This article provides both background and implementation-detailed information on software frameworks and toolsets for deep learning-based vision processing, an increasingly popular and robust alternative to classical computer vision algorithms. It covers the leading available software framework options, the root reasons for their abundance, and guidelines for selecting an optimal approach among the candidates for a particular implementation. It also covers "middleware" utilities that optimize a generic framework for use in a particular embedded implementation, comprehending factors such as applicable data types and bit widths, as well as available heterogeneous computing resources.
For developers in specific markets and applications, toolsets that incorporate deep learning techniques can provide an attractive alternative to an intermediary software framework-based development approach. And the article also introduces an industry alliance available to help product creators optimally implement deep learning-based vision processing in their hardware and software designs.
Traditionally, computer vision applications have relied on special-purpose algorithms that are painstakingly designed to recognize specific types of objects. Recently, however, CNNs (convolutional neural networks) and other deep learning approaches have been shown to be superior to traditional algorithms on a variety of image understanding tasks. In contrast to traditional algorithms, deep learning approaches are generalized learning algorithms trained through examples to recognize specific classes of objects, for example, or to estimate optical flow. Since deep learning is a comparatively new approach, however, the usage expertise for it in the developer community is comparatively immature versus with traditional algorithms such as those included in the OpenCV open-source computer vision library.
General-purpose deep learning software frameworks can significantly assist both in getting developers up to speed and in getting deep learning-based designs completed in a timely and robust manner, as can deep learning-based toolsets focused on specific applications. However, when using them, it's important to keep in mind that the abundance of resources that may be assumed in a framework originally intended for PC-based software development, for example, aren't likely also available in an embedded implementation. Embedded designs are also increasingly heterogeneous in nature, containing multiple computing nodes (not only a CPU but also GPU, FPGA, DSP and/or specialized co-processors); the ability to efficiently harness these parallel processing resources is beneficial from cost, performance and power consumption standpoints.
Deep Learning Framework Alternatives and Selection Criteria
The term "software framework" can mean different things to different people. In a big-picture sense, you can think of it as a software package that includes all elements necessary for the development of a particular application. Whereas an alternative software library implements specific core functionality, such as a set of algorithms, a framework provides additional infrastructure (drivers, a scheduler, user interfaces, a configuration parser, etc.) to make practical use of this core functionality. Beyond this high-level overview definition, any more specific classification of the term "software framework", while potentially more concrete, intuitive and meaningful to some users, would potentially also exclude other subsets of developers' characterizations and/or applications' uses.
When applied to deep learning-based vision processing, software frameworks contain different sets of elements, depending on their particular application intentions. Frameworks for designing and training DNNs (deep neural networks) provide core algorithm implementations such as convolutional layers, max pooling, loss layers, etc. In this initial respect, they're essentially a library. However, they also provide all of the necessary infrastructure to implement functions such as reading a network description file, linking core functions into a network, reading data from training and validation databases, running the network forward to generate output, computing loss, running the network backward to adapt the weights, and repeating this process as many times as is necessary to adequately train the network.
It’s possible to also use training-tailored frameworks for inference, in conjunction with a pre-trained network, since such "running the network forward" operations are part of the training process (Figure 1). As such, it may be reasonable to use training-intended frameworks to also deploy the trained network. However, although tools for efficiently deploying DNNs in applications are often also thought of as frameworks, they only support the forward pass. For example, OpenVX with its neural network extension supports efficient deployment of DNNs but does not support training. Such frameworks provide only the forward pass components of core algorithm implementations (convolution layers, max pooling, etc.). They also provide the necessary infrastructure to link together these layers and run them in the forward direction in order to infer meaning from input images, based on previous training.
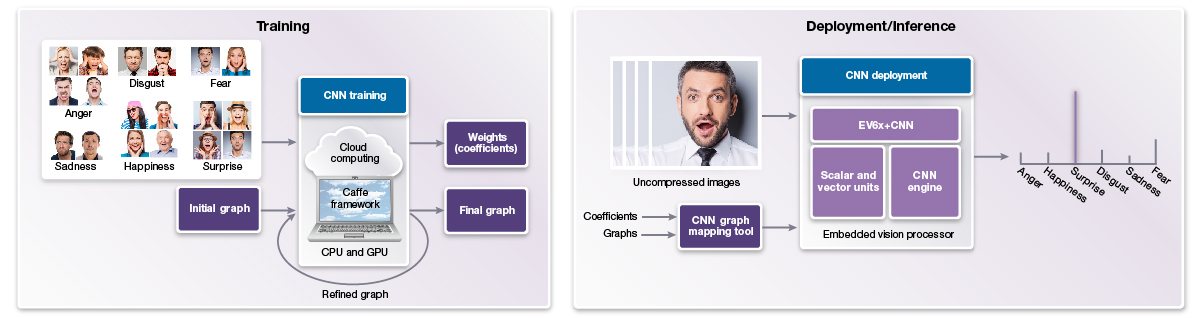
Figure 1. In deep learning inference, also known as deployment (right), a neural network analyzes new data it’s presented with, based on its previous training (left) (courtesy Synopsys).
Current examples of frameworks intended for training DNNs include Caffe, Facebook's Caffe2, Microsoft's Cognitive Toolkit, Darknet, MXNet, Google's TensorFlow, Theano, and Torch (Intel's Deep Learning Training Tool and NVIDIA's DIGITS are a special case, as they both run Caffe "under the hood"). Inference-specific frameworks include the OpenCV DNN module, Khronos' OpenVX Neural Network Extension, and various silicon vendor-specific tools. Additionally, several chip suppliers provide proprietary tools for quantizing and otherwise optimizing networks for resource-constrained embedded applications, which will be further discussed in subsequent sections of this article. Such tools are sometimes integrated into a standalone framework; other times they require (or alternatively include a custom version of) another existing framework.
Why do so many framework options exist? Focusing first on those intended for training, reasons for this diversity include the following:
- Various alternatives were designed more or less simultaneously by different developers, ahead of the potential emergence of a single coherent and comprehensive solution.
- Different offerings reflect different developer preferences and perspectives regarding DNNs. Caffe, for example, is in some sense closest to an application, in that a text file is commonly used to describe a network, with the framework subsequently invoked via the command line for training, testing and deployment. TensorFlow, in contrast, is closer to a language, specifically akin to Matlab with a dataflow paradigm. Meanwhile, Theano and Torch are reminiscent of a Python library.
- Differences in capabilities also exist, such as different layer types supported by default, as well as support (or not) for integer and half-float numerical formats.
