.
Michael Tusch
Founder and CEO
Apical Limited
Software Integration of ISP Functions into a Vision Processor
An ISP’s pre-processing impacts the effectiveness of not only traditional but also emerging deep learning-based computer vision algorithms. And, as vision processors become increasingly powerful and otherwise capable, it’s increasingly feasible to integrate image signal processing functions into them versus continuing to rely on a standalone image signal processor. The following section from Synopsys covers both of these topics, in the process showcasing the capabilities of the OpenVX open standard for developing high-performance computer vision applications portable to a wide variety of computing platforms.
CNNs (convolutional neural networks) are of late receiving a lot of justified attention as a state-of-the-art technique for implementing computer vision tasks such as object detection and recognition. With applications such as mobile phones, autonomous vehicles and augmented reality devices, for example, requiring vision processing, a dedicated vision processor with a CNN accelerator can maximize performance while minimizing power consumption. However, the quality of the images fed into the CNN engine or accelerator can heavily influence the accuracy of object detection and recognition.
To ensure highest quality of results, therefore, designers must make certain that the images coming from the camera are optimal. Images captured at dusk, for example, might normally suffer from a lack of differentiation between objects and their backgrounds. A possible way to improve such images is by using a normalization pre-processing step such as one of the techniques previously described in this article. More generally, in an example vision pipeline, light passes through the camera lens and strikes a CMOS sensor (Figure 4). The output of the CMOS sensor routes to an ISP to rectify lens distortions, make color corrections, etc. The pre-processed image then passes on to the vision processor for further analysis.

Figure 4. A typical vision system, from camera to CNN output, showcases the essential capabilities of an ISP (courtesy Synopsys).
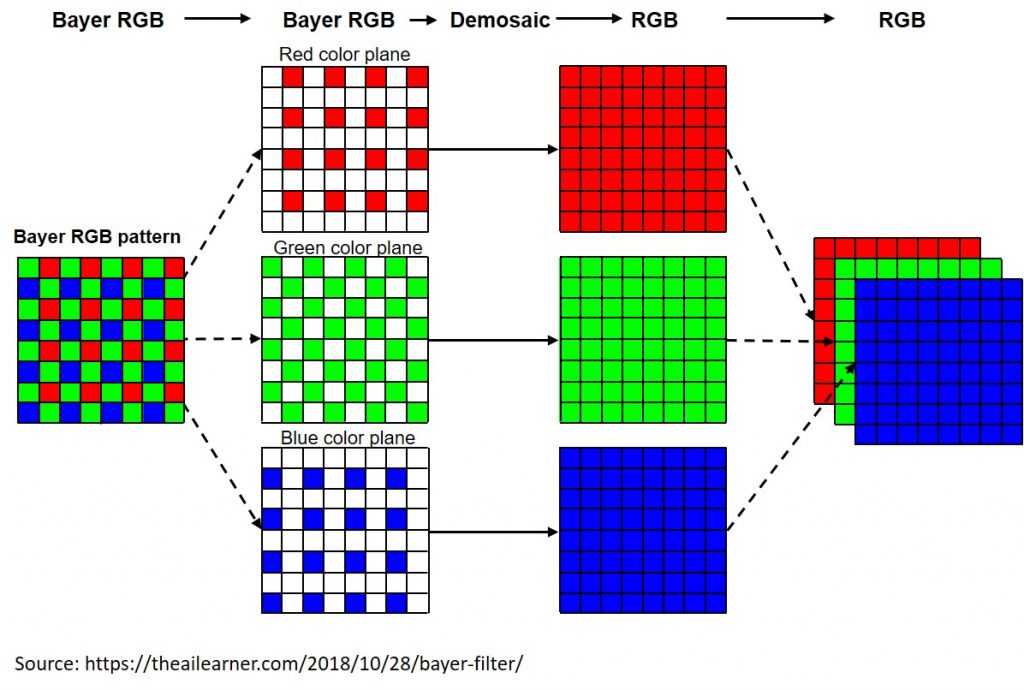
Color image demosaicing is one example of the many important tasks handled by the ISP (Figure 5). Most digital cameras obtain their inputs from a single image sensor that’s overlaid with a color filter array. The sensor output when using the most common color filter array, the Bayer pattern, has a green appearance to the naked eye. That’s because the Bayer filter pattern is 50% green, 25% red and 25% blue; the extra green helps mimic the physiology of the human eye which is more sensitive to green light. Demosaicing makes the images look more natural by extrapolating the missing color values from nearby pixels. This pixel-by-pixel processing of a two-dimensional image exemplifies the various types of operations that an ISP must perform.
