
Deep learning and other machine learning techniques have rapidly become a transformative force in computer vision. Compared to conventional computer vision techniques, machine learning algorithms deliver superior results on functions such as recognizing objects, localizing objects within a frame, and determining which pixels belong to which object. Even problems like optical flow and stereo correspondence, which had been solved quite well with conventional techniques, are now finding even better solutions using machine learning techniques. The pace of ongoing machine learning development remains rapid. And in comparison to traditional computer vision algorithms, it’s easier to create effective solutions for new problems without requiring a huge team of specialists. But machine learning is also resource-intensive, as measured by its compute and memory requirements. And for machine learning to deliver its potential, it requires a sufficient amount of high quality training data, plus developer knowledge of how to properly use it.
Imagine teaching someone how to bake a cake. You can do it by writing down instructions, or you can show them how it’s done and have them learn by example. This, in a nutshell, is the difference between traditional coding and machine learning: coding is like writing a recipe, whereas machine learning is teaching by example. If you teach cake baking by example, you’ll probably have to demonstrate the process many times before your student remembers all the details and can bake a cake on their own from memory. The process of baking a cake is conversely easy to describe with a recipe, but many other problems are very difficult to solve this same “recipe way.”
For example, how would you teach someone to discern between an image of a cat and an image of a dog? It would be practically impossible to write a “recipe” for cat-vs-dog classification; alternatively, though, with enough example images you could teach this skill in straightforward fashion. Many problems in computer vision and artificial intelligence that are impractical to solve with traditional coding and algorithms become solvable with deep learning or some other form of machine learning.
You can think of DNNs (deep neural networks) as universal approximators: they can be structured to map any input to any output (e.g., the input can be a picture, and the output can be the probabilities that the picture depicts a dog and a cat, respectively). When trained properly, they can provide a very good approximate solution to just about any problem you throw at them, under the important assumption that the network topology is a sufficiently effective match for the problem at hand. DNNs typically have a huge number of internal parameters—often millions of them. Training is the process by which you initially set all of these parameters in order that the network can then reliably solve a particular problem, like discerning cats vs. dogs.
Much industry attention is focused on machine learning inference, where a neural network analyzes new data it is presented with based on its previous training. But what about that prior, all-important training step? Obviously, training effectiveness is a critical factor in accuracy, responsiveness and other subsequent inference metrics. Without sufficient training, accuracy will inevitably suffer. But excessive training, using a data set that exceeds the scope of the images that the model will be tasked with interpreting in real-life usage, is also undesirable. Since training is highly compute-intensive, for example, an insufficiently bounded (i.e., limited, or constrained) data set will require more training time and cost than is necessary. The resultant model may also be more complex than required, translating into excessive memory budget and inference computation requirements.
This article discusses in detail the challenges of, as well as the means of, assembling a robust (but not excessive) training data set for machine learning-based vision processing. It answers fundamental questions such as why an optimized training set is important, what are the characteristics of an optimized training set, and how one assembles an optimized training set. And it also introduces readers to an industry alliance created to help product creators incorporate machine learning-based vision capabilities into their hardware and software, along with outlining the technical resources that this alliance provides (see sidebar “Additional Developer Assistance“).
Training Fundamentals
Much of the information in the next several sections of this article, covering foundational machine learning concepts, comes from BDTI.
Today, training of deep neural networks primarily occurs via a process called SGD (stochastic gradient descent). To begin, the network parameters are initialized to random values. The network is then provided with batches of example training inputs (e.g., pictures of cats and dogs). For each input, the model computes a corresponding output based on its current parameters. The computed output is compared to the expected correct output, with the error differential fed backward through the network. In this step, called back-propagation, an adjustment is computed for each of the network’s parameters in order to decrease the error.
The training process is repeated many times with hundreds, thousands, or even millions of example inputs. The intent is for the training process to gradually converge on a set of model parameters that provide an accurate solution to the problem at hand. Note that SGD as described here requires that you have a desired correct output (usually called a “labeled output”, e.g., “cat” or “dog”) associated with each example input. Machine learning performed using a combination of example inputs and their corresponding labels is called supervised learning. One of the critical challenges of machine learning, therefore, is finding or creating (or both) an effective dataset that contains correct examples and their corresponding output labels.
Several variations of the basic SGD optimization process are available that, in some cases, can assist the training in converging more rapidly and/or in reaching an end set of parameters that yields more accurate results. These SGD derivatives are called optimizers; examples include Adam, Adagrad, and RMSprop. And sometimes, rather than directly (and solely) training a DNN on the desired dataset, a combination of techniques can be employed.
In transfer learning, for example, a network that has already been trained with one dataset (e.g., ImageNet) is then re-trained with another dataset for a new application. However, in such cases, the parameters from the original training are used to initialize the new training, versus random data as previously discussed. If the training datasets are similar enough, the original parameters can provide a good starting point for retaining; it may even be possible to retain most of the parameters and retrain only the last few network model layers, Regardless, by using transfer learning when a network pre-trained on another similar dataset is available, the total training time can potentially be greatly reduced.
