Neural networks enable the identification of objects in still and video images with impressive speed and accuracy after an initial training phase. This so-called "deep learning" has been enabled by the combination of the evolution of traditional neural network techniques, with one latest-incarnation example known as a CNN (convolutional neural network), by the steadily increasing processing "muscle" of CPUs aided by algorithm acceleration via various co-processors, by the steadily decreasing cost of system memory and storage, and by the wide availability of large and detailed data sets. In this article, we provide an overview of CNNs and then dive into optimization techniques for object recognition and other computer vision applications accelerated by DSPs and vision and CNN processors, along with introducing an industry alliance intended to help product creators incorporate vision capabilities into their designs.
Classical computer vision algorithms typically attempt to identify objects by first detecting small features, then finding collections of these small features to identify larger features, and then reasoning about these larger features to deduce the presence and location of an object of interest, such as a face. These approaches can work well when the objects of interest are fairly uniform and the imaging conditions are favorable, but they often struggle when conditions are more challenging. An alternative approach, deep learning, has been showing impressive results on these more challenging problems where there's a need to extract insights based on ambiguous data, and is therefore rapidly gaining prominence.
The algorithms embodied in deep learning approaches such as CNNs are fairly simple, comprised of operations like convolution and decimation. CNNs gain their powers of discrimination through a combination of exhaustive training on sample images and massive scale – often amounting to millions of compute nodes (or "neurons"), requiring billions of compute operations per image. This high processing load creates challenges when using CNNs for real-time or high-throughput applications, especially in performance-, power consumption- and cost-constrained embedded systems.
Due to the massive computation and memory bandwidth requirements of sophisticated CNNs, implementations often use highly parallel processors. General-purpose GPUs (graphics processing units) are popular, as are FPGAs (field programmable gate arrays), especially for initial network training. But since the structure of CNN algorithms is very regular and the types of computation operations used, such as repetitions of MACs (multiply-accumulates), are very uniform, they're well matched to a DSP or another processor more specifically tailored for CNNs, particularly for subsequent object recognition tasks.
Neural Network Overview
A neural network is a system of interconnected artificial neurons that respond to inputs and generate output signals that flow to other neurons, typically constructed in multiple layers, representing recognition or triggering on more and more complex patterns. The connections among neurons have weights that are tuned during the initial network training process, so that a properly trained network will respond correctly when presented with an image or pattern to recognize. Each layer of the network comprises many neurons, each either responding to different inputs or responding in different ways to the same inputs. The layers build up so that the first layer detects a set of primitive patterns in the input, the second layer detects patterns of these primitive patterns, the third layer detects patterns of these patterns, and so on (Figure 1).
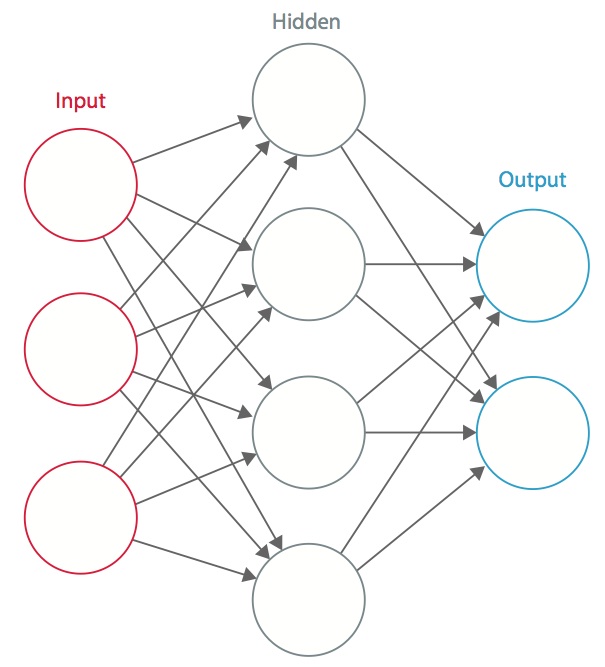
Figure 1. An artificial neural network is comprised of multiple layers, each containing multiple neurons.