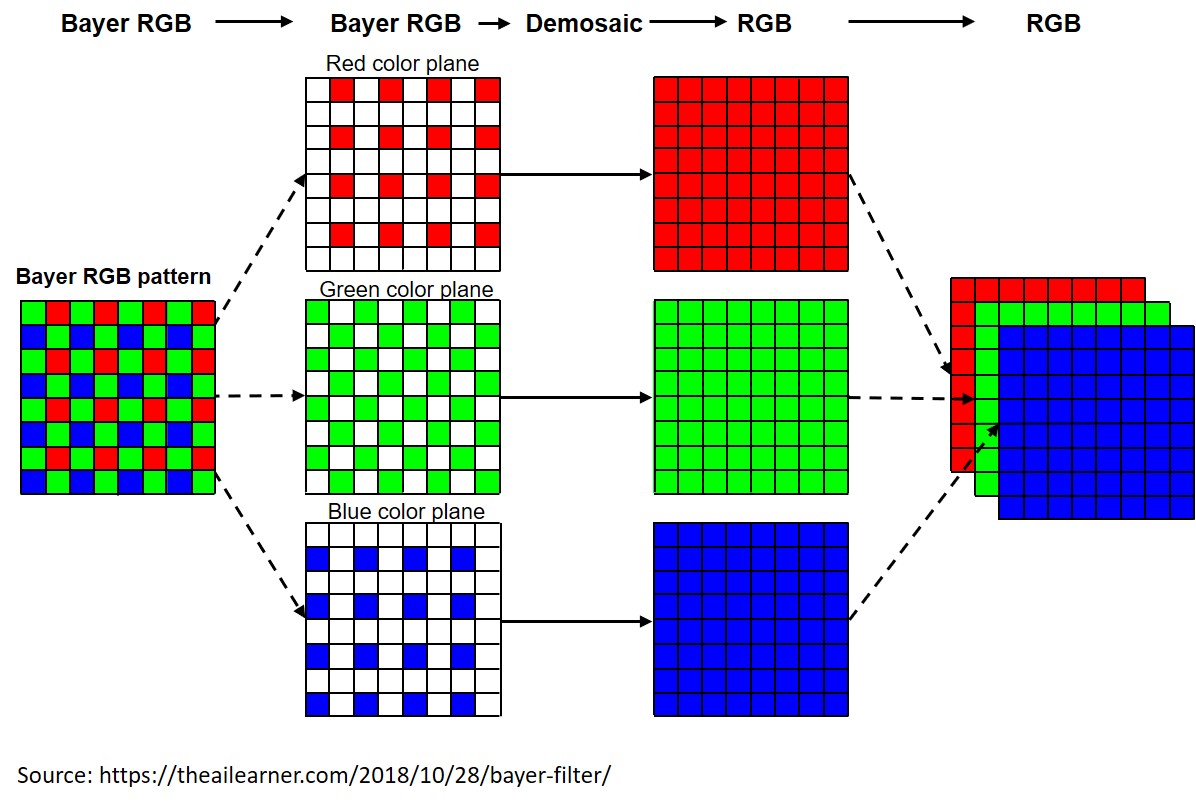
Figure 5. Demosaicing a Bayer pattern image to a normal RGB image requires two-dimensional pixel processing (courtesy Synopsys).
Some camera manufactures embed ISP capabilities in their modules. In other cases, the SoC or system developer will include a hardwired ISP in the design, connected to the camera module’s output. To execute computer vision algorithms such as object detection or facial recognition on the images output by the ISP, a separate vision processor (either on- or off-chip) is also required; if these algorithms are deep learning-based, a CNN “engine” is needed.
Modern vision processors include both vector DSP capabilities and a neural network accelerator (Figure 6). The vision processor’s vector DSP can be used to replace a standalone hardwired ISP, since its capabilities are well suited to alternatively executing ISP functions. It can, for example, perform simultaneous multiply-accumulates on different streams of data; a vector DSP with a 512 bit wide word is capable of performing up to 32 parallel 8-bit multiplies or 16 parallel 16-bit multiplies. In combination with a power- and area-optimized architecture, a vector DSP’s inherent parallelism delivers a highly efficient 2D image processing solution for embedded vision applications.
