This article was originally published at Imagination Technologies' website, where it is one of a series of articles. It is reprinted here with the permission of Imagination Technologies.
Computer vision is the use of computers to extract useful meaning from images, such as those that arise from photographs, video and real-time camera feeds. Thanks to the proliferation of low-power parallel processors, the increasing availability of 3D sensors and an active ecosystem of algorithm developers, it is now possible for many embedded devices to analyse their environments on-demand or in always-on states of contextual awareness.
The market demand for embedded vision products is large and growing, spanning consumer products such as handsets, notebooks, televisions, wearables, automotive safety, security and data analytics. Recent data from ABI, Gartner and TSR predicts that the Total Available Market (TAM) for smart camera products in 2019 will exceed three billion units.
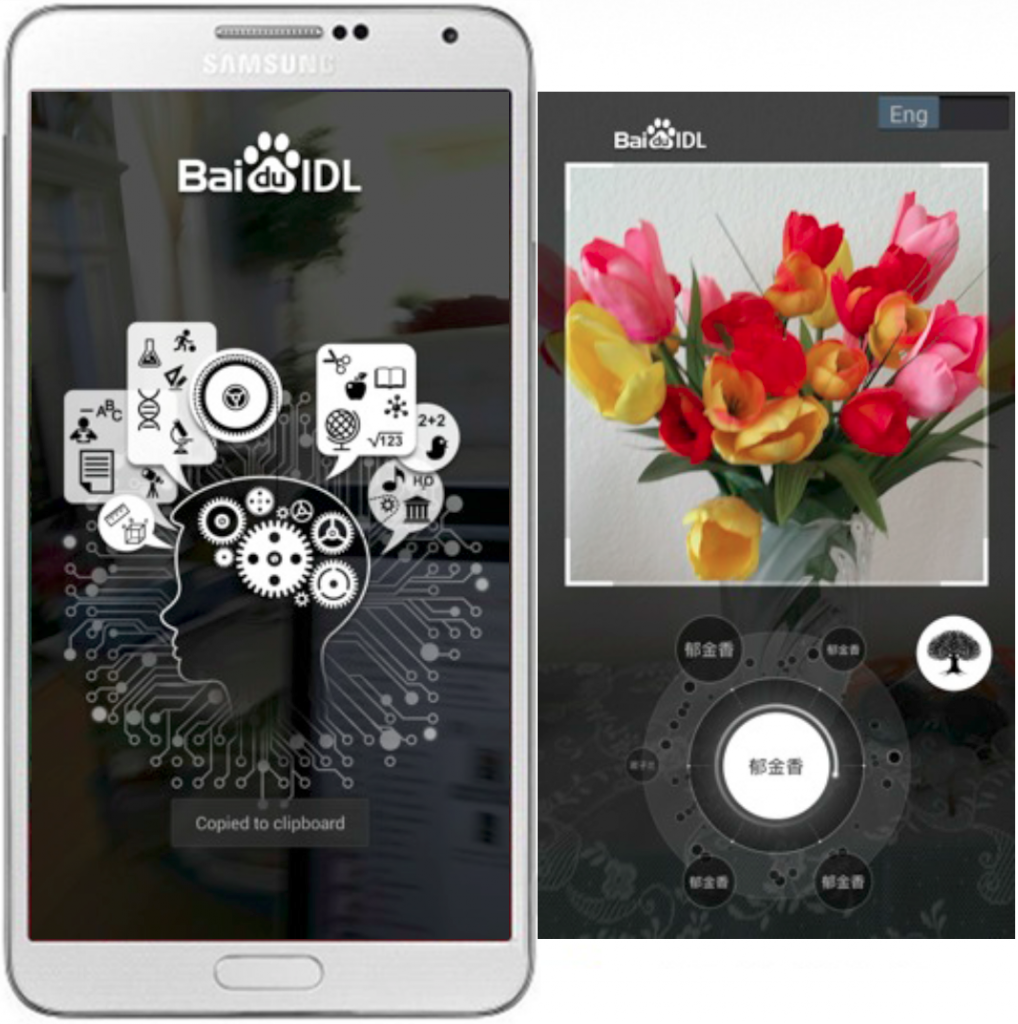
Consumer use cases for computer vision include computational photography, augmented reality, gesture control and scene understanding. Today many phones automatically adjust camera focus and exposure by detecting the presence of a face, while phones such as the MeituKiss can also beautify the face in real-time. At a recent Embedded Vision Alliance meeting, Baidu presented a Deep Neural Network (DNN) app that allows users to identify thousands of objects directly from the camera input stream in real-time. Baidu implemented their neural network on a mobile application processor, using a PowerVR GPU to match images against a database of thousands of objects in real-time.
