This blog post was originally published at NVIDIA's website. It is reprinted here with the permission of NVIDIA.
Let’s imagine a situation. You buy a brand-new, cutting-edge, Volta-powered DGX-2 server. You’ve done your math right, expecting a 2x performance increase in ResNet50 training over the DGX-1 you had before. You plug it into your rack cabinet and run the training. That’s when an unpleasant surprise pops up. Even though your math is correct, the speedup you’re getting lower than expected. Why? What can you do about it? Can DALI, aka the NVIDIA Data Loading Library, help you here?
When deep learning engineers hear “image classification”, they think about ResNet. Since its publication in 2015 ResNet became a widely recognized standard, and despite numerous descendants and later works, it still encompasses most classification tasks. Even though the residual architecture is considered computationally lighter than the classic deep neural network, ResNet still carries out a lot of processing, especially for CPU-based dataset augmentations. One reason why you are not observing the anticipated speed boost might be the large amount of computations CPU needs to perform, resulting in a bottleneck in this part of hardware.
The Bottleneck
To verify that CPU is indeed the bottleneck in our training, let’s conduct a simple experiment. Normally the preprocessing of dataset is performed on the CPU (using libraries like NumPy or Pillow) while the training runs on the GPU. Furthermore, they work in parallel – the CPU processing of a batch runs at the same time that the GPU conducts forward and back propagation of the previous batch.
Let’s compare the speed of a regular ResNet50 data processing pipeline and a synthetic pipeline, in which no data augmentation occurs, only training. At this point we don’t care that the neural network won’t train; all we need is to compare the performance of the two pipelines.
If we observe no performance difference between these two pipelines in our experiment, then the CPU workload proves irrelevant. On the other hand, if we discover lower speed in the regular pipeline, it means that the CPU is the likely bottleneck for training.
Indeed, as table 1 shows, we observe a difference in the performance of these two pipelines. This observation indicates a bottleneck within the preprocessing pipeline occuring on the CPU. To address this situation, we can make use of DALI – the library exclusively designed to offload the preprocessing from CPU to GPU, thereby reducing or eliminating the CPU bottleneck.
|
Benchmark Type |
DGX-2 |
|
Regular ResNet50 training speed |
12,586 |
|
Synthetic ResNet50 training speed |
22,656 |
Benchmarking
Throughout this article we measure the time performance (in images per second) of ResNet50 training. The script that used is available on NVIDIA’s DeepLearningExamples GitHub page. The script allows the training to be run on both DALI and native data preprocessing pipelines.
We base our training on the ImageNet dataset from the original ResNet50. Every epoch consists of 1,281,167 images. The MXNet framework is used to conduct the training. We use NGC Container, version 19.04 to maintain a consistent software configuration.
In addition, the hardware setups used for training are shown in Table 2:
| System | Number of GPUs | Batch Size |
| NVIDIA DGX-2 | 16 | 256 |
| AWS P3 | 8 | 192 |
| NVIDIA TITAN RTX | 1 | 128 |
We conducted trainings using the same set of hyperparameters to achieve the most accurate training speed comparison. The batch size and number of GPUs differ only from one hardware setup to the other, as shown above. Table 3 highlights the performance metrics for regular and synthetic ResNet50, using the hardware setups specified above.
|
Pipeline Type |
DGX-2 |
AWS P3 |
TITAN RTX |
|
Standard Preprocessing Pipeline |
12,586 |
5,740 |
553 |
|
Synthetic Preprocessing Pipeline (images/sec) |
22,656 |
10,738 |
585 |
Augmentations for ResNet50
Prior to plugging the DALI in, let’s list all the data processing operations, including augmentations, that occur within the ResNet50 preprocessing pipeline:
- Read raw image data
- Decode the image
- Resize
- Random crop
- Random horizontal flip
- Normalize
- Transpose
Every image is stored in a compressed format (such as JPEG). We need to first decode the image in order to process it. Although image decoding is not widely recognized as a preprocessing operation, it always occurs and consumes significant portion of total preprocessing time.
