
This article was originally published at Tryolabs’ website. It is reprinted here with the permission of Tryolabs.
Why edge computing?
Humans are generating and collecting more data than ever. We have devices in our pockets that facilitate the creation of huge amounts of data, such as photos, gps coordinates, audio, and all kinds of personal information we consciously and unconsciously reveal.
Moreover, not only are we individuals generating data for personal reasons, but we’re also collecting data unbeknownst to us from traffic and mobility control systems, video surveillance units, satellites, smart cars, and an infinite array of smart devices.
This trend is here to stay and will continue to rise exponentially. In terms of data points, the International Data Corporation (IDC) predicts that the collective sum of the world’s data will grow from 33 zettabytes (ZB) in 2019 to 175 ZB by 2025, an annual growth rate of 61%.
While we’ve been processing data, first in data centers and then in the cloud, these solutions are not suitable for highly demanding tasks with large data volumes. Network capacity and speed are pushed to the limit and new solutions are required. This is the beginning of the era of edge computing and edge devices.
In this report, we’ll benchmark five novel edge devices, using different frameworks and models, to see which combinations perform best. In particular, we’ll focus on performance outcomes for machine learning on the edge.
What is edge computing?
Edge computing consists of delegating data processing tasks to devices on the edge of the network, as close as possible to the data sources. This enables real-time data processing at a very high speed, which is a must for complex IoT solutions with machine learning capabilities. On top of that, it mitigates network limitations, reduces energy consumption, increases security, and improves data privacy.
Under this new paradigm, the combination of specialized hardware and software libraries optimized for machine learning on the edge results in cutting-edge applications and products ready for mass deployment.
The biggest challenges to building these amazing applications are posed by audio, video, and image processing tasks. Deep learning techniques have proven to be highly successful in overcoming these difficulties.
Enabling deep learning on the edge
As an example, let’s take self-driving cars. Here, you need to quickly and consistently analyze incoming data, in order to decipher the world around you and take action within a few milliseconds. Addressing that time constraint is why we cannot rely on the cloud to process the stream of data but instead must do it locally.
The downside of doing it locally is that the hardware is not as powerful as a super computer in the cloud, and we cannot compromise on accuracy or speed.
The solution to this is either stronger, more efficient hardware, or less complex deep neural networks. To obtain the best results, a balance of the two is essential.
Therefore, the real question is: Which edge hardware and what type of network should we bring together in order to maximize the accuracy and speed of deep learning algorithms?
In our quest to identify the optimal combination of the two, we compared several state-of-the-art edge devices in combination with different deep neural network models.
Benchmarking novel edge devices
Based on what we think is the most innovative use case, we set out to measure inference throughput in real-time via a one-at-a-time image classification task, so as to get an approximate frames-per-second score.
To accomplish this, we evaluated top-1 inference accuracy across all categories of a specific subset of ImagenetV2 comparing them to some ConvNets models and, when possible, using different frameworks and optimized versions.
Hardware accelerators
While there has been much effort invested over the last few years to improve existing edge hardware, we chose to experiment with these new kids on the blockchain:
- Nvidia Jetson Nano
- Google Coral Dev Board
- Intel Neural Compute Stick
- Raspberry Pi (upper bound reference)
- 2080ti NVIDIA GPU (lower bound reference)
We included the Raspberry Pi and the Nvidia 2080ti so as to be able to compare the tested hardware against well-known systems, one cloud-based and one edge-based.
The lower bound was a no-brainer. Here at Tryolabs, we design and train our own deep learning models. Because of this, we have a lot of computing power at our disposal. So, we used it. To set this lower bound on inference times, we ran the tests on a 2080ti NVIDIA GPU. However, because we were only going to use it as a reference point, we ran the tests using basic models, with no optimizations.
For the upper bound, we went with the defending champion, the most popular single-board computer: the Raspberry Pi 3B.
Neural network models
There are two main networks we wanted to include in this benchmark: the old, well-known, seasoned Resnet-50 and the novel EfficientNets released by Google this year.