Regarding frameworks intended for efficient DNN deployment, differences between frameworks commonly reflect different design goals. OpenVX, for example, is primarily designed for portability while retaining reasonable levels of performance and power consumption. The OpenCV DNN module, in contrast, is designed first and foremost for ease of use. And of course, the various available vendor-specific tools are designed to solely support particular hardware platforms.
Finally, how can a developer select among the available software framework candidates to identify one that's optimum for a particular situation? In terms of training, for example, the decision often comes down to familiarity and personal preference. Substantial differences also exist in capabilities between the offerings, however, and these differences evolve over time; at some point, the advancements in an alternative framework may override legacy history with an otherwise preferred one.
Unfortunately there’s no simple answer to the "which one's best" question. What does the developer care about most? Is it speed of training, efficiency of inference, the need to use a pre-trained network, ease of implementing custom capabilities in the framework, etc? For each of these criteria, differences among frameworks exist both in capabilities offered and in personal preference (choice of language, etc). With that all said, a good rule of thumb is to travel on well-worn paths. Find out what frameworks other people are already using in applications as similar as possible to yours. Then, when you inevitably run into problems, your odds of finding a documented solution are much better.
Addressing Additional Challenges
After evaluating the tradeoffs of various training frameworks and selecting one for your project, several other key design decisions must also be made in order to implement an efficient embedded deep learning solution. These include:
- Finding or developing an appropriate training dataset
- Selecting a suitable vision processor (or heterogeneous multi-processor) for the system
- Designing an effective network model topology appropriate for the available compute resources
- Implementing a run-time that optimizes any available hardware acceleration in the SoC
Of course, engineering teams must also overcome these development challenges within the constraints of time, cost, and available skill sets.
One common starting point for new developers involves the use of an example project associated with one of the training frameworks. In these tutorials, developers are typically guided through a series of DIY exercises to train a preconfigured CNN for one of the common image classification problems such as MNIST, CIFAR-10 or ImageNet. The result is a well-behaved neural net that operates predictably on a computer. Unfortunately, at this point the usefulness of the tutorials usually begins to diminish, since it’s then left as an "exercise for the reader" to figure out how to adapt and optimize these example datasets, network topologies and PC-class inference models to solve other vision challenges and ultimately deploy a working solution on an embedded device.
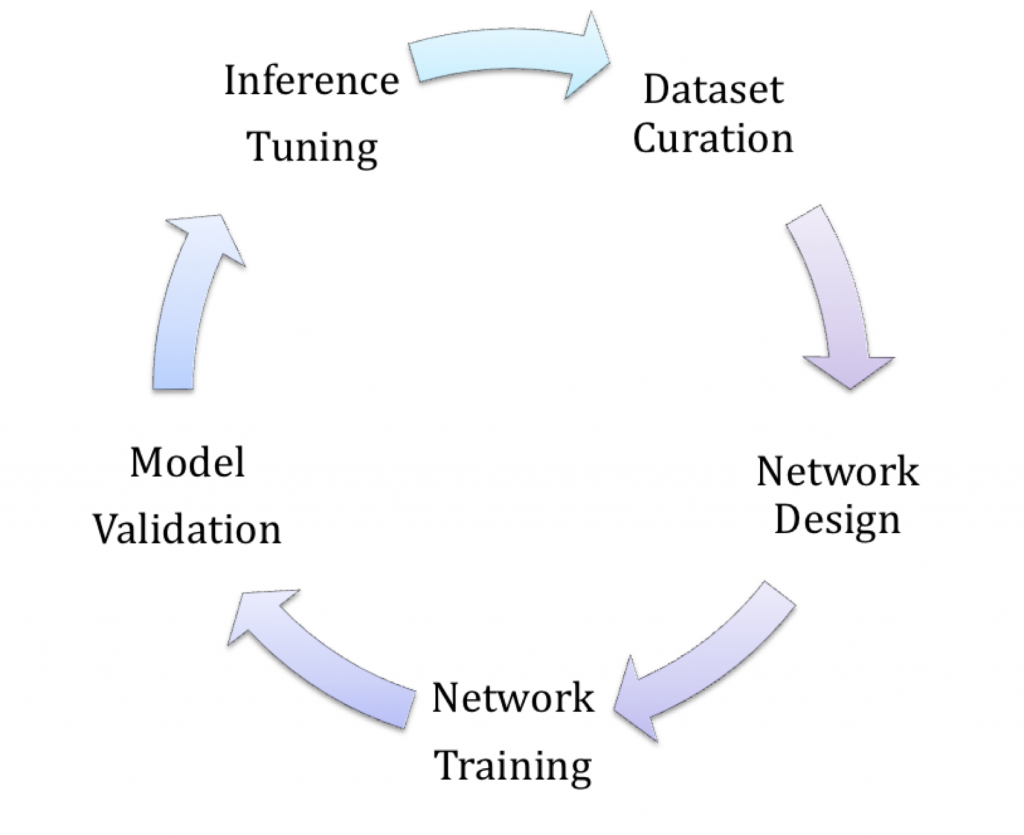
The deep learning aspect of such a project will typically comprise six distinct stages (Figure 2). The first four take place on a computer (for development), with the latter two located on the target (for deployment):
- Dataset creation, curation and augmentation
- Network design
- Network training
- Model validation and optimization
- Runtime inference accuracy and performance tuning
- Provisioning for manufacturing and field updates
Figure 2. The first five (of six total) stages of a typical deep learning project are frequently iterated multiple times in striving for an optimal implementation (courtesy Au-Zone Technologies).
Development teams may find themselves iterating steps 1-5 many times in searching for an optimal balance between network size, model accuracy and runtime inference performance on the processor(s) of choice. For developers considering deployment of Deep Learning vision solutions on standard SoC’s, development tools such as Au-Zone Technologies' DeepView ML Toolkit and Run-Time Inference Engine are helpful in addressing the various challenges faced at each of these developmental stages (see sidebar "Leveraging GPU Acceleration for Deep Learning Development and Deployment") (Figure 3).
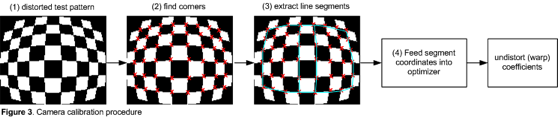
Figure 3. The DeepView Machine Learning Toolkit provides various facilities useful in addressing challenges faced in both deep learning development and deployment (courtesy Au-Zone Technologies).