CNNs are a particularly important category of neural networks; the same weights are used uniformly on different sections of the inputs, and the response function is based on a sum-of-products of inputs and weights in the form of a dot-product or convolution operation. Typical CNNs use multiple distinct layers of pattern recognition; sometimes as few as two or three, other times more than a hundred. CNNs follow a common pattern in the relationships between layers. Initial layers typically have the largest size inputs, as they often represent full-size images (for example), although the number of unique input channels is small (red, green and blue for RGB images, for example). These initial layers often encompass a narrow set of weights, as the same small convolution kernel is applied at every input location.
Initial layers also often create smaller outputs in X-Y dimensions, by effectively sub-sampling the convolution results, but create a larger number of output channels. As a result, the neuron data gets "shorter" but "fatter" as it traverses the network (Figure 3). As the computation progresses through the network layers, the total amount of neurons may also decrease, but the number of unique weights often grows. The final network layers are often fully connected, wherein each weight is used exactly once. In such layers the size of the intermediate data is much smaller than the size of the weights. The relative sizes of data and weights, along with the ratio of computation to data usage, ultimately become critical factors in selecting and optimizing the architecture's implementation.
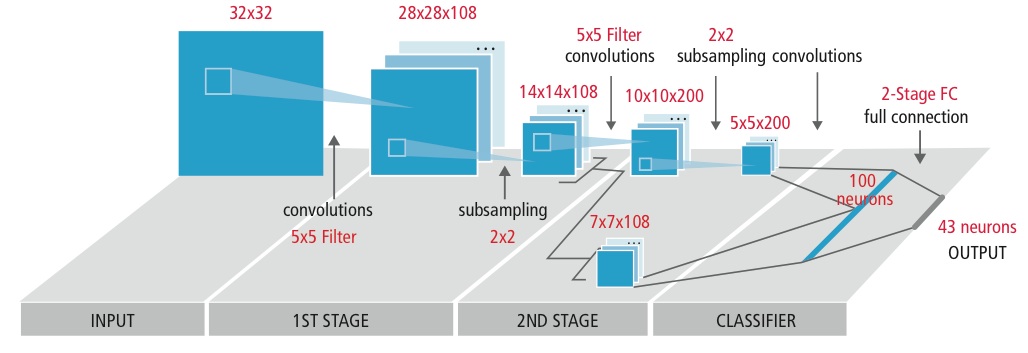
Figure 2. As computation progresses through the network layers, the total amount of neurons may decrease, but the number of unique weights often grows; the final network layers are often fully connected (top). An AlexNet-specific implementation (middle) provides another perspective on the network layers' data-versus-coefficient transformations (bottom).
