By Brian Dipert
Senior Analyst, BDTI
Editor-in-Chief, Embedded Vision Alliance
Yair Siegel
Director of Marketing, Multimedia, CEVA
Simon Morris
Chief Executive Officer, CogniVue
Liat Rostock
Marketing Director, eyeSight Mobile Technologies
Gershom Kutliroff
Chief Technical Officer, Omek Interactive
This article was originally published at EE Times' Communications Design Line. It is reprinted here with the permission of EE Times.
The means by which we interact with the machines around us is undergoing a fundamental transformation. While we may still sometimes need to push buttons, touch displays and trackpads, and raise our voices, we’ll increasingly be able to interact with and control our devices simply by signaling with our fingers, gesturing with our hands, and moving our bodies.
Most consumer electronic devices today – smart phones, tablets, PCs, TVs, and the like – either already include or will soon integrate one or more cameras. Automobiles and numerous other products are rapidly becoming camera-enabled, too. What can be achieved with these cameras is changing the way we interact with our devices and with each other. Leveraging one or multiple image sensors, these cameras generate data representing the three-dimensional space around the device, and innovators have developed products that transform this data into meaningful operations.
Gesture recognition, one key example of these sensor-enabled technologies, is achieving rapid market adoption as it evolves and matures. Although various gesture implementations exist in the market, a notable percentage of them are based on embedded vision algorithms that use cameras to detect and interpret finger, hand and body movements. Gestures have been part of humans’ native interaction language for eons. Adding support for various types of gestures to electronic devices enables using our natural "language" to operate these devices, which is much more intuitive and effortless when compared to touching a screen, manipulating a mouse or remote control, tweaking a knob, or pressing a switch.
Gesture controls will notably contribute to easing our interaction with devices, reducing (and in some cases replacing) the need for a mouse, keys, a remote control, or buttons (Figure 1). When combined with other advanced user interface technologies such as voice commands and face recognition, gestures can create a richer user experience that strives to understand the human "language," thereby fueling the next wave of electronic innovation.

(a)

(b)
Figure 1. Touching a tablet computer or smartphone's screen is inconvenient (at best, and more likely impossible) when you're in the kitchen and your hands are coated with cooking ingredients (a). Similarly, sand, sun tan lotion and water combine to make touchscreens infeasible at the beach, assuming the devices are even within reach (b).
Not just consumer electronics
When most people think of gesture recognition, they often imagine someone waving his or her hands, arms or bodies in the effort to control a game or other application on a large-screen display. Case studies of this trend include Microsoft’s Kinect peripheral for the Xbox 360, along with a range of gesture solutions augmenting traditional remote controls for televisions and keyboards, mice, touchscreens and trackpads for computers. At the recent Consumer Electronics Show, for example, multiple TV manufacturers showcased camera-inclusive models that implemented not only gesture control but also various face recognition-enabled features. Similarly, Intel trumpeted a diversity of imaging-enabled capabilities for its Ultrabook designs.
However, gesture recognition as a user interface scheme also applies to a wide range of applications beyond consumer electronics. In the automotive market, for example, gesture is seen as a convenience-driven add-on feature for controlling the rear hatch and sliding side doors. Cameras already installed in rear of the vehicle for reversing, and in the side mirrors for blind spot warning, can also be employed for these additional capabilities. As the driver approaches the car, a proximity sensor detects the ignition key in the pocket or purse and turns on the cameras. An appropriate subsequent wave of the driver’s hand or foot could initiate opening of the rear hatch or side door.
Another potential automotive use case is inside the cabin, when an individual cannot (or at least should not) reach for a particular button or knob when driving but still wants to answer an incoming cellphone call or change menus on the console or infotainment unit. A simple hand gesture may be a safer, quicker and otherwise more convenient means of accomplishing such a task. Many automotive manufacturers are currently experimenting with (and in some cases already publicly demonstrating) gesture as a means for user control in the car, among other motivations as an incremental safety capability.
Additional gesture recognition opportunities exist in medical applications where, for health and safety reasons, a nurse or doctor may not be able to touch a display or trackpad but still needs to control a system. In other cases, the medical professional may not be within reach of the display yet still needs to manipulate the content being shown on the display. Appropriate gestures, such as hand swipes or using a finger as a virtual mouse, are a safer and faster way to control the device (Figure 2).