For all benchmarks, we used publicly available pre-trained models, which we run with different frameworks. With respect to the Nvidia Jetson, we tried the TensorRT optimization; for the Raspberry, we used Tensor Flow and PyTorch variants; while for Coral devices, we implemented the Edge TPU engine versions of the S, M, and L EfficientNets models; and finally, regarding Intel devices, we used the Resnet-50 compiled with OpenVINO Toolkit.
The dataset
Because all models were trained on an ImageNet dataset, we use ImageNet V2 MatchedFrequency. It consists of 10,000 images in 1,000 categories.
We ran the inference on each image once, saved the inference time, and then found the average. We calculated the top-1 accuracy from all tests, as well as the top-5 accuracy for certain models.
Top-1 accuracy: this is conventional accuracy, meaning that the model’s answer (the one with the highest probability) must equal the exact expected answer.
Top-5 accuracy: means that any one of the model’s top five highest-probability answers must match the expected answer.
Something to keep in mind when comparing the results: for fast device-model combinations, we ran the tests incorporating the entire dataset, whereas we only used parts of datasets for the slower combinations.
Results & analysis
The dashboards below display the metrics obtained from the experiments. Due to the large difference in inference times across models and devices, the parameters are shown in logarithmic scale.
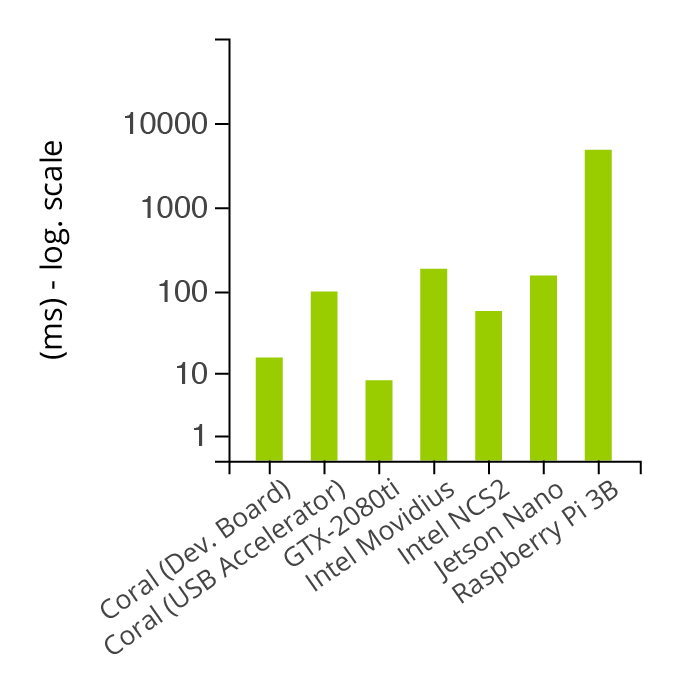
Average inference time by device
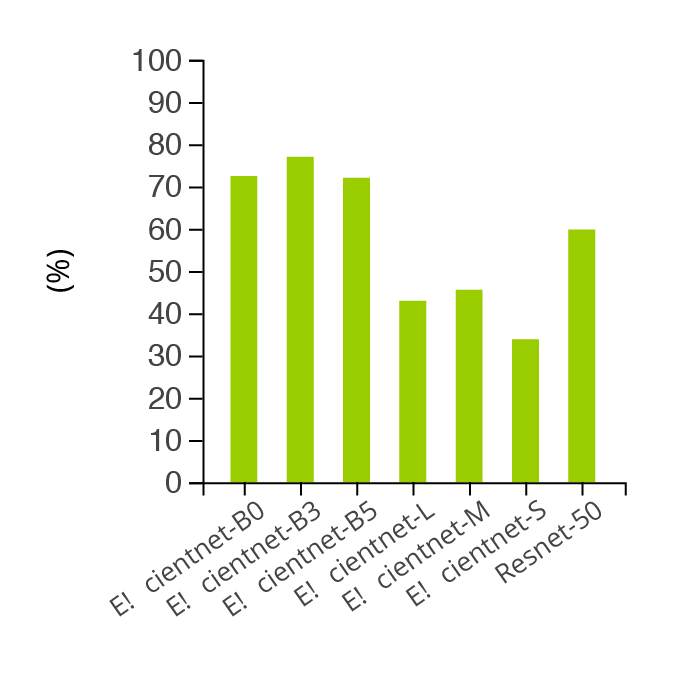
Average accuracy by model
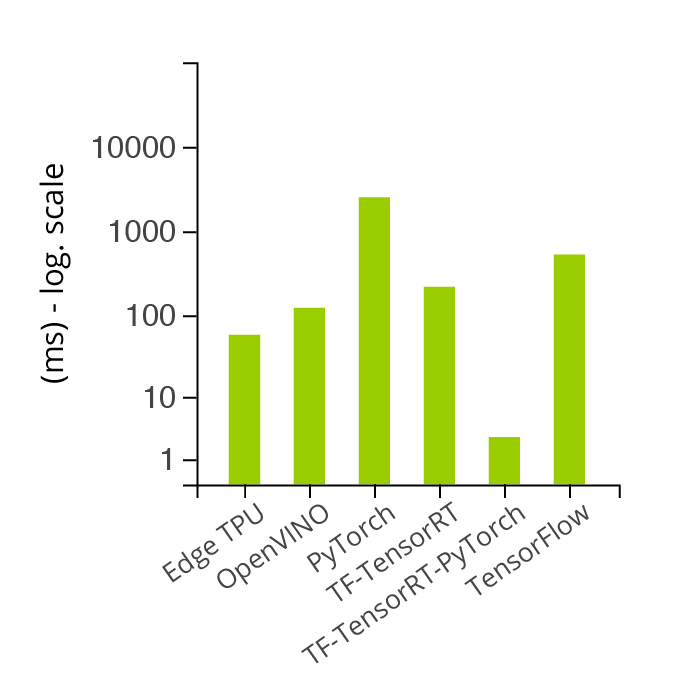
Average inference time by framework
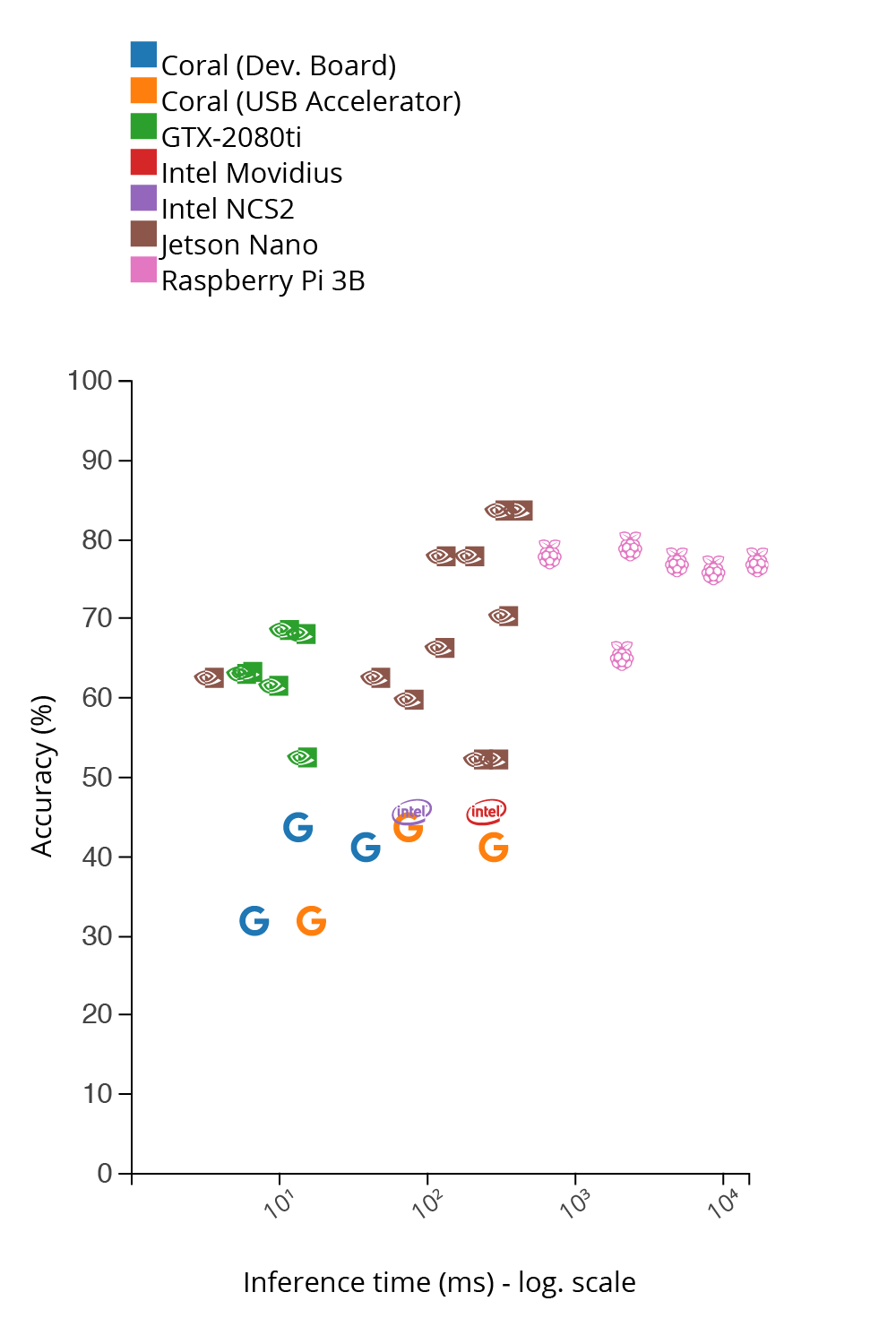
Accuracy vs inference time
| Device | Framework | Model | Inference Time (ms) | Accuracy (top-1) % | Accuracy (top-5) % |
|---|---|---|---|---|---|