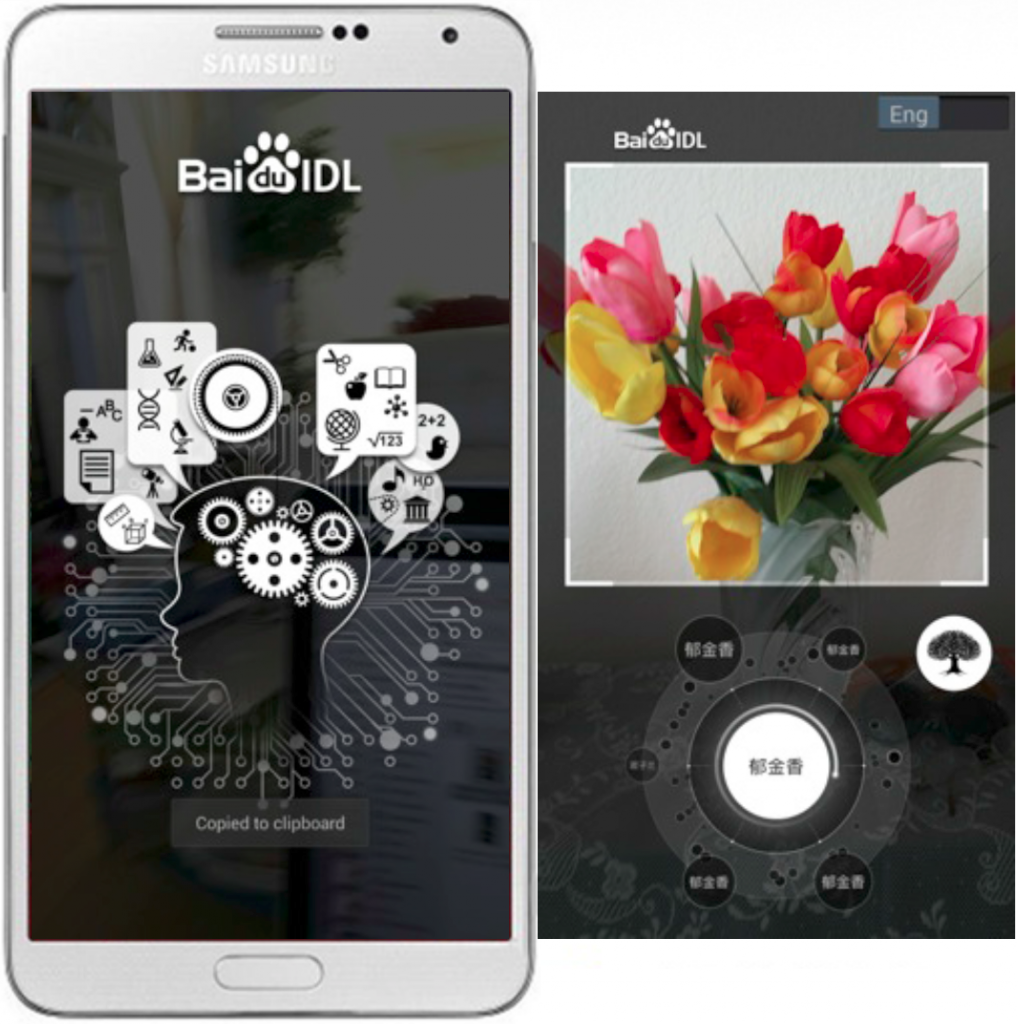
Baidu offline mobile DNN app
In the automotive market, adding computer vision into motor vehicles can reduce and mitigate accidents. For example, each year Americans clock up a couple of trillion miles of driving and are involved in around six million motor vehicle accidents. In comparison Google’s self-driving prototype cars have now completed over one million miles of driving on public roads without causing a single accident due to computer error, highlighting the enormous potential of computer vision to transform this market. Today many manufacturers offer Advanced Driver Assistance Systems (ADAS) that use visual data as well as traditional technologies such as radar and LIDAR to perform safety-critical functions such as blind spot detection, pedestrian detection and autonomous emergency braking.