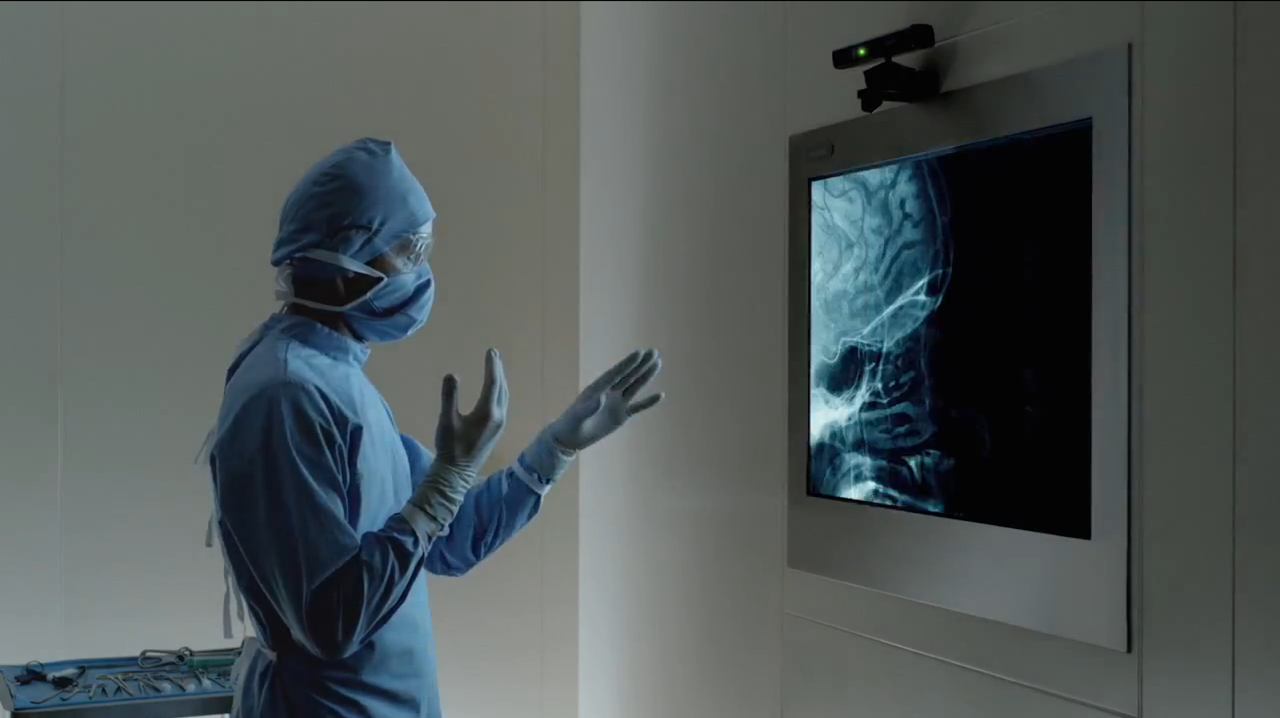
Figure 2. Microsoft's "Kinect Effect" video showcased a number of applications then under development for Kinect for Windows (and conceptually applicable to other 2-D and 3-D sensor technologies, as well)
Gesture interfaces are also useful in rehabilitation situations. Gesturetek’s IREX, for example, guides patients through interactive exercises that target specific body parts. And less conventional health-related applications for gesture recognition also exist. For instance, users with physical handicaps may not be able to use a conventional keyboard or mouse but could instead leverage the recognition of facial gestures as a means of control. And active university research is also underway on using gesture recognition as a means of translating sign language to text and speech.
More generally, diverse markets exist where gestures are useful for display control. You might recall, for example, the popular image of Tom Cruise manipulating the large transparent display in the movie Minority Report. Or consider the advertising market where interactive digital signs could respond to viewers’ gestures (not to mention identifying a particular viewer's age, gender, ethnicity and other factors) in order to optimize the displayed image and better engage the viewer. Even in industrial markets, appliances such as ceiling-positioned HVAC sensors could be conveniently controlled via gestures. As sensor technologies, gesture algorithms and vision processors continue to improve over time, what might appear today to be a unique form of interactivity will be commonplace in the future, across a range of applications and markets.