Network Training
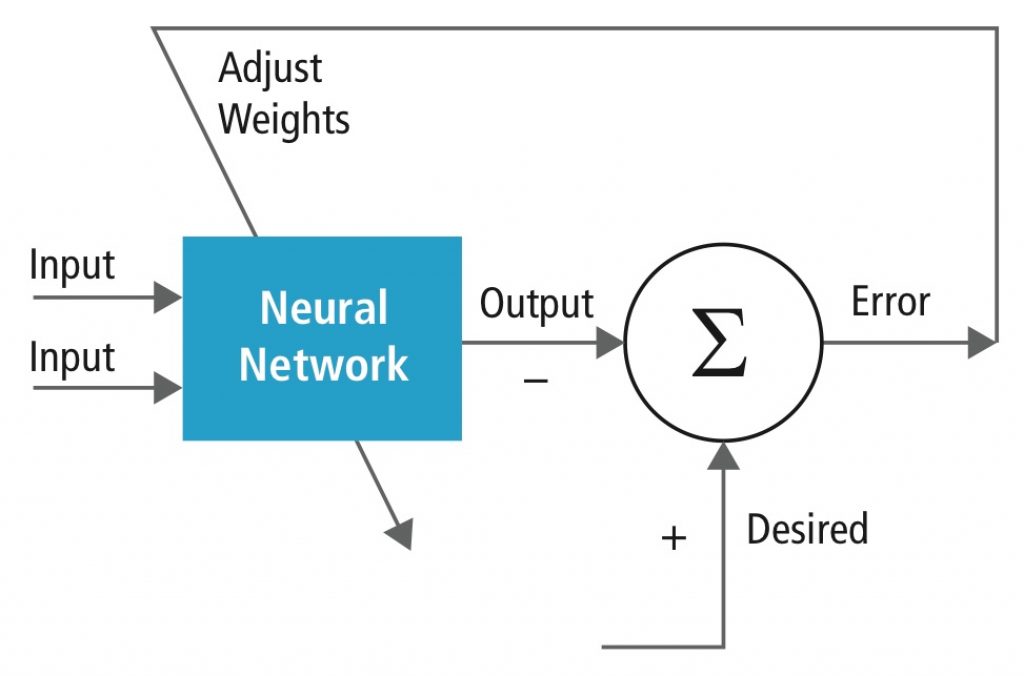
Training is performed using a labeled dataset of inputs in a wide assortment of representative input patterns that are tagged with their intended output response. It uses general-purpose methods to iteratively determine the weights for intermediate and final-feature neurons (Figure 3). The training process typically begins with random initialization of the weights; labeled inputs are then sequentially applied, including notation of the computed value for each input. This phase of the training process is known as forward inferencing, or forward propagation. Each output is compared to the expected value, based on the previously set label for the corresponding input. The difference, i.e. the error, is fed back through the network; a portion of the total error is allocated to each layer and to each weight used in that particular output computation. This phase of the training process is called back propagation. The allocated error at each neuron is used to update the weights, with the goal of minimizing the expected error for that input.
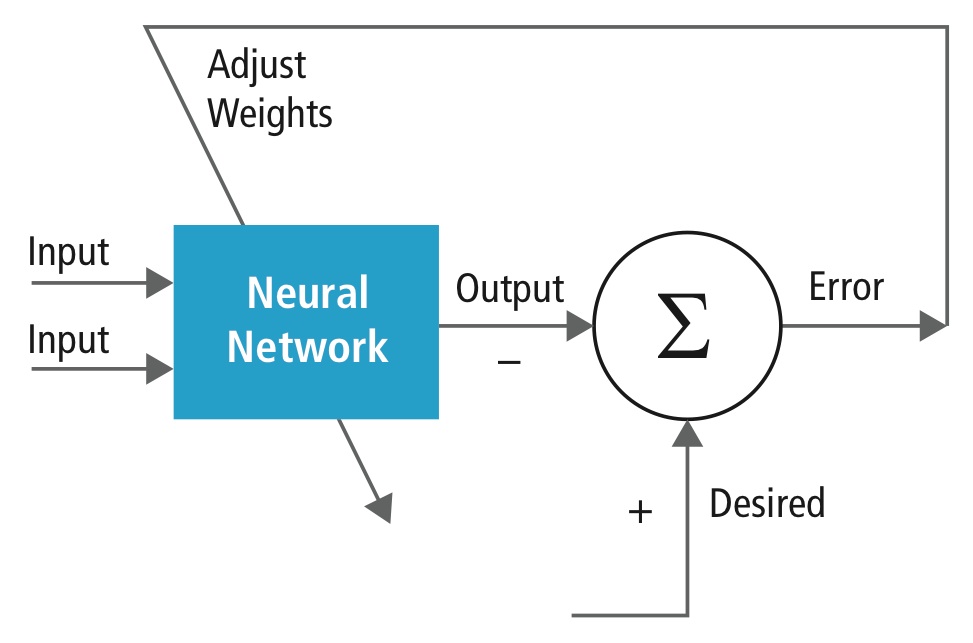
Figure 3. Neural network training iteratively determines the weights for intermediate and final-feature neurons
After the application of a large number of independent inputs, along with a large number of iterations covering all of the inputs, the weights at each layer will eventually converge, resulting in an effective recognition system. The pattern recognizer's characteristics are determined by two factors: the structure of the network (i.e. which neurons feed into which other neurons on successive layers), and the weights. In most neural network applications, the network's architects manually design its structure, while automated training determines its set of weights.