In unsupervised learning, techniques such generative adversarial networks and other autoencoders are used to train neural networks using data that lacks the annotation of a desired network output for each network input. Most often unsupervised learning (also referred to as training using unlabeled data) is combined with some supervised learning (training using labeled data), so some amount of annotated data is still needed. But the amount can sometimes be reduced by the use of unsupervised learning techniques, at least in theory.
At the moment, a significant amount of labeled data usually remains necessary in order to deploy a reliable DNN in a typical computer vision application. The primary drawback of labeled data, unfortunately, is that manual annotation of a large dataset can be expensive and time consuming. It’s therefore conceptually appealing to use unsupervised learning to reduce the amount of labeled data that’s necessary. Most current practical implementations rely mostly on annotated data, along with transfer learning. However, although unsupervised-centric training is comparatively uncommon today, research is ongoing on various techniques for improving its effectiveness.
Dataset Sources
Many annotated datasets are publicly available, although the licensing terms for most of them indicate that they are to be used only for academic or research purposes. Many of these datasets are application-specific, e.g. containing only faces, pedestrians, cars, etc. The quality of publically available datasets also varies greatly, and many of them are fairly small, i.e., on the order of 200 images, therefore perhaps not sufficient standalone to achieve reasonable accuracy for an application. While it’s conceivable to combine multiple public datasets into a larger set, this must be done with care; inconsistent annotation practices and other issues can result in an aggregated resulting dataset that isn’t very good.
Noteworthy resources of public datasets include:
- ImageNet: one of the best-known image datasets and a de-facto benchmark for assessing the quality of a DNN topology for image classification. For many well-known CNN (convolutional neural network, a common DNN class) topologies, models pre-trained with ImageNet are also publically available.
- OpenImages: a GitHub-served, Google-maintained database of ~9 million URLs that link to Creative Commons Attribution-licensed images. The database contains annotations, including labels and bounding boxes spanning thousands of categories. You can often create an application-specific dataset by selecting an appropriate subset of the database and then downloading the images.
Various websites also provide listings of open-source datasets. See, for example, the comprehensive CV Datasets on the Web page.
Some computer vision applications aren’t, however, adequately addressed by existing public datasets, whose various limitations may end up requiring the creation of a custom dataset instead. Sometimes, you can leverage Google’s OpenImages to create such a dataset, but other situations require the creation of a dataset “from scratch”. In some cases, this custom dataset development process involves sourcing new images. Examples might include:
- Industrial or medical applications, where the desired images aren’t available in the public domain
- Applications with unusual or tightly specified camera angles, lighting, optics and/or captured using custom sensors, that aren’t well represented in publicly available images
In other cases, existing images may be usable, but custom annotation is needed, e.g., when:
- Labels or bounding boxes are needed for categories not found in OpenImages
- Other types of annotation are needed, e.g., segmentation
Various companies offer dataset creation and/or annotation services (see sidebar “Benefits of Custom Datasets, and a Case Study“). Such suppliers may search the Internet for publically available images specific to the application, undertake image creation themselves, and/or accept images provided by the customer and annotate them. Some of these companies have spent substantial effort in creating software tools to make human annotation more efficient, as well as employing annotators in locations around the world where labor is inexpensive. Note, however, that creating a high-quality dataset requires careful planning, supervision, and quality control.
Shortcomings that you may encounter when creating and annotating a dataset (by yourself and/or in partnership with a vendor) include:
- Insufficient or incomplete data: Sometimes it’s difficult or impossible to capture enough data to cover the diversity of inputs that a real-life application will be expected to handle.
- Unbalanced data: A neural network will learn the statistical properties of the training data. If a network is trained to classify dog vs. cat on a dataset with ten times more dogs than cats, for example, it will learn that guessing “dog” every time nets it a 90% accuracy score. Such imbalances will ultimately limit the accuracy that the network can achieve.
- Misleading correlations: For example, if the previously mentioned dog vs. cat network is trained with images that always show dogs outside and cats indoors, that network will very likely produce incorrect results when instead shown a cat outdoors or a dog indoors. Similarly, an example from Google involved a CNN that had learned to associate dumbells with arms, because all the images of dumbells that the network had been trained with also included arms (from people doing curls).
- Inconsistent annotations: Should an antique bureau be classified as a “desk,” a “dresser,” or a “bookshelf?” Should a tuk-tuk on a street in Bangkok be classified as a “car” or “motorcycle?” For a single human annotator, it’s often easy to end up annotating very similar objects in very different ways. And when the annotation effort for a large dataset is split among people from different cultural backgrounds, who might speak different languages or dialects, this problem is compounded—sometimes severely. Inconsistent annotations mean that the neural network is then fed conflicting data during training, and is therefore unable to learn to accurately predict the correct answers.
To some extent these problems can be managed with good specifications, guidelines, and education of the people doing the data collection and annotation. However, it’s generally impossible to predict all of the corner cases, as well as the subtle issues that can arise in the course of collecting and annotating data. Very often it’s necessary to iterate a multi-step process multiple times:
- Collect and annotate an initial dataset
- Train a network
- Evaluate the errors that the network makes in the application, and determine what problems exist in the dataset that contribute to those errors
- Adjust the dataset (collect more data, correct inconsistent annotations, etc.) and return to step 2.