In the surveillance market, adding computer vision into security cameras reduces CCTV operator costs while improving reliability, for example through use of advanced crowd analysis algorithms that identify the presence of objects such as concealed weapons by detecting subtle changes in walking patterns. In the consumer segment, security products from companies such as Nest alert users by smartphone when there is motion in their home, filtering out unimportant activity such as shadows moving across a wall or trees moving in the wind outside.
In retail environments such as supermarkets that have traditionally relied on payment and store loyalty cards to track consumer behaviour, computer vision is being used to uncover new customer insights. Retail cameras from companies such as Vadaro can identify whether a person is new to the store or is a returning customer, estimating their age, gender, dwell time and attention to products. As well as providing valuable feedback to retailers and advertisers, these cameras can also help improve customer service by automating tasks such as counting the number of people waiting in a queue.

Vadaro Eagle retail analytics sensor
Computer vision algorithms
Computer vision algorithms involve many different types of tasks, typically arranged in a pipeline formation such as the example shown below.

Typical computer vision processing pipeline
- Image pre-processing includes tasks such as noise reduction, normalizing colour and gamma values and de-warping.
- Feature detection and description identifies points and regions in the image that can be measured with high precision. Subsequent stages of the processing can then operate on this reduced set of features instead of the full-size image, reducing computational complexity.
- Image registration aligns multiple images to simplify pixel-level comparisons, for example to enable the images to be stitched together as a panorama or HDR image.
- Depth calculation improves the performance and robustness of vision algorithms that require an understanding of three-dimensional space such as 3D model reconstruction.
- Object recognition identifies groups of pixels or features that represent classes of objects. Due to the complexity of this task, many algorithms are based on machine learning and artificial intelligence techniques.
- Motion analysis extracts information from multiple frames of video, for example to help predict the trajectory of objects such as cars or pedestrians over time.
- Heuristics facilitate split-second decision making, for example to allow a fast-moving vehicle to make a corrective manoeuvre.
Feature detection and description
Feature detection transforms an image containing a large set of pixels into a reduced representation set of feature points known as a feature vector (or descriptor). A good algorithm extracts the relevant information from the input data in order to enable the subsequent vision tasks to be performed using this reduced representation instead of the full set of image. Common features include edges, corners and regions that share properties such as brightness or colour (referred to as blobs). Well-known feature detectors include the Sobel and Canny edge detectors, the Harris and FAST corner detectors, and the Difference-of-Gaussian (DoG) blob detector. Examples are shown below.

Edges, Corners and Difference-of-Gaussians
Scale Invariant Feature Transform
SIFT (Scale Invariant Feature Transform) is one of the earliest and most accurate feature detectors available. SIFT detects blobs from the extrema of DoGs, incorporating a variant of Harris detection to discard edge-like features. As shown in the figure below, the SIFT algorithm computes a DoG pyramid for an image at multiple scales (or octaves). At each octave, multiple blurred images are obtained by convolving an image with the Gaussian kernel, which suppresses high-frequency spatial information. The DoG operation subtracts one blurred image from another less blurred version of the same image, thereby preserving spatial information between a range of frequencies. Successive octaves are computed by downsampling one of the blurred images by a factor of two and repeating the computations. The final output is a mipmap that includes multiple DoG images for each octave, containing areas of high variation that represent unique points.