A number of software environments have emerged for conducting this automated training. Each framework typically allows for a description of the network structure, along with setting parameters that tune the iterative coefficient computations, and also enables labeled training data to be used in controlling the training. The training data set is often quite large – tens of thousands to millions of images or other patterns – and effective training often also requires a large number of iterations using the training data. Training can be extremely computationally demanding; large training exercises may require weeks of computation across thousands of processors.
Some of the popular training environments include:
- Caffe, from the University of California at Berkeley
Caffe is perhaps the most popular open-source CNN framework among deep learning developers today. It is generally viewed as being easy to use, though it's perhaps not as extensible as some alternatives in its support of new layers and advanced network structures. Its widespread popularity has been driven in party by NVIDIA’s selection of Caffe as the foundation for its deep learning tool, DIGITS. Caffe also tends to undergo frequent new-version releases, along with exhibiting a relatively high rate of both format and API changes. - Theano, from the University of Montréal in Canada
Theano is a Python-based library with good support for GPU-acceleration training. It is highly extensible, as a result being particularly attractive to advanced researchers exploring new algorithms and structures, but is generally viewed as being more complex to initially adopt than is Caffe. - MatConvNet from Oxford University
MatConvNet is a MATLAB toolbox for CNN. It is simple and efficient, and features good support for GPU training acceleration. It is also popular among deep learning researchers because it is flexible, and adding new architectures is straightforward. - TensorFlow from Google
TensorFlow is a relatively new training environment. It extends the notion of convolutions to a wider class of N-dimensional matrix multiplies, which Google refers to as "tensors", and promises applicability to wider class of structures and algorithms. It is likely to be fairly successful if for no other reason than because of Google’s promotion of it, but its acceleration capabilities (particularly on GPUs) are not yet as mature as with some of the other frameworks. - Torch from the Dalle Molle Institute for Perpetual Artificial Intelligence
Torch is one of the most venerable machine learning toolkits, dating back to 2002. Like TensorFlow, it uses tensors as a basic building block for a wide range of computation and data manipulation primitives. - The Distributed Machine Learning Toolkit (DMLT) from Microsoft
DMLT is a general-purpose machine learning framework, less focused on deep neural networks in particular. It includes a general framework for server-based parallelization, data structures for storage, model scheduling and automated pipelining for training.
Most of these training environments, which run on standard infrastructure CPUs, also include optimizations supporting various coprocessors.
Object Recognition
Once the network is trained, its structure and weights can subsequently be utilized for recognition tasks, which involve only forward inferences on unlabeled images and other data structures. In this particular case, the purpose of the inference is not to compute errors (as with the preceding training) but to identify the most likely label or labels for the input data. Training is intended to be useful across a wide assortment of inputs; one network training session might be used for subsequent recognition or inferences on millions or billions of distinct data inputs.
Depending on the nature of the recognition task, forward inference may end up being run on the same system that was used for the training. This scenario may occur, for example, with infrastructure-based "big data analytics" applications. In many other cases, however, the recognition function is part of a distributed or embedded system, where the inference runs on a mobile phone, an IoT node, a security camera or a car. In such cases, trained model downloads into each embedded device occur only when the model changes – typically when new classes of recognition dictate retraining and update.