- Repeat until the desired accuracy is achieved.
Dataset Augmentation
Dataset augmentation is an “umbrella” term for an important set of techniques that can reduce the need for annotated data. It creates multiple variations of the same source image, via methods such as:
- Random cropping, rotation, and/or other random warps
- The addition of random color gradients
- Random blurring or non-linear transfer functions
Often these techniques are supported directly in machine learning frameworks, and can therefore be easily applied to every image automatically.
Sometimes it’s also useful to use augmentation techniques off-line to help correct dataset problems. For example, with an unbalanced dataset where a certain class of object occurs far less frequently than others, randomized perspective warps can be used to create additional images from the existing images in this particular class, resulting in a more balanced dataset. The following essay from Luxoft further explores the topic of dataset augmentation, including real-life examples from past design services projects.
Often, for reasons previously discussed in this article, we need more data to train our learnable models than we already have on hand, in order to improve the generalization capability of our models. The size of the training dataset has to be consistent with the model’s complexity, which is a function of both model architecture and the number of model parameters. DNN training, for example, is a form of MLE (maximum likelihood estimation), from a statistical point of view. This method is proven to work only in cases where the number of training data samples is orders of magnitude more than the number of model parameters.
Modern state-of-art DNNs typically comprise millions of weights, while training datasets such as ImageNet contain only about the same number of samples, or even fewer. Such situations represent a serious violation of the applicability of MLE methods, and lead to the reality that the majority of known DNN models are prone to overfitting (a phenomenon in which the model has been trained to work so well on training data that it begins working more poorly on data it hasn’t seen before). Recent research by Zhang et al. suggests that such DNNs, by simply memorizing the entire training dataset, are therefore capable of freely fitting (statistically approximating, i.e. modeling, a target function) even random labels.
Various regularization approaches are applicable in dealing with overfitting in the presence of a small trained dataset. Some of them are implicit, such as:
- A change in model architecture
- A change of the optimization algorithm used
- The use of early stopping during the training process (Yao et al.).
Techniques such as these, while helping to reduce overfitting, may not be sufficient. In such cases, explicit regularization approaches are often considered next:
- Weight decay (L1 and L2 regularizations)
- Dropout (Srivastava et al.) or dropconnect (Wan et al.)
- Batch normalization (Ioffe & Szegedy)
- Data augmentation, the primary focus of this essay
Explicit approaches can be applied separately or jointly, and in various combinations. Note, however, that their use doesn’t necessary lead to an improvement in model generalization capabilities. Applying them blindly, in fact, might even increase a model’s generalization error.
Data augmentation is a collection of methods used to automatically generate new data samples via the combination of existing samples and prior domain knowledge. Consider it as a relatively inexpensive means of drastically increasing the training dataset size, with the intent to decrease generalization error. Each separate augmentation method is usually designed to support invariance of (i.e. unchanging) model performance on corresponding cases of possible inputs. And you can divide them into supervised and unsupervised methods, as introduced previously in this article.
Unsupervised Data Augmentation
The family of unsupervised methods includes simple techniques such as (Figure 1):
- Geometric transformations: flipping, rotation, scaling, cropping, and distortions
- Photometric transformations: color jittering, edge-enhancement, and fancy PCA
Such techniques are found in many frameworks and third-party libraries.

Figure 1. Geometric and photometric augmentations applied to a mushroom image were implemented with help of the imgaug library (courtesy Luxoft).
Some of these augmentation methods can be considered as extensions of the concept of dropout, applied to the input data. Examples of such methods are cutout, from DeVries and Taylor, and random erasing, by Zhong et al. Common to both of these techniques is the application of a random rectangular mask to the training images; the cutout method uses zero-masking to normalized images, while the random erasing approach fills the mask with random noise (Figure 2). The masking of continuous regions of training data makes the model more robust to occlusions and less prone to overfitting. The latter provides a distinct decrease in test errors for state-of-the-art DNN architectures.


Figure 2. Common to both the cutout (top) and random erasing (bottom) unsupervised augmentation techniques is the application of a random rectangular mask to the training images (courtesy Luxoft).
The selection of an optimum data augmentation alternative depends not only on the learnable model and the training data but also on how the trained model is scored. Some augmentation methods are preferable from a recall perspective, for example, while others deliver better precision. A Luxoft vehicle detection test case compares precision-recall curves for common photometric (i.e. perceived light intensity-based) augmentation methods (Figure 3). Note that augmentation with too broad a range of parameter values (such as the violet curve in Figure 3) results in redundancy that degrades both precision and recall.