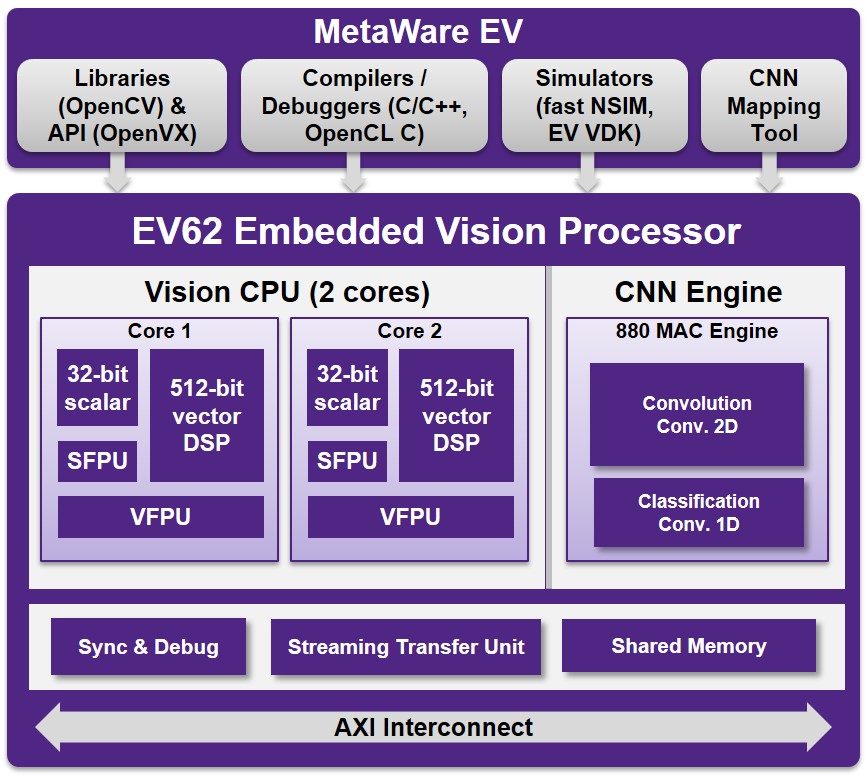
Figure 6. Synopsys’ DesignWare ARC EV62 Vision Processor includes two vector DSP cores and an optional, tightly integrated neural network engine (courtesy Synopsys).
A programmable vision processor requires a robust software tool chain and relevant library functions. Synopsys’ EV62, for example, is supported by the company’s DesignWare ARC® MetaWare EV Development Toolkit, which includes software development tools based on the OpenVX™, OpenCV, and OpenCL C embedded vision standards. Synopsys’ OpenVX implementation extends the standard OpenVX kernel library to include additional kernels that offer OpenCV-like functionality within the optimized, pipelined OpenVX execution environment. For vision processing, OpenVX provides both a framework and optimized vision algorithms—image functions implemented as kernels, which are combined to form an image processing application expressed as a graph. Both the standard and extended OpenVX kernels have been ported and optimized for the EV6x so that designers can take efficient advantage of the parallelism of the vector DSP.
Figure 7 shows an example of an OpenVX graph that uses a combination of standard and extended OpenVX kernels. In this example, cropping of the image is done during the distortion correction (i.e., remap) step. The output of demosaicing then passes through distortion correction, image scaling, and image normalization functions, the latter step adjusting the range of pixel intensity values to correct for poor contrast due to low light or glare, for example.
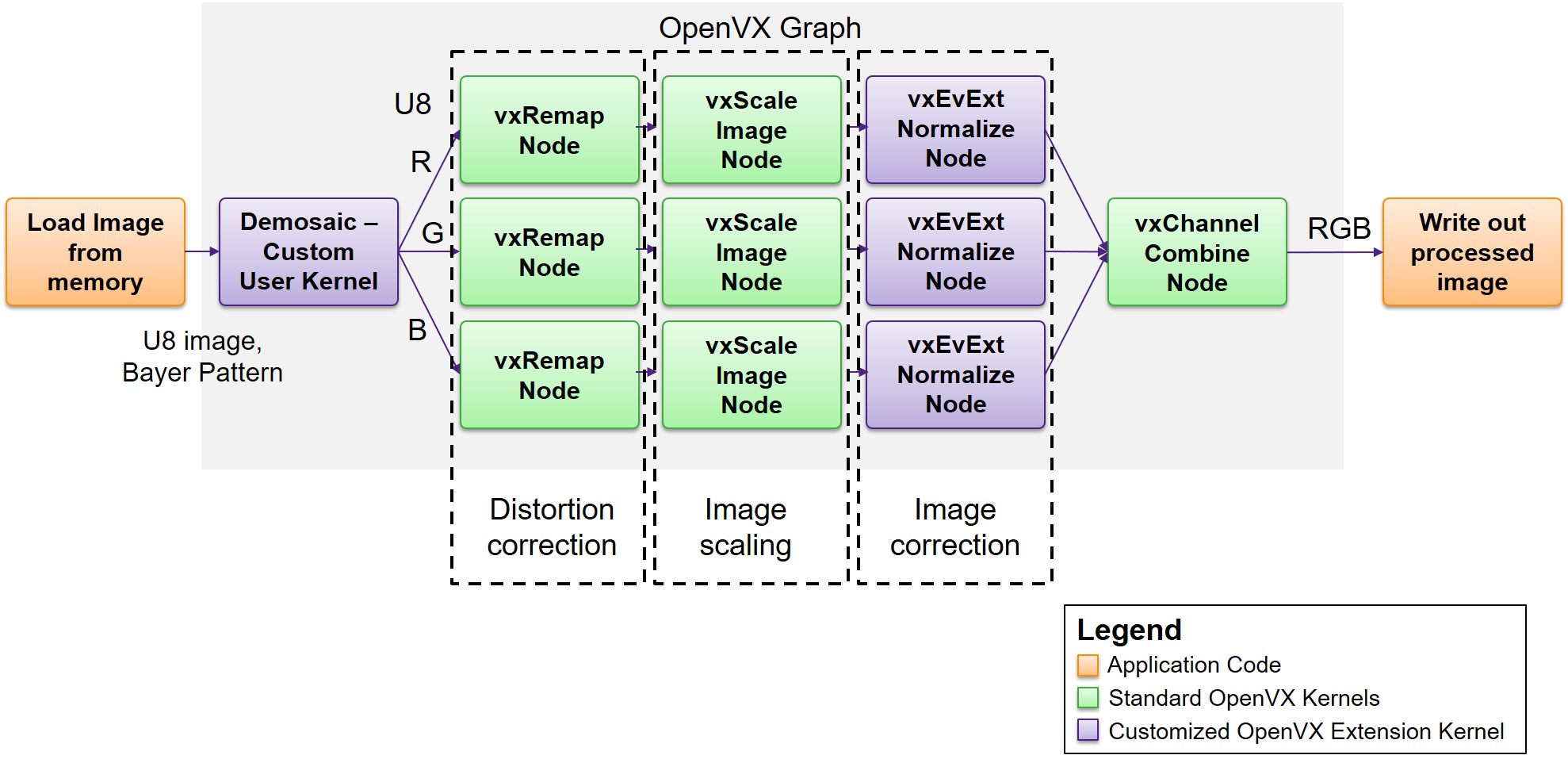
Figure 7. An OpenVX graph for implementing an ISP on a vision processor leverages both standard and extended kernels (courtesy Synopsys).
Because the EV62 has two vision processor CPU cores, it can do “double duty”; one vision processor can execute the ISP algorithms while the other handles other computer vision algorithms in parallel. An EV64, with four vision processor CPU cores, delivers even more parallel processing capabilities.
Gordon Cooper