Framework Optimizations for DSP Acceleration
In comparison to the abundant compute and memory resources available in a PC, an embedded vision system must offer performance sufficient for target applications, but at greatly reduced power consumption and die area. Embedded vision applications therefore greatly benefit from the availability of highly optimized heterogeneous SoCs containing multiple parallel processing units, each optimized for specific tasks. Synopsys' DesignWare EV6x family, for example, integrates a scalar unit for control, a vector unit for pixel processing, and an optional dedicated CNN engine for executing deep learning networks (Figure 4).
Figure 4. Modern SoCs, as well as the cores within them, contain multiple heterogeneous processing elements suitable for accelerating various aspects of deep learning algorithms (courtesy Synopsys).
Embedded vision system designers have much to consider when leveraging a software framework for training a CNN graph. They must pay attention to the bit resolution of the CNN calculations, consider all possible hardware optimizations during training, and evaluate how best to take advantage of available coefficient and feature map pruning and compression techniques. If silicon area (translating to SoC cost) isn’t a concern, an embedded vision processor might directly use the native 32-bit floating-point outputs of PC-tailored software frameworks. However, such complex data types demand large MACs (multiply-accumulator units), sizeable memory for storage, and high transfer bandwidth. All of these factors adversely affect the SoC and system power consumption and area budgets. The ideal goal, therefore, is to use the smallest possible bit resolution without adversely degrading the accuracy of the original trained CNN graph.
Based on careful analysis of popular graphs, Synopsys has determined that CNN calculations on common classification graphs currently deliver acceptable accuracy down to 10-bit integer precision in many cases (Figure 5). The EV6x vision processor's CNN engine therefore supports highly optimized 12-bit multiplication operations. Caffe framework-sourced graphs utilizing 32-bit floating-point outputs can, by using vendor-supplied conversion utilities, be mapped to the EV6x 12-bit CNN architecture without need for retraining and with little to no loss in accuracy. Such mapping tools convert the coefficients and graphs output by the software framework during initial training into formats recognized by the embedded vision system for deployment purposes. Automated capabilities like these are important when already-trained graphs are available and retraining is undesirable.

Figure 5. An analysis of CNNs on common classification graphs suggests that they retain high accuracy down to at least 10-bit calculation precision (courtesy Synopsys).
Encouragingly, software framework developers are beginning to pay closer attention to the needs of not only PCs but also embedded systems. In the future, therefore, it will likely be possible to directly train (and retrain) graphs for specific integer bit resolutions; 8-bit and even lower-resolution multiplications will further save cost, power consumption and bandwidth.
Framework Optimizations for FPGA Acceleration
Heterogeneous SoCs that combine high performance processors and programmable logic are also finding increasing use in embedded vision systems (Figure 6). Such devices leverage programmable logic's highly parallel architecture in implementing high-performance image processing pipelines, with the processor subsystem managing high-level functions such as system monitoring, user interfaces and communications. The CPU-plus-FPGA combination delivers a flexible and responsive system solution.
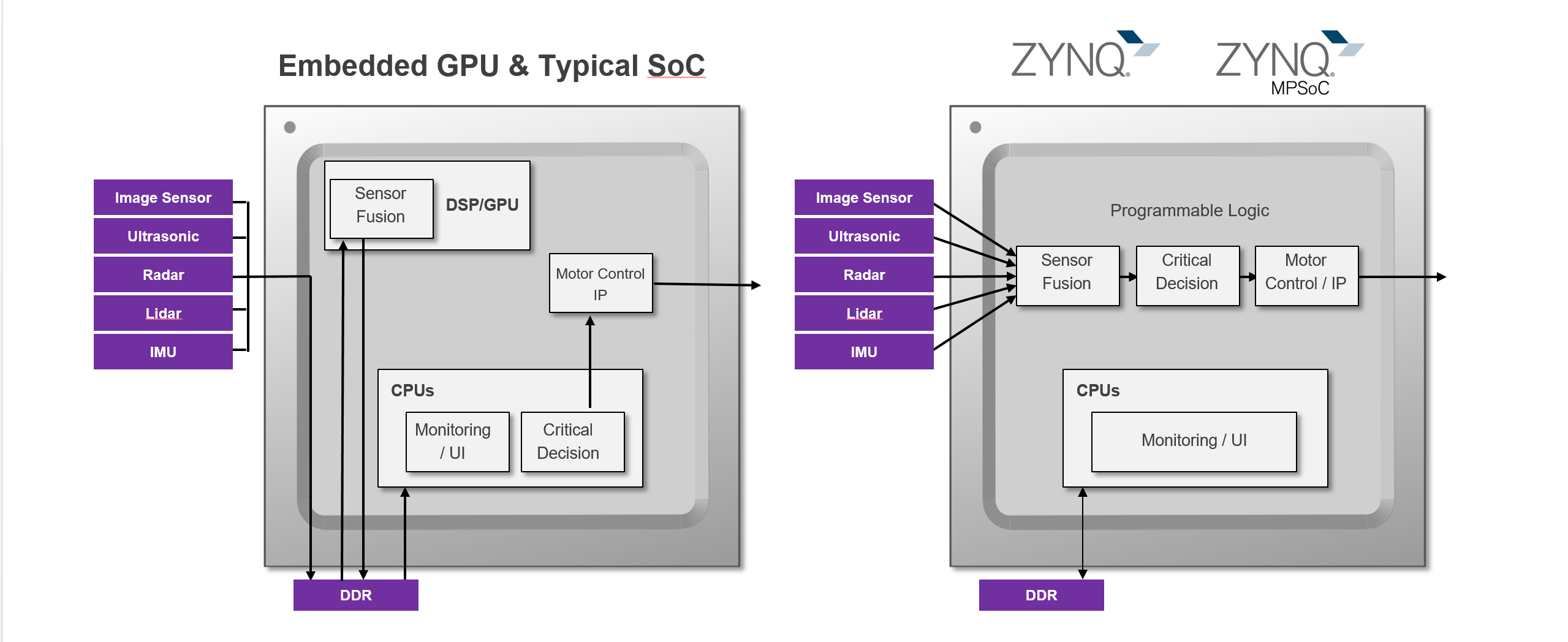
Figure 6. GPUs (left) and FPGA fabric (right) are two common methods of accelerating portions of deep learning functions otherwise handled by a CPU (courtesy Xilinx).