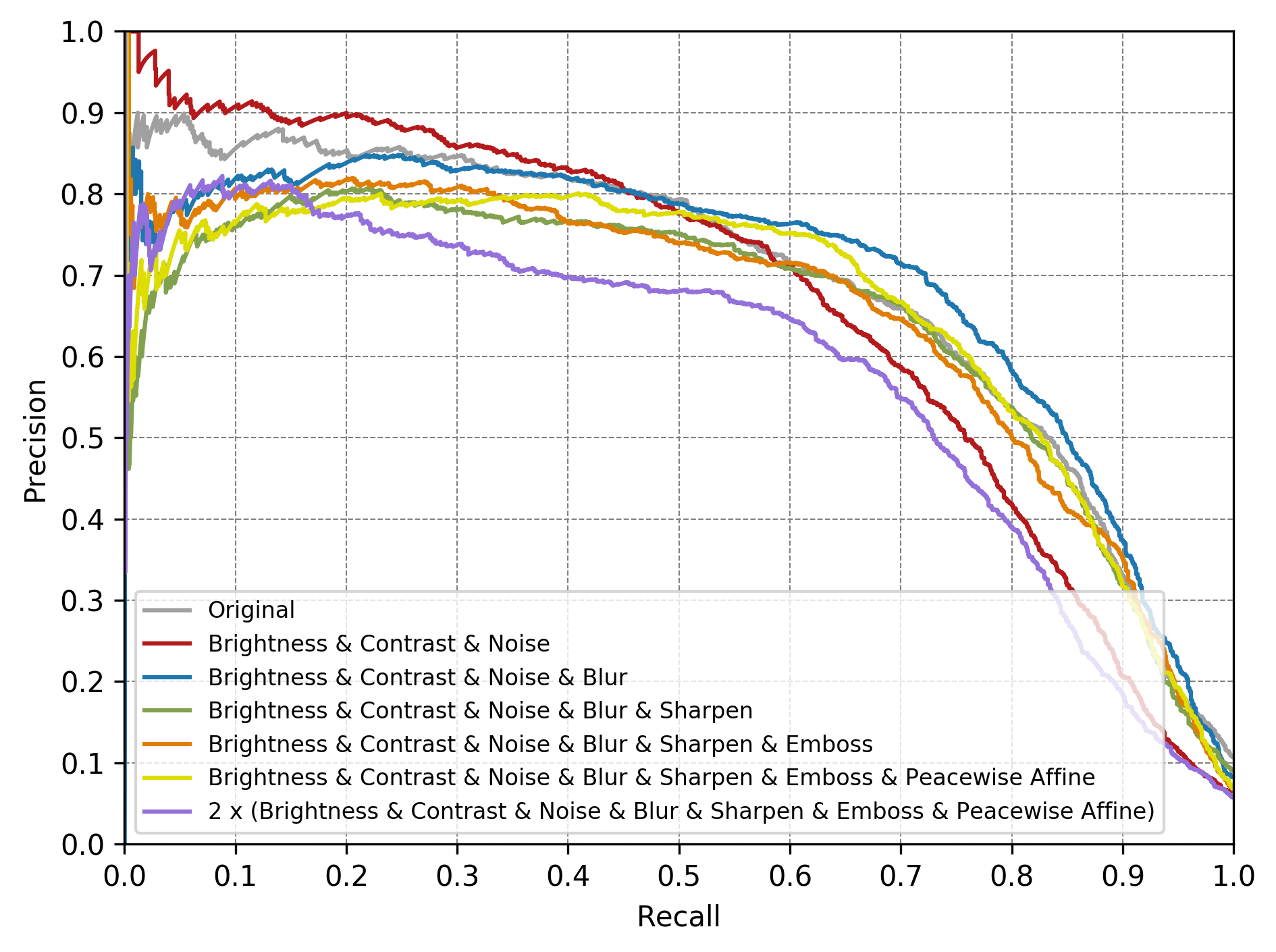
Figure 3. An example comparison of precision-recall curves corresponds to different photometric augmentations (courtesy Luxoft).
If, on the other hand, you focus on the IoU (intersection over union) evaluation metric, your comparison results may be completely different (Figure 4):
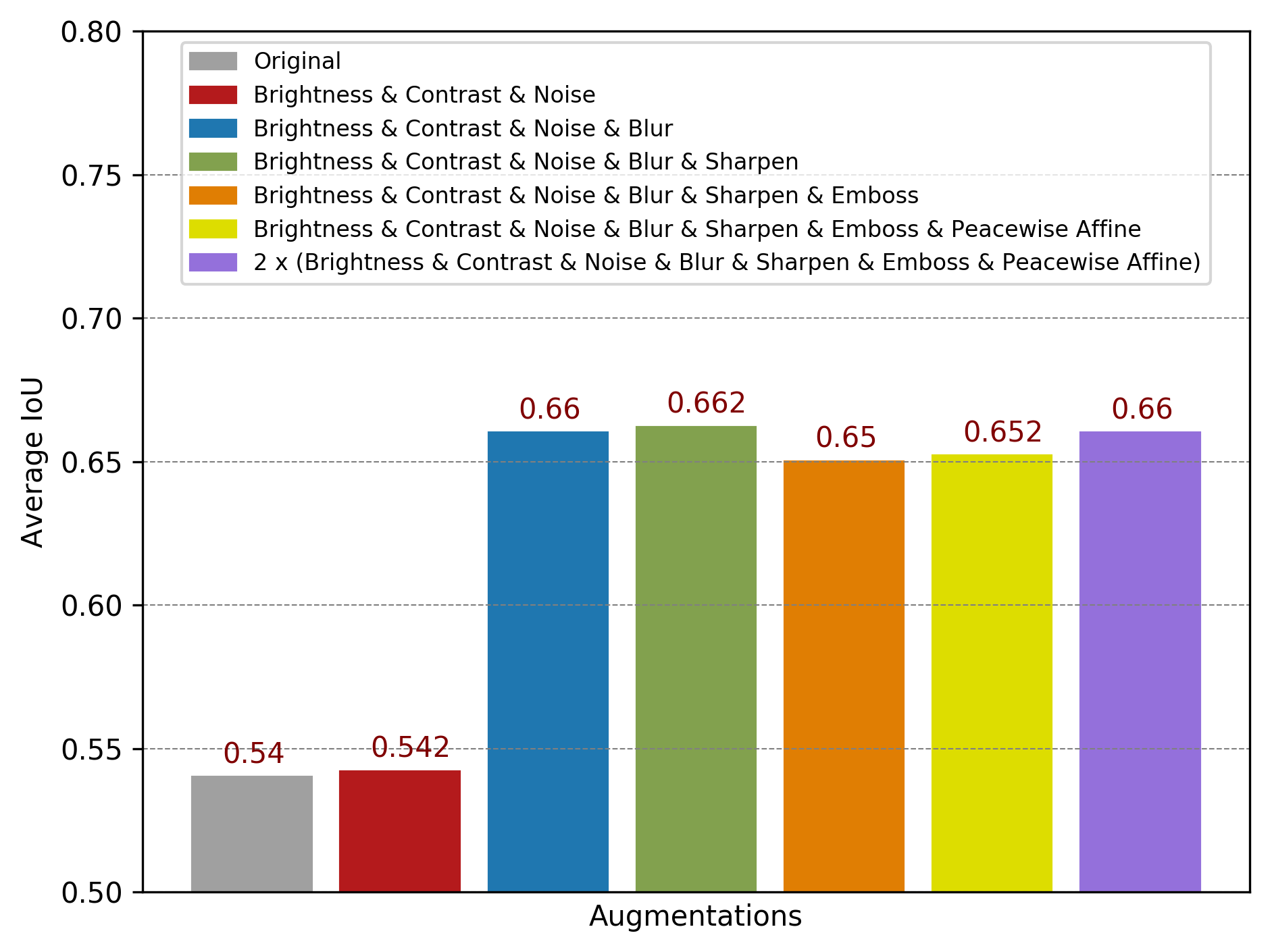
Figure 4. An example comparison of average IoU (intersection over union) corresponds to different photometric augmentations (courtesy Luxoft).
The excessive use of data augmentation has many negative side effects, beginning with increased required training time and extending to over-augmentation, when the differences between classes become indistinguishable.
In our experiments with pharmaceutical data, for example, we learned that data augmentation can lead to quality performance drops if not accompanied by proper shuffling of training data. Such shuffling finds use in avoiding correlation between samples in batches during the training process. The application of an effective shuffling algorithm, instead of simple random permutation, can result in both faster convergence of learning and higher accuracy on final validation (Figure 5).
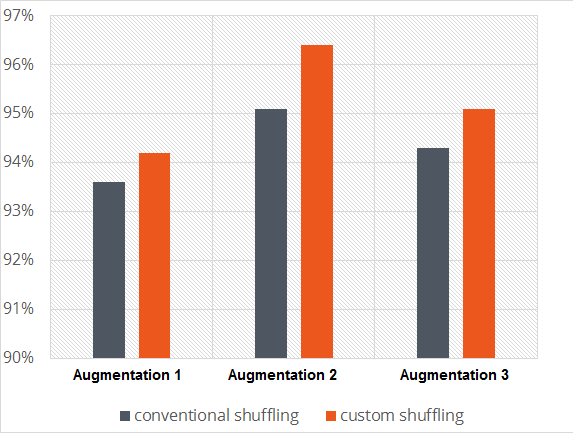
Figure 5. Proper shuffling algorithms can result in both faster convergence and higher accuracy for various augmented dataset types (courtesy Luxoft).
Augmentation techniques are especially useful when, for example, the dataset diverges from test data due to image quality or other a priori-known parameters such as various camera factors (ISO sensitivity and other image noise sources, white balance, lens distortion, etc.). In such cases, elementary image processing methods like those mentioned earlier in this essay can find use not only in increasing the amount of data available for training but also in making training data more consistent with test data, as well as reducing the cost of collecting and labeling new data.
However, use cases still exist where simple image processing is not sufficient to result in a training dataset that’s a close approximation of real data (Figure 6). In such complex cases, you may want to consider supervised augmentation techniques.


Figure 6. In some cases, image samples from training datasets (top) are insufficiently close approximations of real-life input counterparts (bottom) (courtesy Luxoft).
Supervised Data Augmentation
Supervised augmentation methods encompass both learnable and un-learnable approaches. One common example of the latter involves graphical simulation of data samples, such as the 3D simulation of a train car coupling from a past railway project (Figure 7).

Figure 7. In a case study example of un-learnable supervised data augmentation, 3D graphics simulations of a train car coupling (top and middle) found use in supplementing real-Iife images (bottom) (courtesy Luxoft).
