
This article was originally published as a two-part blog series at Cadence's website. It is reprinted here with the permission of Cadence.
"Even if he gives the same presentation two weeks apart, it will be different.”
—Neil Robinson, fellow attendee, on Chris Rowen
My question: Is it because he is such a dynamic speaker, and inserts all sorts of info on the fly, or is it because the industry is changing week to week? The answer: Both.
I attended a recent Distinguished Speaker event at Cadence, featuring Chris Rowen, CEO of Cognite Ventures, and formerly of Cadence. He was speaking about “Vision, Innovation, and the Deep Learning Explosion”. As ever, Chris is truly a great speaker and evangelist when it comes to machinelearningdeeplearning and the business and application implications it will have on the current and future technology markets. I have heard him speak multiple times before, and have always enjoyed his presentations.
This presentation was no different. While others may have walked away with other details, the two main themes for me were:
- Where should the “magic” happen in so-called intelligent systems? Should it be in the cloud, in the device/application, or a combination of both? The answer: c.
- We must be very careful about where and how these algorithms are deployed. These systems are very fragile, and it’s incredibly easy to either inadvertently or intentionally (even maliciously) introduce a manipulation bias in the training.
 Where Does the Magic Happen?
Where Does the Magic Happen?
In the story of Aladdin’s lamp, is the magic in the lamp, or in the genie inside it?
In his presentation, Chris showed a cost/benefits comparison of in-device processing through various iterations of cloud computing, to the full cloud solution. The ultimate realities can be broken into four parameters to consider:
- System responsiveness
- Scope of data analysis
- Privacy
- Computing and network cost
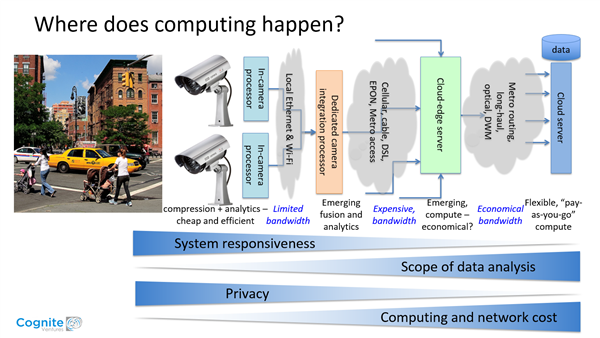
His conclusions:
- If you must analyze vast amounts of data at an affordable cost, the magic is in the genie (the cloud).
- If you want a system to be immediately responsive and to be the most secure and safeguard against misuse, then the magic must happen in the lamp (embedded).
- The “happy medium” is probably using a “cloud-edge server” (a method of optimizing cloud computing systems by performing data processing at the edge of the network, near the source of the data).
An example of a system in which you really want to use an embedded system is Auto2, especially in advanced driver-assistance systems (ADAS), especially especially in object detection and safety subsystems. As Chris said, the last thing you want to see when facing a busy intersection with pedestrians, cars, bicycles, traffic signals and signs, and a snowstorm going on is the word “buffering” on your Auto2 interface.
Images are being processed faster than 24 frames per second (fps), which is the standard for movies, 60fps for video games. The human eye can see about 1000fps, so we have to assume that object detection has to probably go that fast. Imagine a 360° view around your car, with that many fps… how many pixels is that? Is it enough to detect that bicyclist? Best add a few more.
So the best way to approach the processing required for an automotive system is to have the magic happen at the local level—in the lamp—with the critical, time-sensitive systems being processed in literal real time. To do this, lightning-fast DSPs that use extremely low power embedded in the system are required.
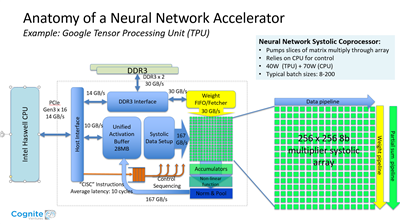
How do we avoid carrying a datacenter in the trunk of our Tesla? Well, this is the reason for the big push for effective DSPs in these applications. You must have an economic use of MACs*/watt. Google’s TPU** uses a very different architecture, but gets good results, though it uses a lot of power.