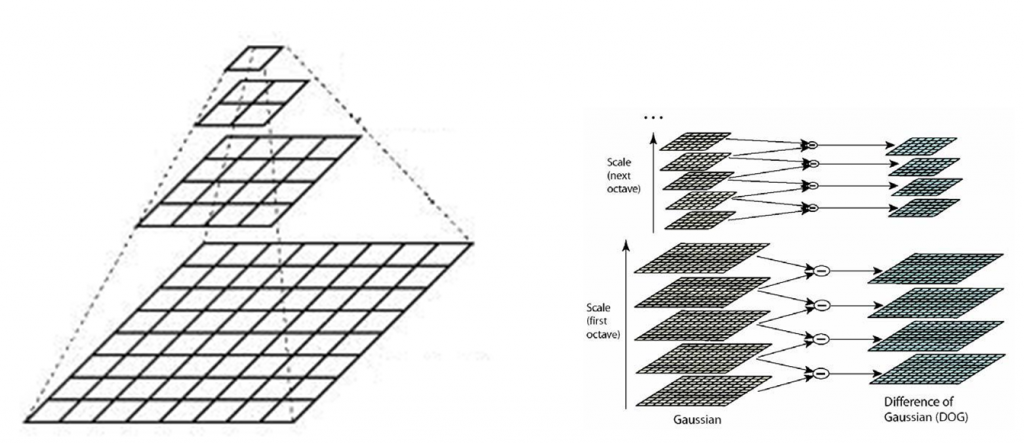
Differences-of-Gaussian pyramid
Speeded up robust features
SIFT is highly accurate but is also computationally expensive, making it impractical for real-time execution on an embedded device. The SURF (Speeded Up Robust Features) detector was therefore subsequently developed with implementation efficiency in mind. SURF replaces SIFT’s numerous convolution operations with a series of simpler rectangular filters that approximate Gaussian smoothing. These filters can be implemented very efficiently by first precomputing an integral image and storing it in an array. As shown in the figure below, the integral image at location A is the sum of the pixel intensities above and to the left, and the sum-of-pixels within the rectangle can be computed in constant time with just four array references by calculating D-B-C+A.
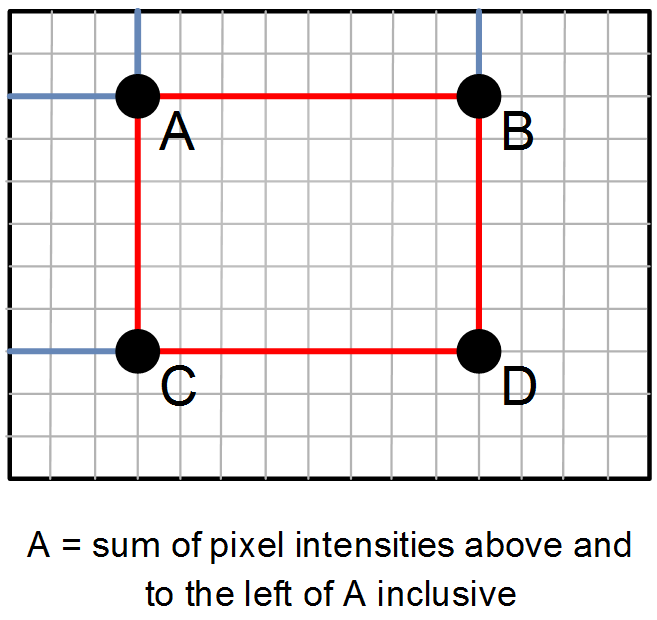
Integral image
Haar-like features
The popular Viola-Jones face detection algorithm also uses rectangular features, known as Haar-like features, as shown in the figure below. These features are calculated as the sum-of-pixels within clear rectangles subtracted from the sum-of-pixels within shaded rectangles, and are used to find properties in an image that are similar to regions of a face, for example the eyes region is darker than the upper-cheeks (Feature B) and the nose bridge region is brighter than the eyes (Feature C). By operating at this region-level of granularity, Haar-like features are effective in finding faces irrespective of variations in facial expressions.
