This blog post was originally published in the mid-March 2017 edition of BDTI's InsideDSP newsletter. It is reprinted here with the permission of BDTI.
It's remarkable to see the range of applications in which deep neural networks are proving effective – often, significantly more effective than previously known techniques. From speech recognition to ranking web search results to object recognition, each day brings a new product or published paper with a new challenge tamed by deep learning.
Computer vision, of course, is a field with significant deep learning activity. Deep learning is particularly appealing for visual perception because image and video data is massive and rich with information, but is infinitely variable and often ambiguous.
As I mentioned in my column last month, researchers have demonstrated deep neural networks capable of classifying skin lesions as cancerous or benign with accuracy equivalent to that of dermatologists, and other deep networks capable of reading lips with significantly higher accuracy than human lip readers. More recently, Shunsuke Saito, Lingyu Wei and colleagues have developed a deep-learning-based approach that generates photorealistic 3D models of human faces from a single 2D image.
This naturally leads to the question: Will deep learning displace all other techniques for solving visual perception problems?
While the power of deep learning is undeniable, I believe that other techniques will continue to be attractive. As in most fields, it's a question of choosing the right tool for the job.
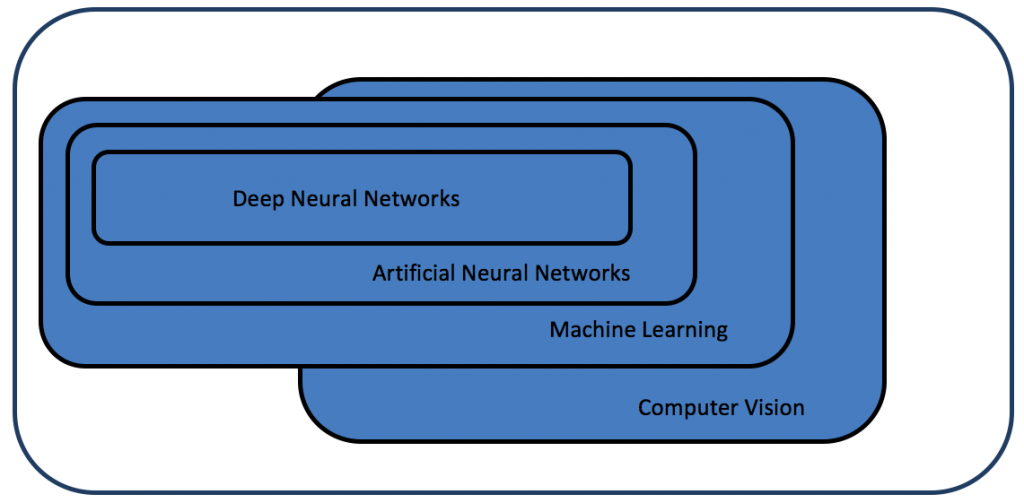
With the current justifiable excitement around deep learning, one important point that often gets overlooked is that machine learning encompasses a vast range of techniques, of which neural networks are a subset (as shown in Figure 1). In turn, deep neural networks are a subset of a broader class of neural network techniques.
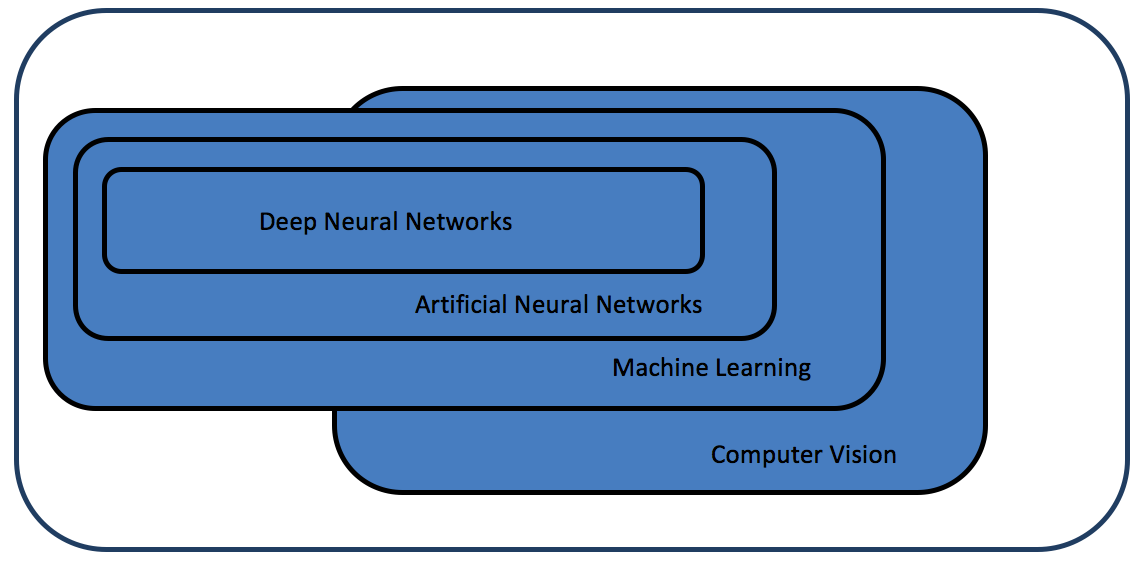
Figure 1. Artificial neural networks are a subset of machine learning techniques, and deep neural networks are a subset of artificial neural networks. All of these machine learning techniques are used in computer vision – and for other fields.
In many cases, simpler machine learning techniques are effective. That's fortunate, because deep learning has a deep appetite: massive amounts of data and compute power are needed for training deep networks, and substantial compute power is needed for running trained networks. Other machine learning techniques often get by with comparatively minuscule amounts of data and processing power.
Well before the start of the current deep learning craze, a few pioneering researchers and companies, such as BrainChip and General Vision, were deploying what we might today call "shallow learning" algorithms and processors to solve real-world problems ranging from fish identification to license-plate recognition.
Today, there's a huge rush to apply deep learning to every visual perception problem. But, particularly when development costs and deployment costs are considered, I think that in many cases, other techniques will prove preferable. The challenge for algorithm, system, and product developers will be how to discern which tasks call for deep learning, which call for other neural network techniques, which are best served by other machine learning approaches, and which are still appropriate for good old-fashioned hand-crafted algorithms.
We're fortunate to have some true experts lined up to share their expertise on the trade-offs among deep learning and other vision techniques at the 2017 Embedded Vision Summit, taking place May 1-3, 2017 in Santa Clara, California. We'll be hearing from Alex Winter, who recently sold his start-up Placemeter to Netgear; Cormac Brick of Intel's recently acquired Movidius group; and Ilya Brailovsky of Amazon's Lab126 on these topics.
My colleagues and I at the Embedded Vision Alliance have put together a world-class program of presentations and demonstrations, with emphasis on deep learning, 3D perception, and energy-efficient implementation. If you're interested in implementing visual intelligence in real-world devices, mark your calendar and plan to be there. I look forward to seeing you in Santa Clara!
Jeff Bier
Co-Founder and President, BDTI
Founder, Embedded Vision Alliance