This blog post was originally published at Intel's website. It is reprinted here with the permission of Intel.
AI is now fast defining the next major era of computing, thanks to the pioneering work of David Rumelhart, Geoffrey Hinton, Yann LeCun, Yoshua Bengio, and many others over the past few decades. Yet ongoing progress in a field like AI is not assured without ongoing innovation. This requires technology diversification, investments in basic research, and an open mind to disruptive ideas.
To that end, one approach we are exploring at Intel follows the path proposed in the 1980s by Carver Mead, one of the fathers of VLSI, an approach we now call neuromorphic computing. This approach looks to the workings of biological neurons, as understood by modern neuroscience, to capture the wealth of algorithmic, performance, and efficiency innovations that nature has deployed in the brains of organisms.
The Case for Spiking Neural Networks
Neuromorphic computing seeks to exploit many properties of neural architectures found in nature, such as fully integrated memory-and-computing, fine-grain parallelism, pervasive feedback and recurrence, massive network fan-outs, low precision and stochastic computation, and continuously adaptive and oftentimes rapidly self-modifying processes we understand as learning. Of all of these properties, none receives more attention than the use of “spikes” as the basic currency of computation.
“Let time represent itself,” Carver Mead would say, referring to the second-class status we assign to time by relegating it to a mere number or an index into a vector of data samples. We conventionally regard computation as happening in time – the less time, the better. The brain actually computes with time, treating it as a first-class citizen in its computational processes.
Computation with time fundamentally turns a system into a dynamical process, where the evolution of the system over time, whether fast or slow, becomes the computation itself. For some profound reason, spikes – discrete events that convey nothing or very little besides the specific time of the spike – emerge in such natural computing systems. Spikes are observed traveling over the membranes of amoebas in response to stimuli, between bacteria to coordinate biofilm growth, and even in trees where minutes-long spikes signal environmental change. Inside the brain, spikes known as action potentials convey the vast majority of all information between its neurons. Yet the notion of time and spikes are conspicuously missing from our conventional neural network models in wide use today.
Earlier this year, I gave talks on our neuromorphic research at the Cosyne computational neuroscience conference in Lisbon and at ISSCC in San Francisco. The topic of spikes evoked vibrant debate at both events, beginning front and center at the conclusion of Yann LeCun’s keynote at ISSCC. At Cosyne, a workshop titled “Why Spikes” made it clear that even neuroscientists aren’t convinced that spikes are necessary for understanding the workings of the brain, with influential researchers like Peter Latham preferring continuous rate models that use real-valued numbers, rather than single-bit impulses, to represent neural activity.
Skepticism and debate are healthy and welcome in any scientific field. Ultimately, any technical debate should be decided on evidence and results, which is what I hope to offer here to justify why, in our research, we see exciting potential for neuromorphic architectures that harness spikes for signaling and temporal models of neurons known as spiking neural networks (SNNs). Of course, Intel is in the business of delivering platform and technology advancements that solve a wide range of real-world problems. To that end, we have three specific areas where we think spikes may offer great advantage: energy efficiency, fast responses, and rapid learning. With Loihi, our neuromorphic research chip, we are accumulating evidence that supports this belief.
In the course of a five-part blog series, I’ll share some of our findings to date across five different categories. Many of these results are not yet published, so view this as a preview of more complete technical reports to come. For background information on our Loihi chip, I recommend you first take a look at our IEEE Micro publication (Davies, et al. 2018) from last year. Let’s dive in to part one of “Why spiking neural networks?” Parts 2-5 will be shared in the coming weeks.
Spikes optimize bits per Joule, not bits per second
Traditional information theory relates to maximizing bandwidth, or the amount of information transmitted over a communication channel subject to noise limits. Arguably for the brain and for scalable AI architectures, maximizing energy efficiency, or bits-per-Joule, is the more important objective.
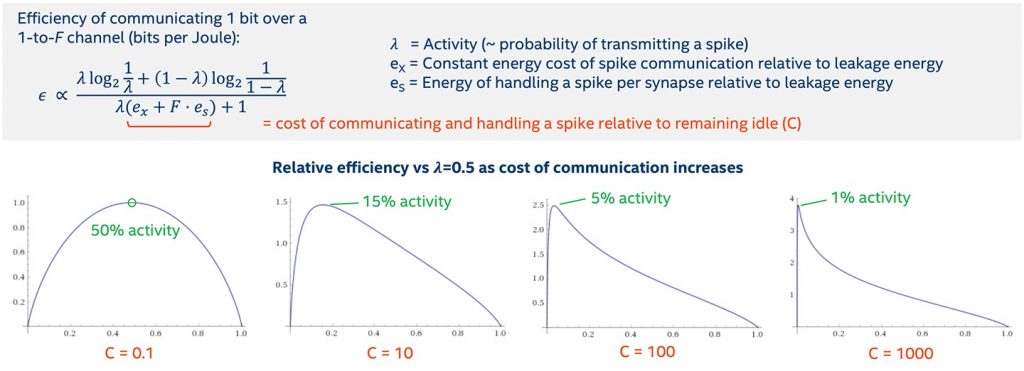
It turns out that a simple, first principle analysis of this question leads immediately to a preference for sparse communication in any system where there is an asymmetry in energy expenditure between sending a ‘1’ versus sending a ‘0’ (or not sending). In such systems, the most energetically optimal state is to transmit infrequently with some activity level less than 50 percent. This basic physical fact biases all systems to adopt spike-based communication, if we abstract our understanding of “spike” to cover both the action potentials in nature as well as the packetized messages carrying routing information in our computing systems.

Figure 1: Relative efficiency as Cost of Communication Increases.
The key insight that nature and our neuromorphic chips exploit is that the particular timing of spike transmission can be used to convey information while maintaining a constant level of sparsity, thereby remaining in the energy optimal sweet spot. Rather than sending information more frequently or adding expensive graded payloads to each message (such as activity values that must be multiplied at each destination neuron with a cost that increases quadratically with the payload bit width), relative timing alignments across channels can greatly expand the coding capacity with arbitrarily low activity level and minimal complexity for servicing each spike, as shown in Figure 1.
All told, this theoretic perspective tells us that we should adopt spike-based protocols in any large-scale neural system where communication is costly, idle power is low relative to synaptic activity, high network fan-out factors are desirable, and the cost of computation at the destination grows excessively with increasing payload size. This matches the regime of neural-inspired computation, whether biological or neuromorphic. It’s therefore no surprise that nature developed computational algorithms that leverage spikes, and we probably should too.
It’s interesting to note that in the biological regime, studies have shown that the optimal activity level can correspond to sending less than one bit per spike, and this may explain why the transmission of spikes across a synapse is probabilistic in nature, with typically only 25 percent of spikes propagating in some brain regions (Harris, Jolivet and Attwell, 2012). Due to differences in Loihi’s architecture compared to natural brains, our optimal point isn’t quite so hyper-sparse, and as a result we chose not to implement probabilistic synaptic transmission.
Conclusion
From a theoretical perspective, sparse spiking activity in time promises intriguing energy savings for suitable architectures. We designed Loihi with this principle in mind. In the next four parts of this blog, I’ll share some of our actual measured results showing how Loihi delivers on this promise. These include examples of surprisingly rapid convergence as Loihi executes certain recurrent networks, efficient processing of temporal data streams, algorithms that compute with time, and a new class called Phasor Neural Networks. Stay tuned for Part 2, and, as always, follow us on @IntelAI and @IntelAIResearch for the latest news and information from the Intel AI team.
Mike Davies
Director, Neuromorphic Computing Lab, Intel