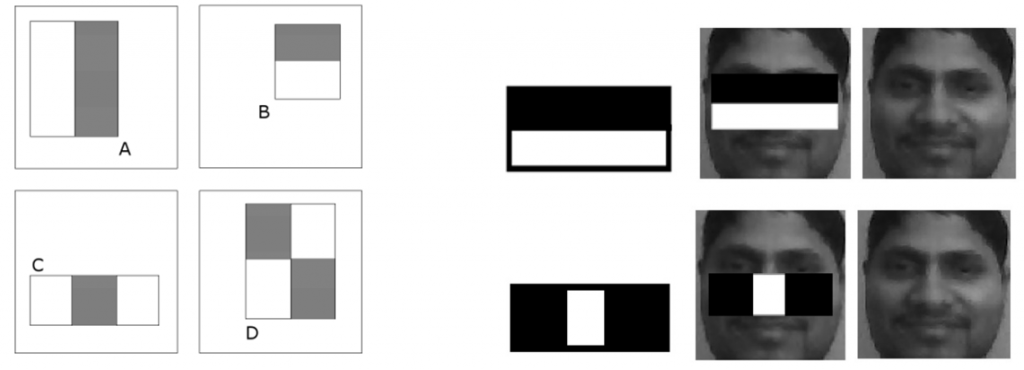
Four feature types used by Viola-Jones object detection framework
Histograms of Oriented Gradients
Another popular feature descriptor is the Histograms of Oriented Gradients (HOG), used in many automotive ADAS systems to detect pedestrians. As shown in figure below, HOG divides the image into cells that describe the local appearance of objects by the distribution of intensity gradients. The gradient structure captured in these cells is characteristic of local shape and tolerant to small changes in local geometry, which makes HOG suitable for detecting people in an upright position irrespective of minor variations in body movement.
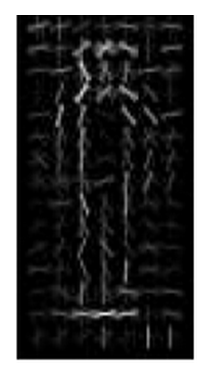
HOG representation of pedestrian
HOG computes gradient values by filtering the image with a convolution kernel. Each pixel within a cell then casts a weighted vote for an orientation-based histogram channel based on its gradient computation, and the cells are grouped into larger blocks that are locally normalized to account for changes in illumination and contrast. HOG operates on images at a single scale without orientation alignment, making it computationally cheaper than SIFT. However, the convolution and histogram computations required by HOG are more computationally expensive than SURF’s addition and subtraction operations performed on integral images.
Object recognition
Object recognition identifies groups of pixels in an image that represent objects of a certain class such as humans or cars. Due to the computational complexity of this task many algorithms are based on machine learning and artificial intelligence, for example using a cascade classifier or a neural network. An offline training step is usually first performed, producing a database against which new images can be subsequently matched. This training step is very computationally expensive, possibly taking days or weeks to perform on a supercomputer. However, matching new images against the database is much less expensive, suitable for execution in real-time on an embedded device.
Cascade classifiers
The Viola-Jones face detection framework uses a learning algorithm to select the best face features and trains classifiers that use them. The matching algorithm moves a sliding window over an image using Haar-like features to detect possible matches. Haar-like features are weak classifiers that are very inaccurate in isolation, so Viola-Jones uses a linear combination of weighted weak classifiers, known as a boosted classifier, which balances performance and accuracy by allowing the algorithm to reject non-face images quickly while detecting faces with high probability. As shown in the diagram below, at each stage of the cascade the image in the current window is tested against a small number of features: those that fail are rejected and those that pass progress to the next stage. The classifier trained by Viola and Jones uses a 38-stage cascade of gradually increasing complexity. The first classifier is a simple attentional operator that uses two features to achieve a false negative rate of approximately 0% and a false positive rate of 40%, roughly halving the number of times the entire cascade is evaluated.