Keep in mind that training the model on simulated samples, if not done carefully, can result in a model that overfits on details presented in simulated data, and is therefore not applicable to real-life situations. Note, too, that is not always necessary to simulate photorealistic data with synthetic data extensions (Figure 8).


Figure 8. In this case study example used for fish behavior classification, the synthetic data (top) derived from motion estimation algorithms (middle) was successfully used to train the DNN model, even though it was not at all realistic-looking to the human eye (bottom). (courtesy Luxoft).
Learnable augmentation methods leverage an auxiliary generative model that is “learned” in order to produce the new data samples. The best-known examples of this approach are based on the GAN (generative adversarial nets) concept, proposed initially by Goodfellow et al. The primary characteristic of these methods is the simultaneous training of two neural networks. One neural network strives to generate images that are similar to natural ones, while the other network learns to detect imitation images. The training process completes when generated images are indistinguishable from real image samples.
Shrivastava et al. and Liu et al. applied the GAN approach in order to generate highly realistic images from simulated ones, thereby striving to eliminate a primary drawback of using simulation in data augmentation. Also, Szegedy et al. and Goodfellow et al. observed that the generation of realistic images is not the sole way of improving generalization. They proposed the use of adversarial samples, which had been initially designed to trick learning models. Extending a training dataset by means of such samples, intermixed with real ones, can decrease overfitting.
Finally, Lemley et al. have introduced a novel neural approach to augmentation, which connects the concepts of GAN and adversarial samples in order to produce new image samples. This approach uses a separate augmentation network that is trained jointly with the target classification network. The process of training is as follows:
- At least three images of same class are randomly selected from the original dataset.
- All selected images, except for one, are treated as input to the augmentation network, which produces a new image with the same size.
- The output image is compared with the remaining one from the previous step to generate a similarity (or loss) metric for the augmentation network. The authors suggest using MSE (mean squared error) as the metric.
- Both compared images are then fed into the target classification network, with the loss computed as categorical cross-entropy.
- Both losses (augmentation and classification) are merged together by means of various weighting parameters. Merged loss may also depend on the epoch number.
- The total loss back-propagates from the classification network to the augmentation network. As a result, the last network finds use in generating optimum augmented images for the first network.
The presented approach doesn’t attempt to produce realistic data. Instead, the joint information between merged data samples is employed to improve the generalization capability of the target learnable model.
Potemkin Andrey
Deep Learning Engineer, Luxoft
Sergey Fedorov
Program Manager, Luxoft
Valiev Ildar
Deep Learning Engineer, Luxoft
Synthetic Datasets
In some cases it may be practical to synthetically (artificially) generate some or all of a dataset. For example, in an industrial inspection application, 3D models of objects to be analyzed may already exist. These models can be used to render additional artificial images with different lighting conditions, camera angles, imperfections, etc. Because the data is generated from a model, all annotations can be automatically generated too; the annotation effort is replaced by programming effort. One interesting example of this technique is the “flying chairs” dataset, which uses 3D models of chairs to create an artificial dataset via optical flow annotation. The following essay from AImotive further explores this topic, including its use in developing and refining the company’s autonomous vehicle control software.
In 2015, AImotive set out to create an AI-based camera-first self-driving solution. We knew that merging computer vision with artificial intelligence would offer unique capabilities. Simply put, any sensor setup would benefit from AI. But using it with computer vision would allow aiDrive to precisely predict the behavior of human drivers, pedestrians, animals and other object around a vehicle.
However, as previously discussed in this article, training neural networks requires a massive amount of data. Furthermore, each network has to be trained on data sets that are curated and otherwise customized to the specific purpose of the network. These basic difficulties are only emphasized by the safety-critical nature of self-driving. And to further complicate matters, the data sets must also be variable. Only when trained on a variety of images from different environments will a network achieve the necessary accuracy to support full autonomy.
To address these challenges, AImotive developed a semi-automated annotation tool to create data sets. How images are processed in the tool is itself specific to the goal of the data set. aiDrive, our autonomous driving software suite, currently uses AI-based systems for lane detection, object and free space segmentation, bounding boxing, and depth estimation. Images for lane detection training are relatively easy to generate. Lanes are marked on key frames and then propagated through the video stream. Segmentation is aided by non-real-time, high-precision segmentation networks that pre-analyze complete image sequences.
Our annotation team then scours the data set to correct any mistakes. To assist with bounding boxing, each instance of an object is marked separately. Based on this pixel-precise segmentation, bounding boxing is fully automated. Raw ground truth data from LIDAR and stereo cameras is used to train depth estimation algorithms. While the depth training data is relatively easy to collect, the benefits of having distance estimation algorithm that uses only a single camera are huge. In case one camera’s vision is degraded in the stereo setup, for example, the depth information of the surroundings will help in stopping the car safely.
AImotive follows a test-oriented development plan. In this, all systems undergo rigorous testing in aiSim, our photorealistic simulator. Only after they are deemed safe do we test them on public roads. The simulator also gives our team immediate feedback on our neural networks and the quality of our data sets. Tracking the effectiveness of our training through this internal feedback loop gives us the flexibility to improve our data sets in a relatively short timeframe, if needed.