To gain maximum benefit from such a heterogeneous SoC, the user needs to be able to leverage industry standard frame works such as Caffe for machine learning, as well as OpenVX and OpenCV for image processing. Effective development therefore requires a tool chain that not only supports these industry standards but also enables straightforward allocation (and dynamic reallocation) of functionality between the programmable logic and the processor subsystems. Such a system-optimizing compiler uses high-level synthesis (HLS) to create the logic implementation, along with a connectivity framework to integrate it with the processor. The compiler also supports development with high-level languages such as C, C++ and OpenCL.
Initial development involves implementing the algorithm solely targeting the processor. Once algorithm functionality is deemed acceptable, the next stage in the process is to identify performance bottlenecks via application profiling. Leveraging the system-optimizing compiler to migrate functions into the programmable logic is a means of relieving these bottlenecks, an approach which can also reduce power consumption.
In order to effectively accomplish this migration, the system-optimizing compiler requires the availability of predefined implementation libraries suitable for HLS, image processing, and machine learning. Some toolchains refer to such libraries as middleware. In the case of machine learning within embedded vision applications, both predefined implementations supporting machine learning inference and the ability to accelerate OpenCV functions are required. Xilinx's reVISION stack, for example, provides developers with both Caffe integration capabilities and a range of acceleration-capable OpenCV functions (including the OpenVX core functions).
reVISION’s integration with Caffe for implementing machine learning inference engines is as straightforward as providing a prototxt file and the trained weights; Xilinx's toolset handles the rest of the process (Figure 7). This prototxt file is finds use in configuring the C/C++ scheduler running on the SoC's processor subsystem, in combination with hardware-optimized libraries within the programmable logic that accelerate the neural network inference. Specifically the programmable logic implements functions such as Conv, ReLu and Pooling. reVISION's integration with industry-standard embedded vision and machine learning frameworks and libraries provides development teams with programmable logic's benefits without the need to delve deep into the logic design.
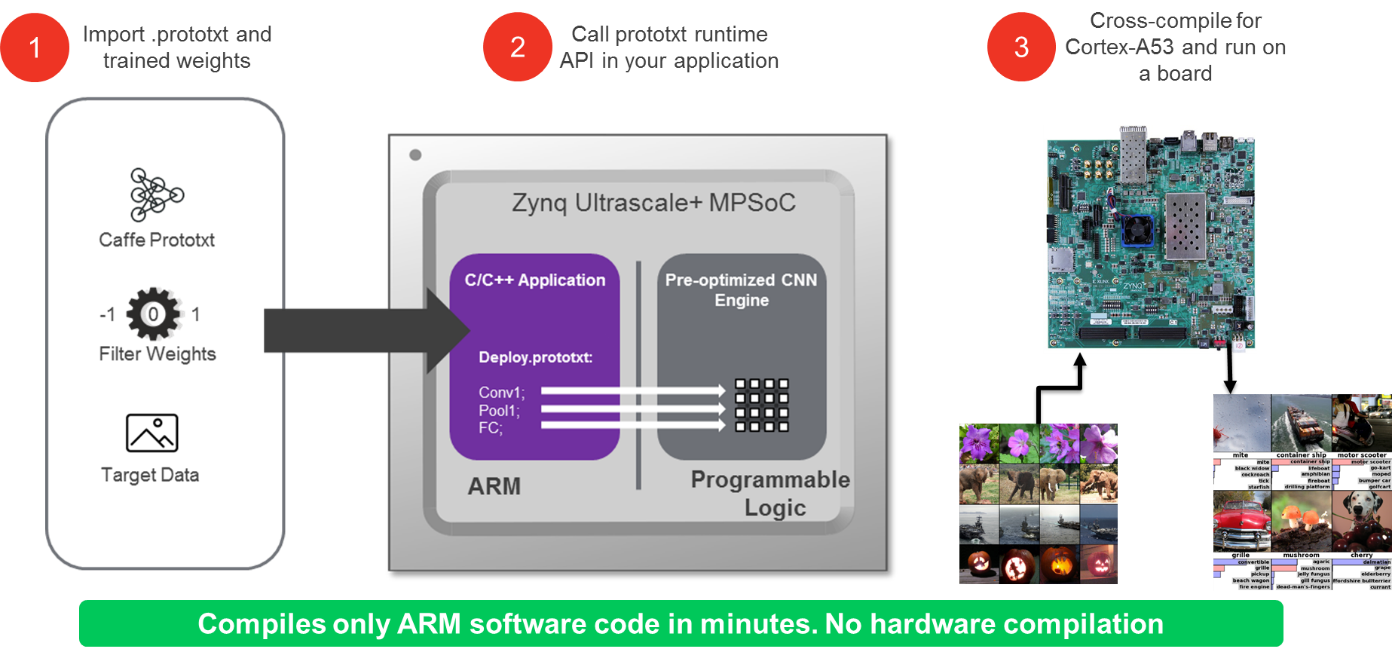
Figure 7. Accelerating Caffe-based neural network inference in programmable logic is a straightforward process, thanks to reVISION stack toolset capabilities (courtesy Xilinx).
Deep Learning-based Application Software
Industry 4.0, an "umbrella" term for the diversity of universally connected and high-level automated processes that determine everyday routines in modern production enterprises, is one example of a mainstream computer vision application that has attracted widespread developer attention. And deep learning-based technologies, resulting in autonomous and self-adaptive production systems, are becoming increasingly more influential in Industry 4.0. While it's certainly possible to develop applications for Industry 4.0 using foundation software frameworks, as discussed elsewhere in this article, a mature, high volume market such as this one is also served by deep learning-based application software whose "out of box" attributes reduce complexity.
MVTec's machine vision software products such as HALCON are one example. The company's software solutions run both on standard PC-based hardware platforms and on ARM-based processor platforms, such as Android and iOS smartphones and tablets and industry-standard smart cameras. In general, they do not require customer-specific modifications or complex customization. Customers can therefore take advantage of deep learning without having any specialized expertise in underlying technologies, and the entire rapid-prototyping development, testing and evaluation process runs in the company's interactive HDevelop programming environment.
Optical character recognition (OCR) is one specific application of deep learning. In a basic office environment, OCR is used to recognize text in scanned paper documents, extracting and digitally reusing the content. However, industrial use scenarios impose much stricter demands on OCR applications. Such systems must be able to read letter and/or number combinations printed or stamped onto objects, for example. The corresponding piece parts and end products can then be reliably identified, classified and tracked. HALCON employs advanced functions and classification techniques that enable a wide range of characters to be accurately recognized even in challenging conditions, thus addressed the stringent requirements that need to be met by a robust solution in industrial environments.