These latter scenarios translate into a significant workload asymmetry between initial training and subsequent inference. Training is important to the recognition rate of the system, but it's done only infrequently. Training computational efficiency is therefore fundamentally dictated by what level of computational resources can fit into an infrastructure environment, and tolerable training times may extend to many weeks' durations. In contrast, inference many be running on hundreds or thousands of images per second, as well as across millions or potentially billions of devices; the aggregate inference computation rate for a single pre-trained model could reach 1014-1018 convolution operations per second. Needless to say, with this kind of workload impact, neural network inference efficiency becomes crucial.
Neural network inferences typically make both arithmetic and memory capacity demands on the underlying computing architecture (Figure 4). Inferences in CNNs are largely dominated by MAC (multiply-accumulate) operations that implement the networks' essential 3-D convolution operations. In fact, MACs can in some cases represent more than 95% of the total arithmetic operations included in the CNN task. Much of this computation is associated with the initial network layers; conversely, much of the weight memory usage – sometimes as much as 95% – is associated with the later layers. The popular AlexNet CNN model, for example, requires approximately 80 million multiplies per input image, along with approximately 60 million weights. By default, training produces 32-bit floating-point weights, so the aggregate model size is roughly 240 MBytes, which may need to be loaded and used in its entirety once per input image.
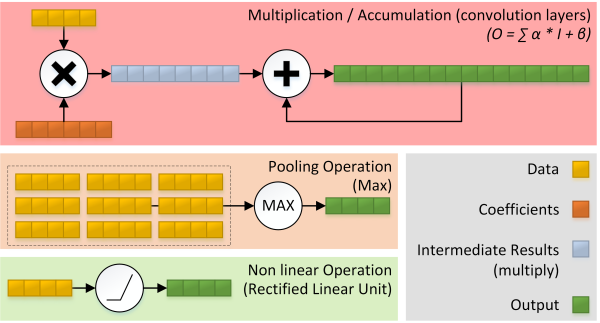
Figure 4. Neural network inferences involve extensive use of both arithmetic calculations and memory accesses.
These arithmetic and memory demands drive the architecture of CNN inference hardware, especially in embedded systems where compute rates and memory bandwidth have a directly quantifiable impact on throughput, power dissipation and silicon cost. To a first order, therefore, the following hardware capabilities are likely to dominate CNN inference hardware choices:
- MAC throughput and efficiency, the latter measured in metrics such as MACs per second, MACs per watt, MACs per mm2 and MACs per dollar.
- Memory capacity, especially for on-chip memory storage, to hold weights, input data, and intermediate neuron results data.
- Memory bus bandwidth to transfer data, especially coefficients, on-chip.
Embedded Optimizations
With embedded systems using large CNN models, it may be difficult to hold the full set of weights on-chip, especially if they're in floating point form. Off-chip weight fetch bandwidth may be as high as the frame rate multiplied by the model size, a product that can quickly reach tens of GBytes per second. Providing (and powering) that off-chip memory bandwidth can dominate the design and complete overshadow the energy even for the large number of multiplies. Managing the model size becomes a key concern in embedded implementations.
Fortunately, a number of available techniques, some just emerging from the research community, can dramatically reduce the model load bandwidth problem. They include:
- Quantizing the weights to a smaller number of bits, by migrating to 16-bit floating point, 16-bit fixed point, 8-bit fixed point or even lower-precision data sizes. Some researchers have even reported acceptable-accuracy success with single-bit weights. Often, the trained floating-point weights can simply be direct-converted to a suitably scaled fixed-point representation without significant loss of recognition accuracy. Building this quantization step into the training process can deliver even higher accuracy. In addition, some research results recommend encoding the data, with the subsequently compressed weights re-expanded to their full representation upon use in the convolution.
- In some networks, both weights and intermediate result data may contain a large number of zero values, i.e. they are sparse. In this case, a range of simple and effective lossless compression methods are available to represent the data or weights within a smaller memory footprint, additionally translating to a reduction in required memory bus bandwidth. Some networks, especially if training has been biased to maximize sparseness, can comprise 60-90% zero coefficients, with corresponding potential benefits on required capacity, bandwidth and sometimes even compute demands.
