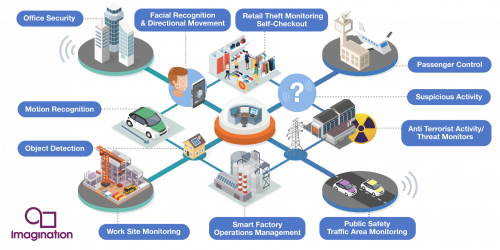
Implementing the Data Flywheel
This article was originally published at Hasty’s website. It is reprinted here with the permission of Hasty. As the ML space is maturing, processes and best practices for what happens after you successfully manage a first project launch are becoming more popular. In this article, we are going through the concept of a data flywheel […]
Implementing the Data Flywheel Read More +