Product Marketing Manager for DesignWare ARC Embedded Vision Processors
Synopsys
Implementing ISP Functions Using Deep Learning
In a deep learning-based computer vision design, the neural network accelerator is, according to Imagination Technologies, also a compelling candidate for additionally executing image signal processing functions that were historically handled by a standalone ISP. The company discusses its proposed integration approach in the following section.
Today, many designs combine both an ISP and a traditional and/or deep learning-based vision processor, and notable efficiencies can be gained by implementing computer vision applications heterogeneously between them. The challenge lies in the fact that (as previously discussed in this article) ISPs are tuned to process images for human viewing purposes, which can be at odds with the requirements of computer vision applications; in some cases, certain ISP capabilities could be redundant or even negatively impact overall accuracy. In addition, some applications will require outputs that are used for both human viewing and computer vision processing purposes, further complicating the implementation.
Computer vision implementations using CNNs can combine them with a camera and an ISP for deployment in a wide variety of systems that offer vision and AI capabilities. Imagination Technologies believes that modern CNN accelerators are so capable, and the compute requirements of the ISP are so modest in comparison to those of a CNN, that ISP and CNN compute functions can merge into a unified NNA (Neural Network Accelerator). Such an approach offers numerous benefits, particularly with respect to silicon area-measured implementation costs.
Modern CNNs have rapidly overtaken traditional computer vision algorithms in many applications, particularly with respect to accuracy on tasks such as object detection and recognition. CNNs are adaptable, enable rapid development and are inherently simple, consisting primarily of the multiplication and addition operations that make up convolutions. Their high accuracy, however, comes at a steep computational cost.