Bence Varga
Business Development Manager, AImotive
Conclusion
Vision technology is enabling a wide range of products that are more intelligent and responsive than before, and thus more valuable to users. Vision processing can add valuable capabilities to existing products, and can provide significant new markets for hardware, software and semiconductor suppliers. Machine learning-based vision processing is an increasingly popular and robust alternative to classical computer vision algorithms, but it tends to be comparatively resource-intensive, which is particularly problematic for resource-constrained embedded system designs. However, by optimizing the various characteristics of the dataset used to initially train the network, it’s possible to develop a machine learning-based embedded vision design that achieves necessary accuracy and inference speed levels while still meeting size, weight, cost, power consumption and other requirements.
Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Senior Analyst, BDTI
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. AImotive, BDTI, iMerit and Luxoft, the co-authors of this article, are members of the Embedded Vision Alliance. The Embedded Vision Alliance’s mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance’s annual technical conference and trade show, the Embedded Vision Summit, is coming up May 22-24, 2018 in Santa Clara, California. Intended for product creators interested in incorporating visual intelligence into electronic systems and software, the Embedded Vision Summit provides how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. The Embedded Vision Summit is intended to inspire attendees’ imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings. More information, along with online registration, is now available.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other machine learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance and its member companies periodically deliver webinars on a variety of technical topics, including various machine learning subjects. Access to on-demand archive webinars, along with information about upcoming live webinars, is available on the Alliance website. Also, the Embedded Vision Alliance is offering offering “Deep Learning for Computer Vision with TensorFlow,” a series of both one- and three-day technical training class planned for a variety of both U.S. and international locations. See the Alliance website for additional information and online registration.
Sidebar: The Benefits of Custom Training Datasets, and a Case Study
The following essay from iMerit, a provider of custom dataset and annotation services, further explores themes introduced in the main article regarding the importance of a relevant and comprehensive training dataset, as well as detailing the company’s experiences with one of its clients.
More high quality training data leads to higher inference accuracy in model outputs, as the main article’s discussion introduces. While numerous sources of large-scale “open” data now exist, producing a market-ready product may still require the use of a robust, high-quality, high-volume custom training dataset, particularly when licensing restrictions preclude the commercial use of open-source images.
The race to artificial intelligence-based problem-solving is very real, with major industry investments joining with academic breakthroughs to lead to dramatic advances in machine learning scalability and open-source modeling approaches. These advancements are accelerating the speed at which new technologies and products derived from them are created and deployed, but the models they’re based on aren’t necessarily market-ready. Attempts at production deployments based on these models may then fail, due to accuracy issues. Such failures are attributable to the lack of case-specific training data at scale, among other factors.
Leveraging open source datasets or synthetic data in the early phases of development is certainly cost-effective and, depending on the project, may also serve your production needs. In other cases, however, custom training datasets are required to achieve market-ready accuracy levels.
Training Data Factors That Affect Inference Output Accuracy
To keep diseases from being misdiagnosed, say, or to prevent self-driving cars from mistaking a person for an object, computer vision models need to be trained with massive amounts of high-quality, large scale, relevant, comprehensive and, potentially, custom data. Open-source datasets may fall short with lack of variety, quantity, and real-life examples. For example, if you are looking to identify objects, pre-made training sets may include a perfectly framed picture of the object, while in the real world, this won’t always be the case.
The training set may also include disproportionally high amounts of certain image categories, neglecting others. If you were looking to identify dogs, an open source dataset may have an abundance of images of Labrador Retrievers, but little or no pictures of Jack Russell Terriers. And it may not have adequate representation of “edge cases” that are critical in your particular application (Figure A).
 |
 |
 |
Figure A. Publicly available datasets may contain typical images of various subjects (top left and top right) but omit all-important image “edge cases” (bottom) (courtesy iMerit and Pexels).
Quality and Quantity
Depending on your project, quality may be straightforward to define. Many times, however, the definition of what a quality dataset looks like is a challenge in and of its own. This initial definition is typically based on project needs. But due to the nature of variable data sources, type of labeling task, gaps in requirement perception, and contextual relevance, the definition of quality can evolve. Once you have achieved the definition of quality data for your project to ensure accuracy and consistency, you can then scale labeling efforts to build your training datasets.
While most academic reports and blog writeups about machine learning focus on improvements to algorithms and features, the use of larger training datasets may in fact be more impactful on results. See, for example, the research paper “The Unreasonable Effectiveness of Data” (PDF) and a follow-up blog post published by Google Research. The more images or video you use to train your algorithm, the more robust and accurate it likely will be (Figure B). But if open-source datasets don’t provide the amount of data you require in order to achieve ideal solution quality, the collection and labeling of a custom dataset may be needed.