- Large model sizes, along with the prevalence of sparseness, together suggest that typical neural network models may contain a large amount of redundancy. One of the most important emerging optimization sets for neural networks therefore involves the systematic analysis and reduction in the number of layers, the number of feature maps or intermediate channels, and the number of connections between layers, all without negatively impacting the overall recognition rate. These optimizations have the potential reduce the necessary MAC rate, the weight storage and the memory bandwidth dramatically, above and beyond the benefits realized by quantization alone.
Together, these methods can significantly reduce the storage requirements when moving CNNs into embedded systems. These same techniques can also deliver significant benefits in reducing the total computation load, specifically in replacing expensive 32-bit floating-point operations with much cheaper and lower energy 16-bit, 8-bit or smaller integer arithmetic operations.
Coprocessor Characteristics
Optimizing the processing hardware employed with CNNs also provides a significant opportunity to maximize computational efficiency, by taking full advantage of the high percentage of convolution operations present. Convolution can be considered to be a variant of the matrix multiplication operation; hardware optimized for matrix multiplies therefore generally does well on convolutions. Matrix multiplies extensively reuse the matrices' rows and columns, potentially reducing the memory bandwidth and even register bandwidth needed to support a given MAC rate. Lower bandwidth translates into reduced latency, cost and power consumption.
Google’s TensorFlow environment, in fact, leverages 3D matrix multiplies (i.e. tensor operations) as its foundation computational building block. For most convolutions, further optimizations of the hardware are possible, for example in doing direct execution of wide convolutions that take explicit advantage of the extensive data or weight reuse in 1-D, 2-D and 3-D convolutions, beyond what’s possible with just matrix multiplies.
Hardware for CNNs is evolving rapidly. Much of the recent explosion in CNN usage has leveraged off-the-shelf chips such as GPUs and FPGAs. These are reasonable pragmatic choices, especially for initial network training purposes, since both types of platform feature good computational parallelism, high memory bandwidth, and some degree of flexibility in data representation. However, neither product category was explicitly built for CNNs, and neither category is particularly efficient for CNNs from cost and/or energy consumption standpoints.
DSP cores are becoming increasingly used for SoC (system-on-chip) CNN processing implementations, particularly with imaging- and vision-oriented architectures. They typically feature very high MAC rates for lower-precision (especially 16-bit and 8-bit) data, robust memory hierarchies and data movement capabilities to hide the latency of off-chip data and weight fetches, and very high local memory bandwidth to stream data and coefficients through the arithmetic units. Note that the memory access patterns for neural networks tend to be quite regular, thereby enabling improved efficiency by using DMA (direct memory access) controllers or other accelerators, versus generic caches.
The latest DSP variants now even include specific deep learning-tailored features such as convolution-optimized MAC arrays, to further boost the throughput and capabilities for on-the-fly compression and decompression of data, in order to reduce the required memory footprint and bandwidth. DSPs, like GPUs, allow for full programmability; everything about the structure, resolution, and model of the network is represented in program code and data. As a result, standard hardware can run any network without any hardware changes or even hardware-level reprogramming.
Finally, the research community is beginning to produce a wide range of even more specialized engines, completely dedicated to CNN execution, with minimal energy consumption, and capable of cost-effectively scaling to performance levels measured in multiple teraMACs per second. These new optimized engines support varying levels of programmability and adaptability to non-standard network structures and/or mixes of neural network and non-neural network recognition tasks. Given the high rate of evolution in neural network technology, significant levels of programmability are likely to be needed for many embedded tasks, for a significant time to come.