| Jetson Nano | TF-TensorRT-PyTorch | Resnet-50 | 2.67 | 64.30 | NaN |
| GTX-2080ti | PyTorch | Resnet-50 | 4.41 | 64.85 | NaN |
| GTX-2080ti | TensorFlow | Efficientnet-B0 | 4.86 | 65.05 | NaN |
| Coral (Dev. Board) | Edge TPU | Efficientnet-S | 5.42 | 33.79 | 55.45 |
| GTX-2080ti | PyTorch | Efficientnet-B0 | 7.28 | 63.25 | NaN |
| GTX-2080ti | TensorFlow | Efficientnet-B3 | 8.60 | 70.40 | NaN |
| Coral (Dev. Board) | Edge TPU | Efficientnet-M | 10.72 | 45.53 | 67.67 |
| GTX-2080ti | PyTorch | Efficientnet-B3 | 11.13 | 69.80 | NaN |
| GTX-2080ti | TensorFlow | Resnet-50 | 11.40 | 54.30 | NaN |
| Coral (USB Accelerator) | Edge TPU | Efficientnet-S | 13.18 | 33.79 | 55.45 |
| Coral (Dev. Board) | Edge TPU | Efficientnet-L | 30.72 | 42.92 | 65.06 |
| Jetson Nano | PyTorch | Resnet-50 | 35.67 | 64.30 | NaN |
| Intel NCS2 | OpenVINO | Resnet-50 | 58.40 | 48.00 | 72.80 |
| Coral (USB Accelerator) | Edge TPU | Efficientnet-M | 59.62 | 45.53 | 67.67 |
| Jetson Nano | PyTorch | Efficientnet-B0 | 59.97 | 61.64 | NaN |
| Jetson Nano | PyTorch | Efficientnet-B3 | 96.94 | 67.97 | NaN |
| Jetson Nano | TensorFlow | Efficientnet-B0 | 98.78 | 79.61 | NaN |
| Jetson Nano | TF-TensorRT | Efficientnet-B0 | 154.13 | 79.61 | NaN |
| Jetson Nano | TF-TensorRT | Resnet-50 | 176.50 | 54.10 | NaN |
| Intel Movidius | OpenVINO | Resnet-50 | 186.40 | 47.90 | 72.80 |
| Jetson Nano | TensorFlow | Resnet-50 | 223.73 | 54.10 | NaN |
| Coral (USB Accelerator) | Edge TPU | Efficientnet-L | 225.28 | 42.92 | 65.06 |
| Jetson Nano | TensorFlow | Efficientnet-B3 | 246.26 | 85.44 | NaN |
| Jetson Nano | PyTorch | Efficientnet-B5 | 261.27 | 72.03 | NaN |
| Jetson Nano | TF-TensorRT | Efficientnet-B3 | 327.28 | 85.44 | NaN |
| Raspberry Pi 3B | TensorFlow | Efficientnet-B0 | 539.15 | 80.00 | NaN |
| Raspberry Pi 3B | TensorFlow | Resnet-50 | 1660.55 | 67.00 | NaN |
| Raspberry Pi 3B | TensorFlow | Efficientnet-B3 | 1891.05 | 81.00 | NaN |