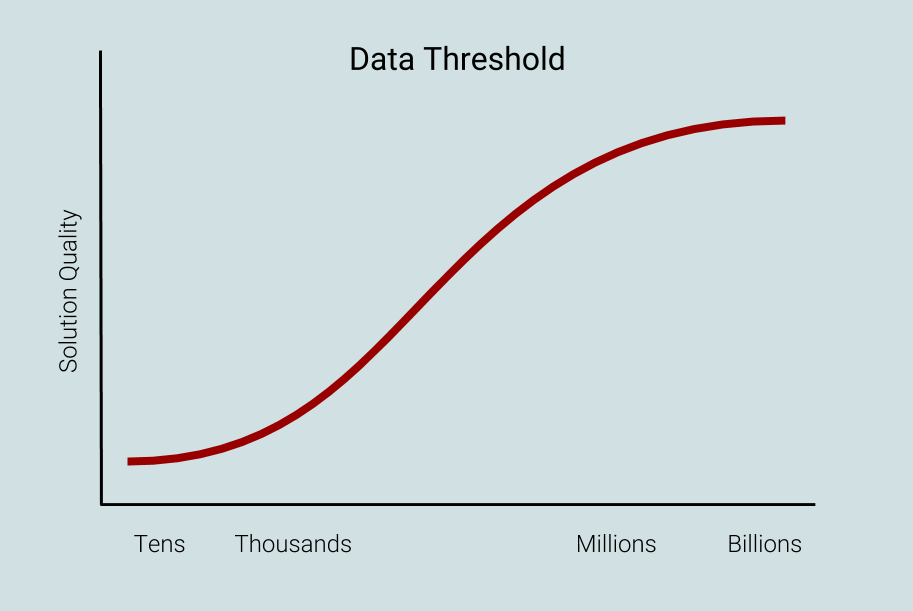
Figure B. The more images or video you use to train your algorithm, the more robust and accurate it likely will be (courtesy iMerit).
Relevance and Comprehensiveness
While both data quality and quantity are crucial to output accuracy, so too is the relevance of the dataset. To produce a high-quality training dataset, you’ll likely require raw image data that directly applies to the problem that you are trying to solve. If you’re trying to train a computer to identify cats via an open-source dataset of animal images, for example, only having photos of dogs and rabbits on hand will not produce the accuracy results you need (Figure C).


Figure C. Relevance (top) and comprehensiveness (bottom) are both important training dataset characteristics (courtesy iMerit).
An accurate algorithm also requires training with a diverse and extensive dataset. If your objective is to identify cats, for example, the algorithm probably needs to be able to identify all 50+ different breeds of cats. It also needs to be able to identify household cats versus wild cats, identify sitting cats versus standing cats, etc. To accomplish this objective, a training dataset must include a spectrum of cat images. Depending on the complexity of the project and the desired outcome, this might mean 5,000 labeled images, or it might mean 5 million labeled images.
How KinaTrax Leverages Custom Datasets to Optimize Pitcher Performance
As you can see, there are many factors involved in achieving market-ready output quality levels. Ensuring that you have a large amount of high quality, relevant and comprehensive data is the first step. Next is ensuring accurate image labeling and annotation. A case study from KinaTrax, one of our partners, will exemplify this concept.
KinaTrax develops 3D kinematic models that are used by MLB (Major League Baseball) teams to monitor and improve pitchers’ performance, as well as prevent injuries. Because of the need for constant coverage from multiple angles, the company is unable to leverage the vast amount of already available video of MLB pitchers captured by broadcast networks, etc. Instead, KinaTrax’s Markerless Motion Capture System comprises a suite of imagers mounted throughout a baseball stadium to capture pitchers’ detailed movements. Currently, these systems are installed at the home stadiums of the Chicago Cubs and the Tampa Bay Rays, along with another undisclosed team’s home stadium.
KinaTrax uses computer vision and machine learning algorithms to capture a pitcher’s biomechanics at more than 300 frames per second. The video is then recovered in 3D and reconstructed frame by frame, producing an image for every motion within the pitch sequence. These images are then annotated at 20 distinct joint centers by iMerit’s team of computer vision data experts (Figure D). iMerit provides on-demand and scalable end-to-end annotation resources through KinaTrax’s data analysis workflow. The 3D kinematic models can then find use in generating comprehensive and customizable biomechanic reports for evaluating mechanics over time, and for both performance enhancement and injury prevention outcomes.

Figure D. KinaTrax’s Markerless Motion Capture System converts video frames to a series of 3D images, which are then annotated at 20 distinct joint centers by iMerit’s team of data experts (courtesy iMerit).
The idea of leveraging in-game data to enhance pitcher performance “will make a profound difference in major league baseball; it will change the game,” according to Steven Cadavid, KinaTrax’s president. “Billy Beane revolutionized baseball with his analytical, evidence-based approach to selecting players dubbed ‘Moneyball’. KinaTrax’s offering is similarly revolutionary, supplying team management with the data they need to make the best decisions about a pitcher’s health. From an injury prevention standpoint, for example, the datasets we’re collecting are really unprecedented.”
KinaTrax is taking a fresh approach to motion capture technology by leveraging video annotation to obtain the data required to build 3D kinematic models. This means that the subjects, in this case the MLB pitchers, don’t need to wear markers to capture the data. This key enhancement in KinaTrax’s technology enables the company to capture not only training data but also in-game information. And in combination with iMerit’s on-demand dataset service offering, technology-improved human beings are revolutionizing the game of baseball.
Jai Natarajan
Vice President, Marketing and Technology, iMerit