Efficient hardware, of course, is not by itself sufficient. Effective standardized training environments aid developers in creating models, but these same models often need to migrate into embedded systems quite unlike the platforms on which they were initially developed. One or more of the following software capabilities therefore often complement the emerging CNN implementation architectures, to ease this migration:
- Software development tools that support rapid design, coding, debug and characterization of neural networks on embedded platforms, often by leveraging a combination of virtual prototype models and example hardware targets
- Libraries and examples of baseline neural networks and common layer types, for easy construction of standard and novel CNN inference implementations, and
- CNN "mappers" that input the network structures as entered, along with the weights as generated by the training framework, outputting tailored neural networks for the target embedded implementation, often working in combination with the previously mentioned development tools and libraries.
SoC and System Integration
Regardless of whether the neural network-based vision processing subsystem takes the form of a standalone chip (or set of chips) or is integrated in the form of one or multiple cores within a broader-function SoC, it's not fundamentally different than any other kind of vision processing function block (Figure 5). The system implementation requires one or more capable input sensors, high-bandwidth access to the on- and/or off-chip frame buffer memory, the vision processing element itself, the hardware interface between it and the rest of the chip and/or system, and a software framework to tie the various hardware pieces together. Consideration also should be given to how overall system processing is portioned across the various cores, chips and other resources, since this partition will impact how the hardware and software is structured.
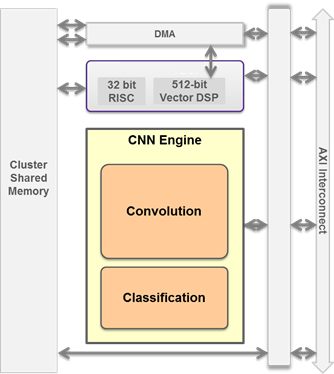
Figure 5. Neural network processing can involve either/both standalone ICs or, as shown here, a core within a broader-function SoC.
The hardware suite comprises four main function elements: sensor input, sensor processing, data processing (along with potential multi-sensor data fusion), and system output. Sensor input can take one or multiple of many possible forms (one or several cameras, visible- or invisible-light spectrum-based, radar, laser, etc.) and will depend on system operating requirements. In most cases, some post-capture processing of the sensor data will be required, such as Bayer-to-RGB interpolation for a visible light image sensor. This post-processing may be supported within the sensor assembly itself, or may need to be done elsewhere as an image pre-processing process prior to primary processing by the deep learning algorithms. This potential need is important to ascertain, because if the processing is done on the deep learning processor, sufficient incremental performance will need to be available to support it.
In either case, the data output from the sensor will be stored in frame buffer memory, either in part or in its entirety, in preparation for processing. As previously discussed, the I/O data bandwidth of this memory is often at least as important, if not more so, than its density, due to the high volume of data coming from the sensor in combination with an often-demanding frame rate. A few years ago, expensive video RAM would have been necessary, but today's standard DDR2/DDR3 SDRAM can often support the required bandwidth while yielding significant savings in overall system cost.
The data next has to be moved from the frame buffer memory to the deep learning processing element. In most cases, this transfer will take place in the background using DMA. Once the data is the deep learning processing element, any required pre-processing will take place, followed by image analysis, which will occur on a frame-by-frame basis in real-time. This characteristic is important to keep in mind while designing the system because a 1080p60 feed, for example, will require larger memory and much higher processing speeds than a 720p30 image. Once analysis is complete, the generated information will pass to the system output stage for post-processing and to generate the appropriate response (brake, steer, recognize a particular person, etc). As with the earlier sensor output, analysis post-processing can take place either in the deep learning processing element or another subsystem. Either way, the final output information will in most cases not require high bandwidth or large storage spaces; it can instead transfer over standard intra- or inter-chip busses and via modest-size and –performance buffer memory.