| Raspberry Pi 3B | PyTorch | Resnet-50 | 3915.22 | 79.00 | NaN |
| Raspberry Pi 3B | PyTorch | Efficientnet-B0 | 6908.80 | 78.00 | NaN |
| Raspberry Pi 3B | PyTorch | Efficientnet-B3 | 13685.62 | 79.00 | NaN |
Inference time winner #1: Jetson Nano
In terms of inference time, the winner is the Jetson Nano in combination with ResNet-50, TensorRT, and PyTorch. It finished in 2.67 milliseconds, which is 375 frames per second.
This result was surprising since it outperformed the inferencing rate publicized by NVIDIA by a factor of 10x. This difference in results is most likely related to the fact that NVIDIA used TensorFlow instead of PyTorch.
Inference time winner #2: Coral Dev. Board
Coming in second was the combination of Coral Dev. Board with EfficientNet-S. It finished in 5.42 milliseconds, which is 185 frames per second.
These results correspond with the 5.5 milliseconds and 182 frames per second, promised by Google.
Even though speed was high for this combination, accuracy was not. We couldn’t acquire the exact validation set used by Google for accuracy reporting, but one hypothesis is that they used the image preprocessing transformations differently than we did. Since quantized 8-bit models are very sensitive to image preprocessing, this could have had a major impact on the results.
Accuracy winner: Jetson Nano
The best results in terms of accuracy came from the Jetson Nano in combination with TF-TRT and EfficentNet-B3, which attained an accuracy of over 85%. However, these results are relative, since we trained some models using a bigger dataset than others.
We can see that the accuracy rate is higher when we feed the models smaller datasets, and lower when the entire dataset is used. This results from the fact that we didn’t randomly sort the smaller data sets and hence the images were not adequately balanced.
Usability of hardware accelerators
Concerning the usability of these devices, developers will note some major differences.