In environments such as these, text not only needs to be identified without errors under varied lighting conditions and across a wide range of fonts, it must also be accurately recognized even when distorted due to tilting and when smudged due to print defects. Furthermore, text to be recognized can be in a blurry condition and printed onto or etched into reflective surfaces or highly textured color backgrounds. With the help of deep learning technologies, OCR accuracy can be improved significantly. By utilizing a standard software solution like MVTec's HALCON, users are unburdened from the complex and expensive training process. After all, huge amounts of data are generated during training, and hundreds of thousands of images are required for each class, all of which have to be labeled.
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers (see sidebar "Additional Developer Assistance"). Deep learning-based vision processing is an increasingly popular and robust alternative to classical computer vision algorithms; conversion, partitioning, evaluation and optimization toolsets enable efficient retargeting of originally PC-tailored deep learning software frameworks for embedded vision implementations. These frameworks will steadily become more inherently embedded-friendly in the future, and applications that incorporate deep learning techniques will continue to be an attractive alternative approach for vision developers in specific markets.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Brad Scott
President, Au-Zone Technologies
Amit Shoham
Distinguished Engineer, BDTI
Johannes Hiltner
Product Manager for HALCON Embedded, MVTec Software GmbH
Gordon Cooper
Product Marketing Manager for Embedded Vision Processors, Synopsys
Giles Peckham
Regional Marketing Director, Xilinx
Sidebar: Leveraging GPU Acceleration for Deep Learning Development and Deployment
The design example that follows leverages the GPU core in a SoC to accelerate portions of deep learning algorithms which otherwise run on the CPU core. The approach discussed is an increasingly common one for heterogeneous computing in embedded vision, given the prevalence of robust graphics subsystems in modern application processors. These same techniques and methods also apply to the custom hardware acceleration blocks available in many modern SoCs.
Dataset Creation, Curation and Augmentation
A fundamental requirement for deep learning implementations is to source or generate two independent datasets: one suitable for network training, and the other to evaluate the effectiveness of the training. To ensure that the trained model is accurate, efficient and robust, the training dataset must be of significant size; it's often on the order of hundreds of thousands of labeled and grouped samples. One widely known public dataset, ImageNet, encompasses 1.5 million images across 1,000 discrete categories or classes, for example.
Creating large datasets is a time-consuming and error-prone exercise. Avoid these common pitfalls in order to ensure efficient and accurate training:
- Avoid incorrect annotation labels. This goal is much harder to achieve than might seem to be the case at first glance, due to inevitable human interaction with the high volume of data. It's unfortunately quite common to find errors in public datasets. Using advanced visualization and automated inspection tools greatly helps in improving dataset quality (Figure A).
- Make sure that the dataset represents the true diversity of expected inputs. For example, imagine training a neural network to classify images of electronic components on a circuit board. If you’ve trained it only with images of components on green circuit boards, it may fail when presented with an image of a component on a brown circuit board. Similarly, if all images of diodes in the training set happen to also have a capacitor partly visible at the edge of the image, the network may inadvertently learn to associate the capacitor with diodes, and fail to classify a diode when a capacitor is not also visible.
- In many cases, it makes sense to generate image samples from video as a means of quickly populating datasets. However, in doing so you must take great care to avoid reusing annotations from a common video sequence for both the training and testing databases. Such a mistake could lead to high training scores that can't be replicated by real-life implementations.
- Dataset creation should be an iterative process. You can greatly improve the trained model if you inspect the error distribution and optimize the training dataset if you find that certain classes are unrepresented or misclassified. Keeping dataset creation in the development loop allows for a better overall solution.
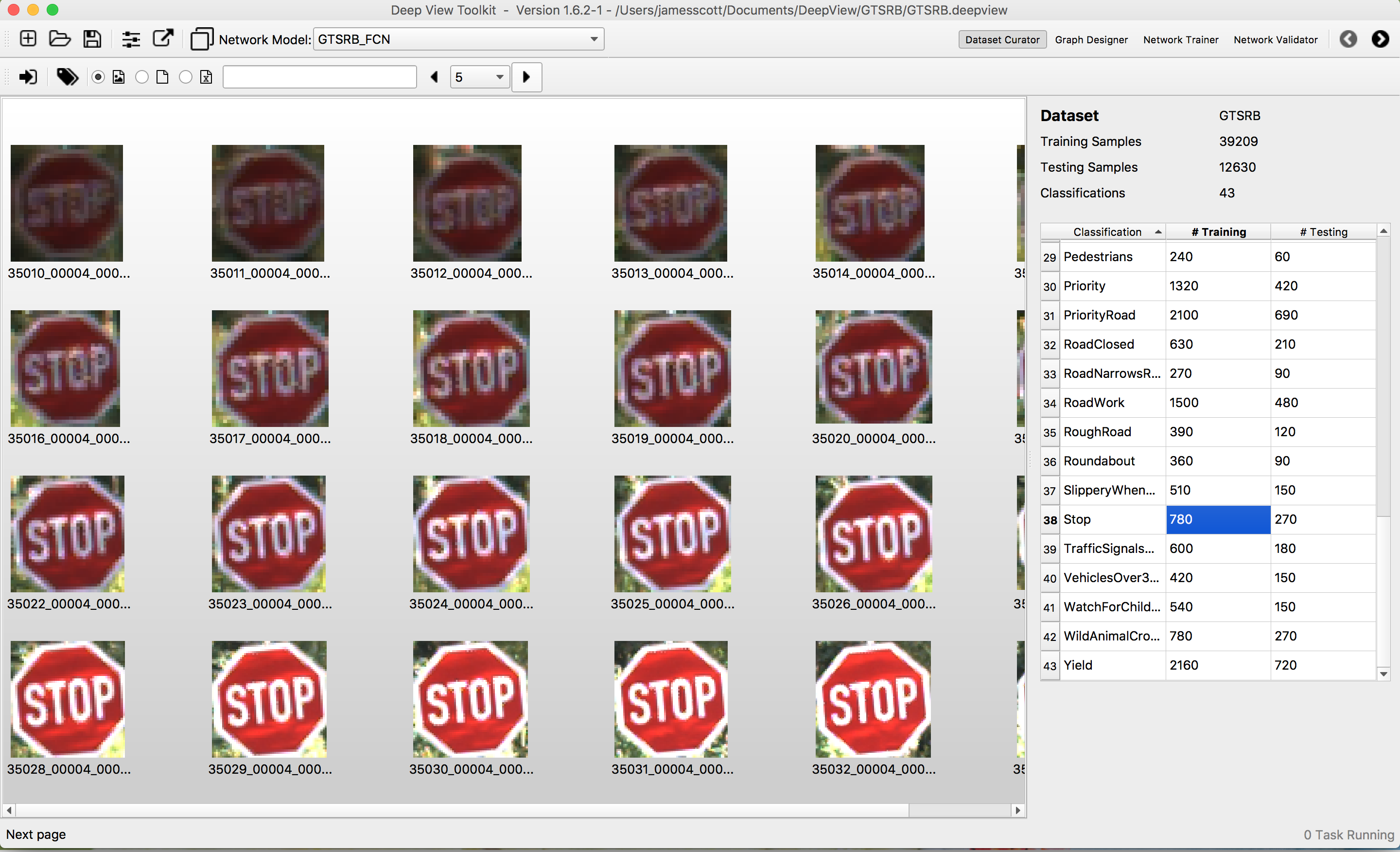
Figure A. DeepView's Dataset Curator Workspace enables visual inspection to ensure robustness without redundancy (courtesy Au-Zone Technologies).