Implementations vary by application
The meaning of the term "gesture recognition" has become broader over time, as it's used to describe an increasing range of implementation variants. These specific solutions may be designed and optimized, for example, for either close- or long-range interaction, for fine-resolution gestures or robust full-bodied movements, and for continuous tracking or brief-duration gestures. Gesture recognition technology entails a wide variety of touch-free interaction capabilities, each serving a different type of user interface scenario.
Close-range gesture detection is typically used in handheld devices such as smartphones and tablets, where the interaction occurs in close proximity to the device’s camera. In contrast, long-range gesture control is commonly employed with devices such as TVs, set-top boxes, digital signage, and the like, where the distance between the user and the device can span multiple feet and interaction is therefore from afar.
While user interface convenience is at the essence of gesture control in both user scenarios, the algorithms used, specifically the methods by which gestures are performed and detected, are fundamentally different. In close-range usage, the camera "sees" a hand gesture in a completely different way than how the camera "sees" that same hand and gesture in long-range interaction.
Additionally, a distinction exists between different gesture "languages." For example, when using gestures to navigate through the detailed menus of a "smart" TV, the user will find it intuitive to use fine-resolution, small gestures to select menu items. However, when using the device to play games based on full-body detection, robust gestures are required to deliver the appropriate experience.
Moreover, differences exist between rapid-completion gestures and those that involve continuous hand tracking. A distinctive hand motion from right to left or left to right can be used, for example, to flip eBook pages or change songs on a music playback application. These scenarios contrast to continuous hand tracking, which is relevant for control of menus and other detailed user interface elements, such as a Windows 8 UI or a smart TV's screen.
Other implementation challenges
Any gesture control product contains several different key hardware and software components, all of which must be tightly integrated in order to provide a compelling user experience. First is the camera, which captures the raw data that represent the user’s actions. Generally, this raw data is then processed, in order to reduce the noise in the signal, for example, or (in the case of 3-D cameras) to compute the depth map.
Specialized algorithms subsequently interpret the processed data, translating the user’s movements into "actionable" commands that a computer can understand. And finally, an application integrates these actionable commands with user feedback in a way that must be both natural and engaging. Adding to the overall complexity of the solution, the algorithms and applications are increasingly implemented on embedded systems with limited processing, storage and other resources.
Tightly integrating these components to deliver a compelling gesture control experience is not a simple task, and the complexity is further magnified by the demands of gesture control applications. In particular, gesture control systems must be highly interactive, able to process large amounts of data with imperceptible latency. Commonly encountered incoming video streams, depending on the application, have frame resolutions ranging from QVGA to 1080p HD, at frame rates of 24 to 60 fps.
Bringing gesture control products to market therefore requires a unified effort among the different members of the technology supplier ecosystem: sensor and camera manufacturers, processor companies, algorithm providers, and application developers. Optimizing the different components to work together smoothly is critical in order to provide an engaging user experience. Vision functions, at the core of gesture algorithms, are often complex to implement and may require substantial additional work to optimize for the specific features of particular image processors. However, a substantial-sized set of functions finds common and repeated use across various applications and products. A strong case can therefore be made for the development of cross-platform libraries that provide common low-level vision functions.
In a market as young as gesture control, there is also still little to no standardization across the ecosystem. Multiple camera technologies are used to generate 3-D data, and each technique produces its own characteristic artifacts. Each 3-D camera also comes with its own proprietary interface. And gesture dictionaries are not standardized; a motion that may one thing on one system implementation may mean something completely different (or alternatively nothing at all) on a different system. Standardization is inevitable and is necessary for the industry to grow and otherwise mature.
Industry alliance opportunities
The term “embedded vision,” of which gesture control is one key application example, refers to the use of computer vision technology in embedded systems, mobile devices, PCs, and the cloud. Stated another way, “embedded vision” refers to embedded systems that extract meaning from visual inputs. Similar to the way that wireless communication has become pervasive over the past 10 years, embedded vision technology is poised to be widely deployed in the next 10 years.