Software Partitioning
Designing the software to effectively leverage the available resources in a deep learning vision system can be challenging, because of the diversity of coprocessors that are often available. Dynamically selecting the best processor for any particular task is essential to efficient resource utilization across the system. Fortunately, a number of open source standards can find use in programming and managing deep learning and other vision systems. For example, the Khronos Group's OpenVX framework enables the developer to create a connected graph of vision nodes, used to manage the vision pipeline. OpenVX supports a broad range of platforms, is portable across processors, and doesn’t require a high-performance CPU. OpenVX nodes can be implemented in C/C++, OpenCL, intrinsics, dedicated hardware, etc, and then connected into a graph for execution. OpenVX offers a high level of abstraction that makes system optimization easier by allowing the algorithms to take advantage of all available and appropriate resources in the most efficient manner.
The individual nodes are usually programmed using libraries such as OpenCV (the Open Source Computer Vision Library), which enable designers to deploy vision algorithms without requiring specialized in-advance knowledge of image processing theory. Elements in the vision system that include wide parallel structures, however, may be more easily programmed with Khronos' OpenCL, a set of programming languages and APIs for heterogeneous parallel programming that can be used for any application that is parallelizable. Originally targeted specifically to systems containing CPUs and GPUs, OpenCL is now not architecture-specific and can therefore find use on a variety of parallel processing architectures such as FPGAs, DSPs and dedicated vision processors. OpenCV and OpenVX can both use OpenCL to accelerate vision functions.
Many systems that employ a vision subsystem will also include a host processor. While some level of interaction between the vision subsystem and the host processor will be inevitable, the degree of interaction will depend on the specific design and target application. In some cases, the host will closely control the vision subsystem, while in others the vision subsystem will operate near-autonomously. This design consideration will be determined by factors such as the available resources on the host, the capability of the vision subsystem, and the vision processing to be done. System partitioning can have a significant effect on performance and power optimization, and therefore begs for seriously scrutiny when developing the design.
Conclusion
The popularity and feasibility of real-world neural network deployments are growing rapidly. This accelerated transformation of the computer vision field affects a tremendous range of platform types and end applications, driving profound changes with respect to their cognitive capabilities, the development process, and the underlying silicon architectures for both infrastructure and embedded systems. Optimizing an embedded-intended neural network for the memory and processing resources (and their characteristics) found in such systems can deliver tangible benefits in cost, performance, and power consumption parameters.
Sidebar: Additional Developer Assistance
The Embedded Vision Alliance, a worldwide organization of technology developers and providers, is working to empower product creators to transform the potential of vision processing into reality. BDTI, Cadence, Movidius, NXP and Synopsys, the co-authors of this article, are members of the Embedded Vision Alliance. First and foremost, the Embedded Vision Alliance's mission is to provide product creators with practical education, information and insights to help them incorporate vision capabilities into new and existing products. To execute this mission, the Embedded Vision Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Embedded Vision Alliance’s twice-monthly email newsletter, Embedded Vision Insights, among other benefits.
The Embedded Vision Alliance also offers a free online training facility for vision-based product creators: the Embedded Vision Academy. This area of the Embedded Vision Alliance website provides in-depth technical training and other resources to help product creators integrate visual intelligence into next-generation software and systems. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCL, OpenVX and OpenCV, along with Caffe, TensorFlow and other deep learning frameworks. Access is free to all through a simple registration process.
The Embedded Vision Alliance also holds Embedded Vision Summit conferences. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Embedded Vision Alliance member companies. These events are intended to inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations, to offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and to provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2016, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Embedded Vision Alliance website and YouTube channel. The next Embedded Vision Summit, along with accompanying workshops, is currently scheduled take place on May 1-3, 2017 in Santa Clara, California. Please reserve a spot on your calendar and plan to attend.
By Brian Dipert
Editor-in-Chief, Embedded Vision Alliance
Jeff Bier
Founder, Embedded Vision Alliance
Co-founder and President, BDTI
Chris Rowen
Chief Technology Officer, Cadence
Jack Dashwood
Marketing Communications Director, Movidius
Daniel Laroche
Systems Architect, NXP Semiconductors
Ali Osman Ors
Senior R&D Manager, NXP Semiconductors
Mike Thompson
Senior Product Marketing Manager, Synopsys