For image classification implementations, in addition to supplying a sufficient number of samples, you should ensure that the dataset accurately represents information as captured by the end hardware platform in the field. As such, you need to comprehend the inevitable noise and other sources of variability and error that will be introduced into the data stream when devices are deployed into the real world. Randomly introducing image augmentation into the training sample set is one possible technique for increasing training data volume while improving the network's robustness, i.e. ensuring that the network is trained effectively and efficiently (Figure B).
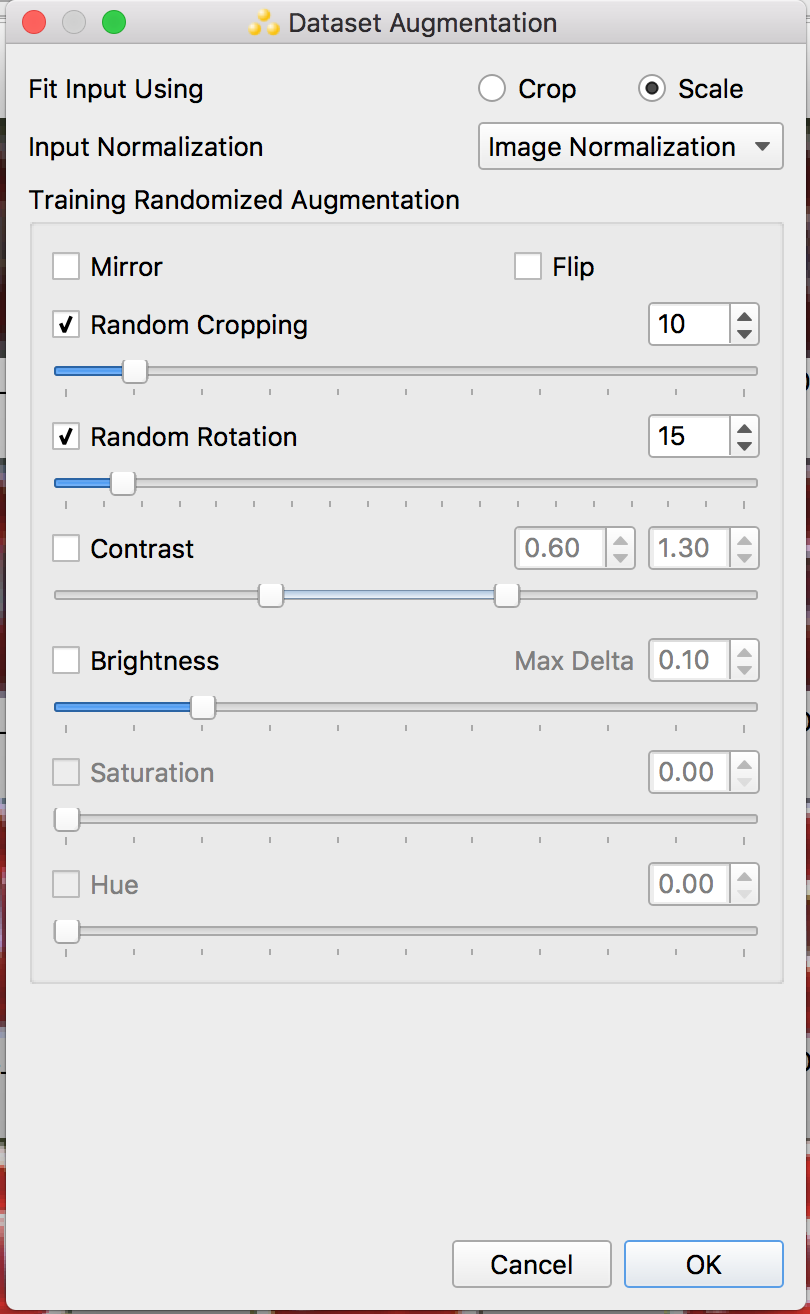
Figure B. Random image augmentation can enhance not only the training sample set size but also its effectiveness (courtesy Au-Zone Technologies).
The types of augmentation techniques employed, along with the range of parameters used, both require adaptation for each application. Operations that make sense for solving some problems may degrade results in others. One simple example of this divergence involves horizontally flipping images; doing so might improve training for vehicle classification, but it wouldn’t make sense for traffic sign classification where numbers would then be incorrectly reversed in training.
Datasets are often created with images that tend to be very uniformly cropped, and with the objects of interest neatly centered. Images in real-world applications, on the other hand, may not be captured in such an ideal way, resulting in much greater variance in the position of objects. Adding randomized cropping augmentation can help the neural network generalize to the varied real-world conditions that it will encounter in the deployed application.
Network Design
Decades of research in the field of artificial neural networks have resulted in many different network classes, each with a variety of implementations (and variations of each) optimized for a diverse range of applications and performance objectives. Most of these neural networks have been developed with the particular objective of improving inference accuracy, and they have typically made the assumption that run time inference will be performed on a server- or desktop-class computer. Depending on the classification and/or other problem(s) you need to solve for your embedded vision project, exploring and selecting among potential network topologies (or alternatively designing your own) can therefore be a time consuming and otherwise challenging exercise.