The Jetson was the most flexible when it came to selecting and employing precompiled models and frameworks. Intel sticks come in second since they provide good libraries, many models and cool projects. Moreover, the sticks have massively improved between the first and second editions. The only drawback is that their vast library, OpenVINO is only supported on Ubuntu 16.04 and not by later Linux OS versions.
Compared to Jetson and Intel sticks, Coral devices present some limitations. If you want to run non-official models on it, you have to convert them to TensorFlow Lite, then quantize and compile them for Edge TPU. Depending on the model, this conversion might not be feasible. Nevertheless, we expect improvements for this Google device with future generations.
Conclusions
The research presented here is based on our exploration of state-of-the-art edge computing devices designed for deep learning algorithms.
We found that the Jetson Nano and Coral Dev. Board performed very well in terms of inference time.
In terms of accuracy, the Jetson Nano once again achieved great results, though the results were relative.
Given the overall performance of the Jetson Nano, it was our clear winner.
However, we must mention that we couldn’t test the Jetson Nano and Coral with the same model, due to their different design. We believe that each device will have its own best-case scenario, depending on the specific task to be completed.
We encourage you to perform a detailed benchmarking as it pertains to your specific tasks, and share your results and conclusions in the comments section below. Further research of interest could include the design and training of your own model, utilizing quantization-aware training.
This blog post was written in collaboration with Guillermo Ripa, Full-stack Developer at Tryolabs.
Juan Pablo González
Research and Machine Learning Engineer, Tryolabs