A CNN is organized in layers with many convolutions per layer. A “deep” network will have multiple convolution layers in sequence. Fortunately, the compute structure of convolutions is highly regular and can be efficiently implemented in dedicated hardware accelerators. However, the sheer scale of the computation required to process the data in a video stream, with adequate frame rate, color depth and resolution and in real-time, can be daunting.
NNAs are dedicated-function processors that perform these core arithmetic functions required by CNNs at performance rates not alternatively possible on a CPU or a GPU for the same area and power budget. An NNA will typically provide more than one TOp/s (trillion operations per second) of peak performance potential. And an NNA can accomplish this feat while requiring a silicon area of only between 1mm2 and 2mm2 when fabricated using modern semiconductor processes, and within a power budget of less than one watt.
An example will put this level of compute resource into tangible context. Consider an ISP that takes in streaming images from an image sensor in Bayer format, i.e., RGGB data, and outputs either RGB or YUV processed images at 30-120 fps (frames per second) rates. Specifically, assume 1920 by 1080 pixel HD resolution video at 60 fps, translating into 2 megapixels per frame or 120 megapixels per second. Each pixel includes at least one byte of data for each red, green and blue color channel, generating a data rate of at least 360 MBytes per second. At a 120 megapixel per second rate, a NNA is capable of executing approximately 10,000 operations (multiplies and adds) per pixel.
A typical CNN for object detection, such as the SSD (Single Shot Detector) network used to identify and place boxes around the vehicles in Figure 8, will require something on the order of 100,000 operations/pixel. The front-end ISP functions, dominated by denoising and demosaicing operations, necessitate an additional ~1,000 operations/pixel. Remarkably, these latter ISP operations demand only around 1% of the total processing potential of a single-core ISP-plus-NNA.

Figure 8. SSD is an example of a CNN used for object detection (courtesy Imagination Technologies).
A conventional architecture (part (a) of Figure 9) uses an ISP to generate images for human viewing purposes, along with a NNA fed by the ISP outputs to handle computer vision. A simpler approach (part (b)) would be to use only one or multiple NNAs, performing both the ISP and deep learning functions. The NNA would first provide a RGB output for human viewing, followed by further processing (on the same or a different NNA) for computer vision.
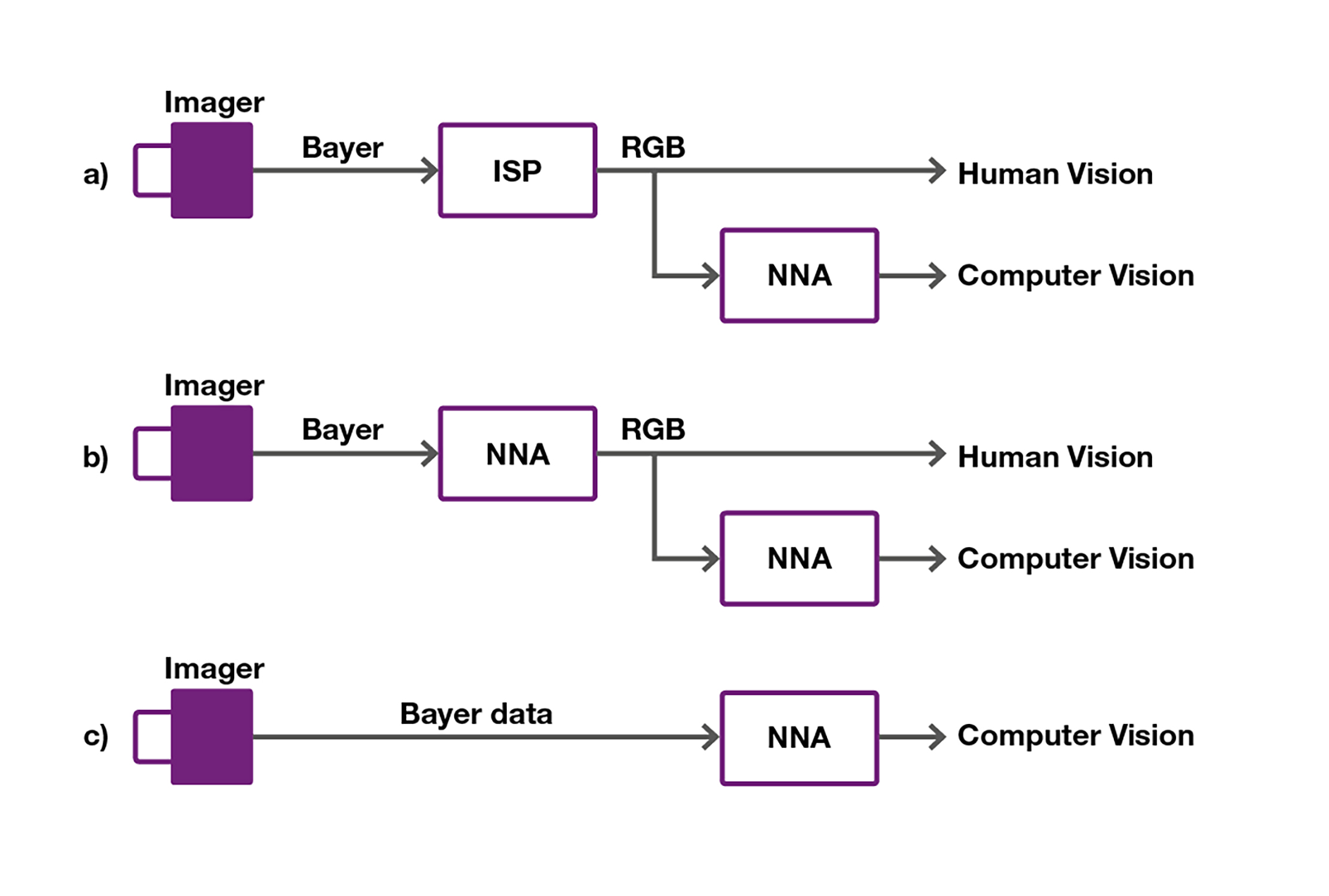
Figure 9. Possible combinations of a NNA and ISP for computer vision and (optional) human viewing (courtesy Imagination Technologies).
The ISP functions can optionally be programmed directly into the NNA in the same way that a standalone ISP might be developed. In such a case, however, some care will be needed in selecting ISP algorithms so that the necessary compute capabilities are fully supported by the operation primitives that an NNA is capable of executing.