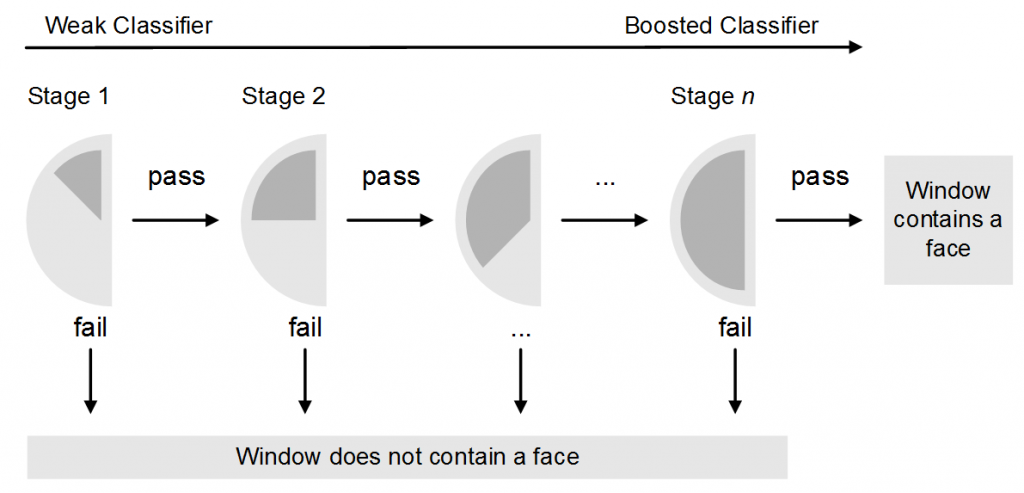
Haar cascade classifier
Support Vector Machines
A cascade is useful when the space of possible features is large, since it focuses on only the features that perform the best and work well together. In cases where all of the features contribute significantly to the solution, for example pedestrian detection algorithms based on HOG features, a simpler algorithm based on supervised learning is often used. An example is Support Vector Machines (SVMs), which use learning algorithms to can recognize patterns in images. In comparison to boosting, which intelligently combines many weak classifiers, SVM build a model that assigns an image into one of two categories based on a set of training examples. The SVM model is a mathematical representation of the training examples as points in space, mapped so that examples of the separate categories are divided by a clear gap that is as wide as possible.
Once trained on images containing a particular object, the SVM classifier provides a confidence level on the presence of that object in other image, which can be thresholded to produce a binary decision. Training and matching with an SVM-based classifier has the advantage of being simpler than with a cascade, but is also computationally more expensive.
Convolution Neural Networks
The requirement for accurate detection of a large and diverse range of objects is driving much of the recent research in hierarchical machine learning models such as Convolution Neural Networks (CNN), which attempt to mimic the human visual system. As shown in the figure below, the core operations performed by CNNs are image convolution and downsampling. The convolution filter coordinates are weights that represent the strength of the connection between neurons, while the downsampling operations enable objects to be found at different scales. These operations are repeated a number of times, producing a set of high-level features that are fed into a fully-connected graph that determines a final set of output predictions.
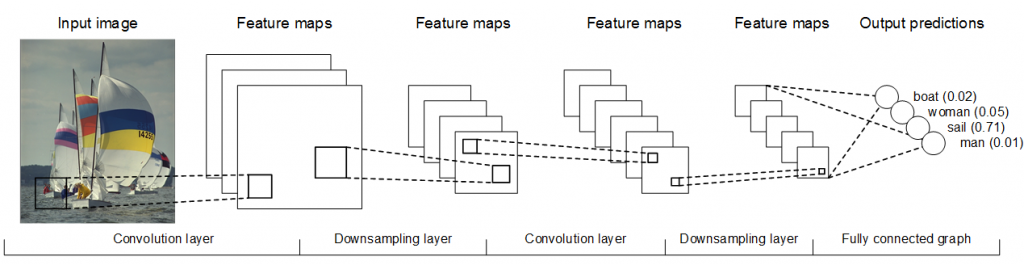
CNN framework
Because CNNs perform convolution operations for every image pixel, they are more computationally expensive than other approaches to object detection based on hand-designed features such as SURF and HOG. With added complexity comes improved accuracy though: CNN-based detectors have topped many recent studies into object detection quality. Furthermore, because trained CNNs store all of their knowledge entirely in the learned parameters, they can be easily tuned to many different types of objects without changing the underlying algorithm. This combination of accuracy and flexibility has led to a recent surge in popularity, with mainstream adoption considered likely in the near future.
Further reading
Computer vision is what we’ll be focusing on for the next section of our heterogeneous compute series; stay tuned for an overview of how you build a computer vision platform for mobile and embedded devices.
By Doug Watt
Multimedia Strategy Manager, Imagination Technologies