Embedded vision technology has the potential to enable a wide range of electronic products that are more intelligent and responsive than before, and thus more valuable to users. It can add helpful features to existing products. And it can provide significant new markets for hardware, software and semiconductor manufacturers. The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower engineers to transform this potential into reality.
BDTI, CEVA, CogniVue, eyeSight Mobile Technologies and Omek Interactive, the co-authors of this article, are all members of the Embedded Vision Alliance. First and foremost, its mission is to provide engineers with practical education, information, and insights to help them incorporate embedded vision capabilities into products. To execute this mission, the Alliance has developed a website (www.Embedded-Vision.com) providing tutorial articles, videos, code downloads and a discussion forum staffed by a diversity of technology experts. Registered website users can also receive the alliance’s twice-monthly e-mail newsletter (www.embeddedvisioninsights.com), among other additional benefits.
Transforming a gesture control experience into a shipping product entails compromises – in cost, performance, and accuracy, to name a few. The Embedded Vision Alliance catalyzes these conversations in a forum where such tradeoffs can be understood and resolved, and where the effort to productize gesture control can therefore be accelerated, enabling system developers to effectively harness gesture user interface technology. For more information on the Embedded Vision Alliance, including membership details, please visit www.Embedded-Vision.com, email [email protected] or call 925-954-1411.
Please also consider attending the Alliance's upcoming Embedded Vision Summit, a free day-long technical educational forum to be held on April 25th in San Jose, California and intended for engineers interested in incorporating visual intelligence into electronic systems and software. The event agenda includes how-to presentations, seminars, demonstrations, and opportunities to interact with Alliance member companies. For more information on the Embedded Vision Summit, including an online registration application form, please visit www.embeddedvisionsummit.com.
Author biographies
Brian Dipert is Editor-In-Chief of the Embedded Vision Alliance. He is also a Senior Analyst at Berkeley Design Technology, Inc., which provides analysis, advice, and engineering for embedded processing technology and applications, and Editor-In-Chief of InsideDSP, the company's online newsletter dedicated to digital signal processing technology. Brian has a B.S. degree in Electrical Engineering from Purdue University in West Lafayette, IN. His professional career began at Magnavox Electronics Systems in Fort Wayne, IN; Brian subsequently spent eight years at Intel Corporation in Folsom, CA. He then spent 14 years at EDN Magazine.
Yair Siegel serves as Director of Marketing, covering multimedia, at CEVA. Prior to this, he was Director of Worldwide Field Applications. Yair has worked with CEVA, along with the licensing division of DSP Group, since 1997, serving in various R&D engineering and management positions within the Software Development Tools department. He holds a BSc degree in Computer Science and Economics from the Hebrew University in Jerusalem, as well as a MBA and a MA in Economics from Tel-Aviv University.
Simon Morris has over 20 years of professional experience in both private and public semiconductor companies, and as CogniVue's CEO is responsible for leading the company's evolution from an R&D cost center through spin-out to an independent privately held fabless semiconductor and embedded software business. Prior to joining CogniVue, Simon was Director at BDC Venture Capital. From 1995-2006 he also held various senior and executive leadership positions at Atsana Semiconductor, and senior positions at Texas Instruments. Simon has an M.Eng in Electrical Engineering and a B.Eng in Electrical Engineering from the Royal Military College of Canada, and is a member of the Professional Engineers of Ontario.
As eyeSight’s Marketing Director, Liat Rostock’s responsibilities cover company branding, public relations, event management, channel marketing and communication strategy. Prior to this position Liat gained the valuable insight into the company as eyeSight’s Senior Project Manager as part of which she was responsible for the design, development process, and distribution of applications integrated with eyeSight’s technology. Liat holds a B.A from IDC Herzeliya where she majored in marketing.
Gershom Kutliroff is CTO and co-founder of Omek Interactive, in which role he is responsible for the company’s proprietary algorithms and software development. Before founding Omek, Dr. Kutliroff was the Chief Scientist of IDT Video Technologies, where he led research efforts in developing computer vision applications to support IDT’s videophone operations. Prior to that, he was the leader of the Core Technologies group at DPSi, a computer animation studio. He earned his Ph. D. and M. Sc. in Applied Mathematics from Brown University, and his B. Sc. in Applied Mathematics from Columbia University.