Understanding which of these networks provides the "best" result within the constraints of the compute, dataflow and memory footprint resources available on your target adds a whole new dimension to the complexity of the problem. Determining how to "zero in" on an appropriate class of network, followed by a specific topology within that class, can rapidly become time-consuming endeavor, especially so if you're attempting to do anything other than solve a "conventional" deep learning image classification problem. Even when using a standard network for conventional image classification, many system considerations bear attention:
- The image resolution of the input layer can significantly impact the network design
- Will your input be single-channel (monochromatic) or multi-channel (RGB, YUV)? This is a particularly important consideration if you’re going to attempt transfer learning (to be further discussed shortly), since you’ll start with a network that was either pre-trained with color or monochrome data, and there’s no simple way to convert that pre-trained network from one format to another. On the other hand, if you’re going to train entirely from scratch, it’s relatively easy to modify a network topology to use a different number of input channels, so you can just take your network of choice and apply it to your application’s image format.
- Ensure that the dataset format matches what you’ll be using on your target
- Are pre-trained models compatible with your dataset, and is transfer learning an option?
When developing application-specific CNNs intended for deployment on embedded hardware platforms, it’s often once again very challenging to know where to begin. Leveraging popular network topologies such as ResNet and Inception will often lead to very accurate results in training and validation, but will often also require the compute resources of a small server to obtain reasonable inference times. As with any design optimization problem, knowing roughly where to begin, obtaining direct feedback on key performance indicators during the design process, and profiling on target hardware to enable rapid design iterations are all key factors to quickly converging on a deployable solution.
When designing a network to suit your specific product requirements, some of the key network design parameters that you will need to evaluate include:
- Overall accuracy when validated both with test data and live data
- Model size: number of layers, weights, bits/weight, MACs/image, total memory footprint/image, etc.
- The distribution of inference compute time across network layers (scene graph nodes)
- On-target inference time
- Various other optimization opportunities
The Network Designer in the DeepView ML Toolkit allows users to select and adapt from preexisting templates for common network topologies, as well as to quickly create and explore new network design topologies (Figure C). With more than 15 node types supported, the tool enables quick and easy creation and configuration of scene graph representations of deep neural networks for training.
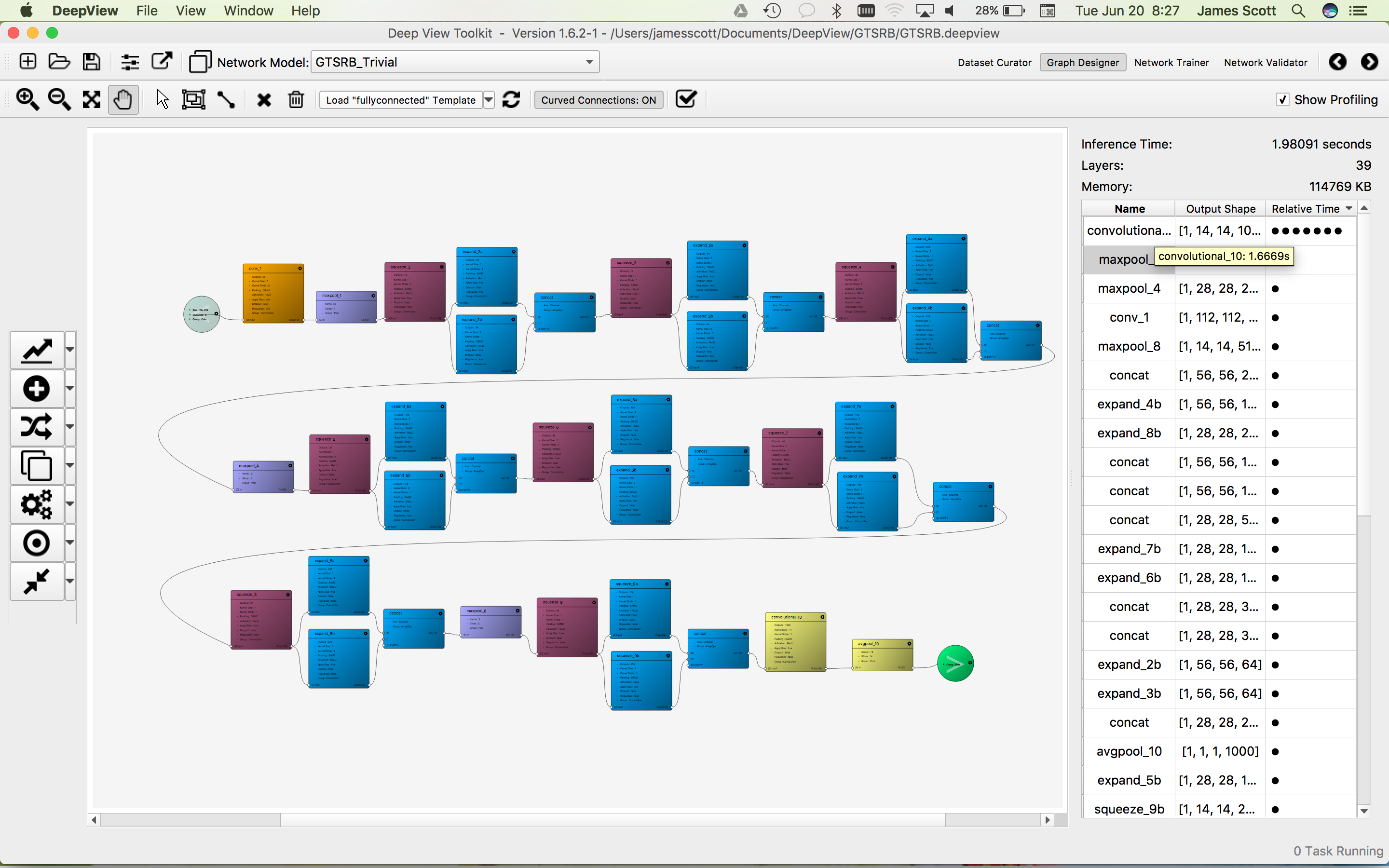
Figure C. The DeepView Network Design Workspace supports both customization of predefined network topologies and the creation of new scene graphs (courtesy Au-Zone Technologies).
Network Training
Training a network can be a tedious and repetitive process, with iteration necessary each time the network architecture is modified or the dataset is altered. The time required to train a model is directly impacted by the complexity of the network and the dataset size, and typically ranges from a few minutes to multiple days. Monitoring the loss value and a graph of the accuracy at each epoch helps developers to visualize the training session's efficiency.
Obtaining a training trend early in the process allows developers to save time by aborting training sessions that are not training properly (Figure D). Archiving training graphs for different training sessions is also a great way of analyzing the impact of: dataset alterations, network modifications and training parameter adjustments.

Figure D. Visually monitoring accuracy helps developers easily assess any particular training session's effectiveness (courtesy Au-Zone Technologies).