The Tensilica C5 Vision DSP allows about 1TMAC/watt, so that’s a good start.
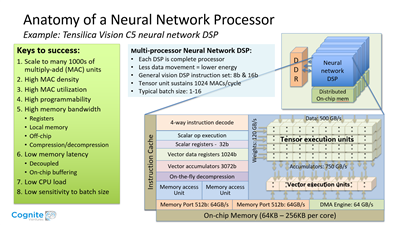
As Chris said, we’re in the beginning of a silicon design renaissance. Standard processors are improving with new IP building blocks, from an era of chip startups with successes that are few and far between.
* MACs are "multiply-accumulates", a way of measuring computations.
** TPU is the Tensor Processing Unit, Google's equivalent of Cadence's Tensilica Vision C5 DSP.
 "We must treat the disease of racism. This means we must understand the disease."
"We must treat the disease of racism. This means we must understand the disease."
—Sargent Shriver
[Stay with me, this quote becomes relevant…]

How Can a Robot be Racist?
Racism is a charged word, I know, but hear me out. Chris pointed out that when it comes to security issues and surveillance, there are four weak points of security:
- The usual network and device attacks
- Physical access
- Database manipulation to inject bias
- Classification spoofing
The latter two are the most concerning. Machinelearningdeeplearning systems are notoriously fragile. Whether intentionally or inadvertently, it is very easy to inject a bias into the training of the system, whether you’re looking for cats or intruders (and this is how those Google Deep Dream images that we have all seen in the last few years feature reptile cats peeking through clouds).
You must be incredibly careful not to inject any kind of bias into the source images, or you end up with a system that may, for example, target people of a particular ethnic background as “possible intruders”. It’s not that far from building a completely objective identifier to building a “racist” one.
So here’s the thing. Perhaps you heard about Tay, Microsoft’s experimental Twitter chat-bot, and how within a day it became so offensive that Microsoft had to shut it down and never speak of it again? As the linked article says, making a non-racist classifier is only a little bit harder than making a racist classifier. Rob Speer, Chief Science Officer at Luminoso and author of this article, goes into a lot of the coding specifics of how Tay got to be so horribly offensive.
You don’t need to understand the Python and Tensorflow to understand the article, though; what it boils down to is this [the TL;DR version]: when making a “sentiment processor” in a natural language processor (NLP) using machinelearningdeeplearning, you can create a system that classifies statements as positive or negative. And when you break down anything into +/-, 1/0, or black and white—especially something as complicated as race, gender, ethnicity, or even language in general—you’re gonna come up with a system of institutional bias. It’s impossible to do this without building your own prejudices into it. (And that says something about the inevitability of the systemic racism that persists across generations.)
Before you can fix racism, you must understand how it got there in the first place. Once you understand why, only then you can then address the problem of fixing it. Same with fragile learning systems: we must be very careful about how we train these systems. Where is the bias, and how can we avoid introducing it into the system?
 Institutional racism is difficult enough to address; we must ensure that it doesn’t become part of our technological bias, as well. Chris Rowen talked about the importance of making the right decisions now, as the industry warms up, especially in the areas of the safety, privacy, and security limitations we need to impose on these visual systems, especially those systems connected to the cloud. These are the systems that, if hacked, can go completely awry.
Institutional racism is difficult enough to address; we must ensure that it doesn’t become part of our technological bias, as well. Chris Rowen talked about the importance of making the right decisions now, as the industry warms up, especially in the areas of the safety, privacy, and security limitations we need to impose on these visual systems, especially those systems connected to the cloud. These are the systems that, if hacked, can go completely awry.
By Meera Collier
Senior Writer, Marketing and Business Development, Cadence