Alternatively, the NNA may be running a CNN that is trained to perform the various functions of an ISP. Such an approach is capable of covering a wide range of image conditions such that auto-exposure, auto-white balance and even auto-focus can be supported. Training in this scenario may not be as difficult as it might appear at first glance. If an ISP and NNA version of the final system are available at training time, the combination can be used to train a single CNN through a process known as distillation. Using a single NNA in this way may reduce power consumption and will certainly reduce cost (i.e., silicon area). It also enables the use of off-the-shelf CNNs and is applicable wherever computer vision is automating some tasks but humans still require visual situational awareness.
The final scenario is shown in part (c) of Figure 11, where human viewing is not involved and the CNN running on the NNA has therefore been trained to operate directly on Bayer image data in order to perform both the ISP and computer vision functions. Training in this final case could also leverage the previously mentioned distillation. Applications could potentially include very low-cost IoT devices and extend to forward-looking collision prevention for autonomous vehicles.
Imagination Technologies believes that the traditional combination of a standalone ISP and a computer vision processor (in this case an NNA for CNNs) should be re-evaluated. The ISP functions could alternatively be either directly implemented on an NNA or trained into a CNN executing on an NNA. Regardless of whether or not a human visual output is required, the cost of such a re-architected computer vision system could be significantly lower than is the case with the legacy approach.
Tim Atherton
Senior Research Manager for Vision and AI, PowerVR
Imagination Technologies
Conclusion
An ISP in combination with one or several vision processor(s) can collaboratively deliver more robust computer vision processing capabilities than vision processing is capable of providing standalone. However, an ISP operating in a computer vision-optimized configuration may differ from one functioning under the historical assumption that its outputs would be intended for human viewing purposes. In general, the requirements of an ISP to produce natural, visually accurate imagery and the desire to produce well-purposed imagery for computer vision are closely matched. However, in some cases the nature of the image processing applied in-camera can have a detrimental effect on the effectiveness of embedded vision algorithms. Therefore, it’s important to understand and, if necessary, compensate for how the pixels input to the vision algorithms have already been pre-processed by the ISP.
ISP Fundamentals
In order to understand how an ISP can enhance and/or hamper the effectiveness of a computer vision algorithm, it’s important to first understand what an ISP is and how it operates in its historical primary function: optimizing images for subsequent human viewing purposes. The following section from Apical Limited explores these topics.
Camera designers have decades of experience in creating image-processing pipelines that produce attractive and/or visually accurate images, but what kind of image processing produces video that is optimized for subsequent computer vision analysis? It seems reasonable to begin by considering a conventional ISP. After all, the human eye-brain system produces what we consider aesthetically pleasing imagery for a purpose: to maximize our decision-making abilities. But which elements of such an ISP are most important to get right for good computer vision, and how do they impact the performance of the algorithms that run on them?