Transfer learning is a powerful method for optimizing network training. It's conceptually similar to the problem a developer would normally have with a dataset that's too small to properly train a rich set of parameters. By using transfer learning, you're leveraging an existing network trained on a similar problem to solve a new problem. For example, you can leverage a network trained on the very general (and very large) ImageNet dataset to specifically classify types of furniture with much less training time and effort than would otherwise be needed.
By importing a model already trained on a large dataset and freezing its earlier layers, a developer can then re-train the later network layers against a significantly smaller dataset, targeting the specific problem to be solved. Note, however, that such early-layer freezing isn't always the optimum approach; in some applications you might obtain better results by allowing the earlier network to learn the features of the new application.
And while dataset size reduction is one key advantage of transfer learning, another critical advantage is the potential reduction in training time. When training a network "from scratch," it can take a very long time to converge on a set of weights that delivers high accuracy. Via transfer learning, in summary, you can (depending on the application) use a smaller dataset, train for fewer iterations, and/or reduce training time by training only the last few layers of the network,.
Model Validation and Optimization
Obtaining sufficiently high accuracy on the testing dataset is a leading indicator of the network performance for a given application. However, limiting the result analysis to global score monitoring isn’t sufficient. In-depth analysis of the results is essential to understand how the network currently behaves and how to make it perform better.
Building a validation matrix is a solid starting point to visualize the error distribution among classes (Figure E). Filtering validation results is also an effective way to investigate the dataset entries that perform poorly, as well as to understand error validity and identify pathways to resolution.
Figure E. Graphically analyzing the error distribution among classes, along with as filtering validation results, enables evaluation of dataset entries that perform poorly (courtesy Au-Zone Technologies).
Many applications can also benefit from hierarchically ordering the classification labels used for analyzing the groups' accuracy. A distracted driving application containing 1 safe class and 9 unsafe classes, for example, could have mediocre overall classification accuracy but still be considered sufficient if the "safe" versus "unsafe" differentiation performs well.
Runtime Inference Accuracy and Performance Tuning
As the design and training activities begin to converge to acceptable levels in the development environment, target runtime inference optimization next requires consideration. The deep learning training frameworks discussed in the main article provide a key aspect of the overall solution, but leave the problem of implementing and optimizing the runtime to the developer. While general-purpose runtime implementations exist, they frequently do a subpar job of addressing several important aspects of deployment:
- Independence between the network model and runtime inference engine
Separation of these two items enables independent optimization of the engine for each supported processor architecture option. Compute elements within each unique SoC, such as the GPU, vision processor, memory interfaces and other proprietary IP, can be fully exploited without concern for the model that will be deployed on them. - The ability to accommodate NNEF-based models
Such a capability allows for models created with frameworks not directly supported by tools such as DeepView to be alternatively imported using an industry-standard exchange format. - Support for multiple, preloaded instantiations
Enabling multiple networks on single device via fast context switching is desirable when a single device is required to perform a plurality of deep learning tasks but does not have the capacity to perform them concurrently. - Portability between devices
Support for any OpenCL 1.2-capable device enables the DeepView Inference Engine (for example) to be highly portable, easily integrated into both existing and new runtime environments with minimal effort. Such flexibility enables straightforward device benchmarking and comparison during the hardware-vetting process. - Development tool integration
The ability to quickly and easily profile runtime performance, validate accuracy, visualize results and return to network design for refinement becomes extremely helpful when iterating on final design details.
In applications where speed and/or power consumption are critical, optimization considerations for these parameters should be comprehended in the network design and training early in the process. Once you have a dataset and an initial network design that trains with reasonable accuracy, you can then explore tradeoffs in accuracy vs. # of MACs, weights, types of activation layers used, etc., tuning these parameters for the target architecture.
Provisioning For Manufacturing and Field Updates
When deploying working firmware to the field, numerous steps require consideration in order to ensure integrity and security at the end devices. Neural network model updates present additional challenges to both the developer and system OEM. Depending on the topology of the network required for your application, for example, trained models range from hundreds of thousands to many millions of parameters. When represented as half-floats, these models typically range from tens to hundreds of MBytes in size. And if the device needs to support multiple networks for different use cases or modes, the required model footprint further expands.
For all but the most trivial network examples, therefore, managing over-the-air updates quickly becomes unwieldy, time-consuming and costly, especially in the absence of a compression strategy. Standard techniques for managing embedded system firmware and binary image updates also don’t work well with network models, for three primary reasons:
- When models are updated, it’s "all or nothing". No package update equivalent currently exists to enable replacement of only a single layer or node in the network.
- All but the most trivial model re-training results in an incremental differential file that is equivalent in size to the original file.
- Lossless compression provides very little benefit for typical neural network models, given the highly random nature of the source data.
Fortunately, neural networks are relatively tolerant of noise, so lossy compression techniques can provide significant advantages. Figure F demonstrates the impact that lossy compression has on inference accuracy for 4 different CNN’s implemented using DeepView. Compression ratios greater than 80% are easily achievable for most models, with minimal degradation in accuracy. And with further adjustment to the network topology and parameter representations, compression ratios exceeding 90% are realistically achievable for practical, real-world network models.
Figure F. Deep learning models can retain high accuracy even at high degrees of lossy compression (courtesy Au-Zone Technologies).
A trained network model requires a significant investment in engineering time, encompassing the effort invested in assembling a dataset, designing the neural network, and training and validating it. When developing a model for a commercial product, protecting the model on the target and ensuring its authenticity are critical requirements. DeepView, for example, has addressed these concerns by providing a fully integrated certificate management system. The toolkit provides both graphical and command line interface options, along with both C- and Python-based APIs, for integration with 3rd-party infrastructure. Such a system ensures model authenticity as well as security from IP theft attempts.
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. Au-Zone Technologies, BDTI, MVTec, Synopsys and Xilinx, the co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance and its member companies periodically deliver webinars on a variety of technical topics. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Alliance website. Also, the Embedded Vision Alliance has begun offering "Deep Learning for Computer Vision with TensorFlow," a full-day technical training class planned for a variety of both U.S. and international locations. See the Alliance website for additional information and online registration.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, is intended for product creators interested in incorporating visual intelligence into electronic systems and software. The Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit took place in Santa Clara, California on May 1-3, 2017; a slide set along with both demonstration and presentation videos from the event are now in the process of being published on the Alliance website. The next Embedded Vision Summit is scheduled for May 22-24, 2018, again in Santa Clara, California; mark your calendars and plan to attend.