Figure A shows a simplified block schematic of a conventional ISP. The input is sensor data in a raw format (one color per pixel), and the output is interpolated RGB or YCbCr data (three colors per pixel).
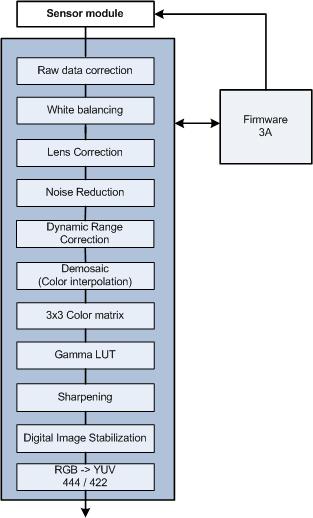
Figure A. A simplified view inside a conventional ISP shows its commonly supported functions (courtesy Apical).
Table A briefly summarizes the function of each block. The list is not intended to be exhaustive; an ISP design team will frequently also implement other modules.
| Module | Function |
| Raw data correction | Set black point, remove defective pixels. |
| Lens correction | Correct for geometric and luminance/color distortions. |
| Noise reduction | Apply temporal and/or spatial averaging to increase SNR (signal to noise ratio). |
| Dynamic range compression | Reduce dynamic range from sensor to standard output without loss of information. |
| Demosaic | Reconstruct three colors per pixel via interpolation with pixel neighbors. |
| 3A | Calculate correct exposure, white balance and focal position. |
| Color correction | Obtain correct colors in different lighting conditions. |
| Gamma | Encode video for standard output. |
| Sharpen | Edge enhancement. |
| Digital image stabilization | Remove global motion due to camera shake/vibration. |
| Color space conversion | RGB to YCbCr. |
Table A. Functions of main ISP modules
Computer vision algorithms may operate directly on the raw data, on the output data, or on data that has subsequently passed through a video compression codec. The data at each of these three stages often has very different quality and other characteristics; these issues are relevant to the performance of computer vision.
Next, let’s review the stages of the ISP in order of decreasing importance to computer vision, an order which also happens to be approximately the top-to-bottom order shown in Figure A. We start with the sensor and optical system. Obviously, the better the sensor and optics, the better the quality of data on which to base decisions. But “better” is not a matter simply of resolution, frame rate or SNR (signal-to-noise ratio). Dynamic range, for example, is also a key characteristic. Dynamic range is the relative difference in brightness between the brightest and darkest details that the sensor can record within a single scene, with a value normally expressed in dB.
CMOS and CCD sensors commonly have a dynamic range of between 60 and 70 dB, sufficient to capture all details that are fairly uniformly illuminated in scenes. Special sensors are required to capture the full range of illumination in high contrast environments. Around 90dB of dynamic range is needed to simultaneously record information in deep shadows and bright highlights on a sunny day; this requirement rises further if extreme lighting conditions occur (the human eye has a dynamic range of around 120dB). If the sensor can’t capture such a wide range, objects that move across the scene will disappear into blown-out highlights and/or deep shadows below the sensor black level. High (i.e., wide) dynamic range sensors are helpful in improving computer vision performance in uncontrolled lighting environments. Efficient processing of such sensor data, however, is not trivial.
The next most important ISP stage, for a number of reasons, is noise reduction. In low light settings, noise reduction is frequently necessary to raise objects above the noise background, subsequently aiding in accurate segmentation. High levels of temporal noise can also easily confuse tracking algorithms based on pixel motion, even though such noise is largely uncorrelated both spatially and temporally. If the video passes through a lossy compression algorithm prior to post-processing, you should also consider the effect of noise reduction on compression efficiency. The bandwidth required to compress noisy sources is much higher than with “clean” sources. If transmission or storage is bandwidth-limited, the presence of noise reduces the overall compression quality and may lead to increased amplitude of quantization blocks, which confuse computer vision algorithms.
Effective noise reduction can readily increase compression efficiency by 70% or more in moderate noise environments, even when the increase in SNR is visually unnoticeable. However, noise reduction algorithms may themselves introduce artifacts. Temporal processing works well because it increases the SNR by averaging the processing over multiple frames. Both global and local motion compensation may be necessary to eliminate false motion trails in environments with fast movement. Spatial noise reduction aims to blur noise while retaining texture and edges and risks suppressing important details. It’s important, therefore, to strike a careful balance between SNR increase and image quality degradation.
The correction of lens geometric distortions, chromatic aberrations and lens shading (i.e., vignetting) is of inconsistent significance, depending on the optics and application. For conventional cameras, uncorrected data may be perfectly suitable for post-processing. In digital PTZ (pan, tilt and zoom) cameras, on the other hand, correction is a fundamental component of the system. A set of “3A” algorithms control camera exposure, color and focus, based on statistical analysis of the sensor data. Their function and impact on computer vision is shown in Table B.
| Algorithm | Function | Impact |
| Auto exposure | Adjust exposure to maximize the amount of scene captured. Avoid flicker in artificial lighting. | A poor algorithm may blow out highlights or clip dark areas, losing information. Temporal instabilities may confuse motion-based analysis. |
| Auto white balance | Obtain correct colors in all lighting conditions. | If color information is used by computer vision, it needs to be accurate. It is challenging to achieve accurate colors in all lighting conditions. |
| Auto focus | Focus the camera. | Which regions of the image should receive focus attention? How should the algorithm balance temporal stability versus rapid refocusing in a scene change? |
Table B. The impact of “3A” algorithms
Finally, we turn to DRC (dynamic range compression). DRC is a method of non-linear image adjustment that reduces dynamic range, i.e., global contrast. It has two primary functions: detail preservation and luminance normalization.
As mentioned earlier, the better the dynamic range of the sensor and optics, the more data will typically be available for computer vision to work on. But in what form do the algorithms receive this data? For some embedded vision applications, it may be no problem to work directly with the high bit depth raw sensor data. But if the analysis is run in-camera on RGB or YCbCr data, or as post-processing based on already lossy-compressed data, the dynamic range of such data is typically limited by the 8-bit standard format, which corresponds to 60 dB. This means that unless DRC occurs in some way prior to encoding, the additional scene information will be lost. While techniques for DRC are well established (gamma correction is one form, for example), many of them decrease image quality in the process, by degrading local contrast and color information, or by introducing spatial artifacts.
Another application of DRC is in image normalization. Advanced computer vision algorithms, such as those employed in facial recognition, are susceptible to changing and non-uniform lighting environments. For example, an algorithm may recognize the same face differently depending on whether the face is uniformly illuminated or lit by a point source to one side, in the latter case casting a shadow on the other side. Good DRC processing can be effective in normalizing imagery from highly variable illumination conditions to simulated constant, uniform lighting, as Figure B shows.
 |
 |
Figure B. DRC can normalize (left) a source image with non-uniform illumination (right) (courtesy Apical).
Michael Tusch
Founder and CEO
Apical Limited
Assessing ISP Necessity
Ongoing academic research regularly revisits the necessity of routing the raw data coming out of an image sensor through an ISP prior to presenting the resulting images to computer vision algorithms for further processing. The potential for skipping the costly, power consuming and latency-inducing ISP step in the process is particularly relevant with deep learning-based visual analysis approaches, where the network model used for inference can potentially be pre-trained with “raw” images from a sensor instead of pre-processed images from an intermediary ISP. Recent encouraging results using uncorrected (i.e., pre-ISP) images suggest that that the inclusion of an ISP as a pre-processing step for computer vision may eventually no longer be necessary.
Note, however, that this ISP-less approach will only be appropriate for scenarios where computer vision processing is the only destination for the image sensor’s output data. Consider, for example, a vehicle backup camera that both outputs images to a driver-viewable display and supplies those images as inputs to a passive collision warning or active autonomous collision-avoidance system. Or consider a surveillance system, where the initial detection of a potential intruder might be handled autonomously by computer vision but confirmation of intrusion is made by a human being, and/or when human-viewable images are necessary for the intruder’s subsequent prosecution in a court of law. In these and other cases, an ISP (whether standalone or function-integrated into another processor) will still be necessary to parallel-process the images for humans’ eyes and brains.
Additional Developer Assistance
The Embedded Vision Alliance® is a global partnership that brings together technology providers with end product and systems developers who are enabling innovative, practical applications of computer vision and visual AI. Imagination Technologies and Synopsys, the co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance’s mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance’s annual conference and trade show, the Embedded Vision Summit®, is coming up May 20-23, 2019 in Santa Clara, California. Intended for product creators interested in incorporating visual intelligence into electronic systems and software, the Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees’ imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. More information, along with online registration, is now available.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other machine learning frameworks. Access is free to all through a simple registration process. The Embedded Vision Alliance and its member companies also periodically deliver webinars on a variety of technical topics, including various machine learning subjects. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Alliance website.