Without delving into a detailed description of every operation, let’s mention a few things. First, both crop and horizontal flip operations are performed randomly. In other words, determine on a given probability distribution whether to perform such operation and to what extent. Next, transposing (changing NHWC data layout to NCHW) is not part of ResNet50 itself. Instead, it is a part of the framework-dependent implementation – we want to transform the layout to a format that MXNet works best with.
Last, notice that the training script actually used two different data pipelines: one for training and another for validation, as shown in figures 2 and 3. The latter is just a subset of the former. Validation only performs operations required for formatting the input data to match the network’s input. This article focuses only on DALI pipeline for training.

Figure 1: ResNet50 training data preprocessing pipeline

Figure 2: ResNet50 validation data preprocessing pipeline
Applying Augmentations in DALI
Now that we have listed all the augmentations, let’s set up the DALI pipeline and plug it into ResNet50 training. For the sake of readability, we present simplified code snippets. See the script on GitHub for a complete working example.
Let’s declare the required augmentations:
class HybridTrainPipe(Pipeline):
def __init__(self):
super(HybridTrainPipe, self).__init__()
self.input = ops.MXNetReader(path = [rec_path])
self.decode = ops.nvJPEGDecoder(device = "mixed")
self.rrc = ops.RandomResizedCrop(device = "gpu", size = crop_shape)
self.cmnp = ops.CropMirrorNormalize(device = "gpu", crop = crop_shape)
self.coin = ops.CoinFlip()
And define the preprocessing graph:
def define_graph(self):
rng = self.coin()
self.jpegs, self.labels = self.input(name = "Reader")
images = self.decode(self.jpegs)
images = self.rrc(images)
output = self.cmnp(images, mirror = rng)
return [output, self.labels]
The code is mostly self-explanatory; more detail can be found in the DALI Developer Guide. Images get decoded and then piped through all the augmentations listed in the previous section. Note the CoinFlip operator, which is a special case of an operator. It takes no input and produces output used to drive those operators that perform random operations. Also, you can see that we use two types of devices when declaring operations: gpu and mixed. The first one is quite obvious, whereas the second one denotes an operation which works on both CPU and GPU. Image decoding represents such an operation, since the CPU has to read image from disk and transfer it to GPU memory, where the image is decoded.
Now that we have DALI defined and ready to go, let’s plug it into the training and check the time measurements; you can see the results in table 4. Refer to our examples to see how to plug DALI into a deep learning framework.
|
|
DGX-2 |
AWS P3 |
TITAN RTX |
|
Performance |
21,034 |
10,138 |
575 |
Fusing Operations
Take a closer look at the HybridTrainPipe. You may notice that some operations are fused together into one operator, such as Resize combined with Crop. This represents a common pattern with an underlying simple idea. Performing multiple operations in one GPU CUDA kernel reduces the number of memory accesses, making overall training more performant.
Fused operators bring yet another optimization trick to the table. The ResNet50 preprocessing pipeline contains an image crop operation. Is it really necessary to decode the whole image, including parts discarded at a later stage? Simply put, no. A little assistance from nvJPEG, allows us to perform region-of-interest (ROI) decoding – cropping an image and decoding only its undiscarded parts.
Let’s introduce nvJPEGDecoderRandomCrop operator into the pipeline:
class HybridTrainPipe(Pipeline):
def __init__(self):
super(HybridTrainPipe, self).__init__()
self.input = ops.MXNetReader(path = [rec_path])
self.decode = ops.nvJPEGDecoderRandomCrop(device = "mixed",
random_aspect_ratio = [min_random_aspect_ratio, max_random_aspect_ratio])
self.resize = ops.Resize(device="gpu", resize_x = crop_shape[0], resize_y = crop_shape[1])
self.cmnp = ops.CropMirrorNormalize(device = "gpu")
self.coin = ops.CoinFlip(probability = 0.5)
def define_graph(self):
rng = self.coin()
self.jpegs, self.labels = self.input(name = "Reader")
images = self.decode(self.jpegs)
images = self.resize(images)
output = self.cmnp(images, mirror = rng)
return [output, self.labels]
Table 5 shows the resulting performance after adding nvJPEGDecoderRandomCrop:
|
|
DGX-2 |
AWS P3 |
TITAN RTX |
|
Performance |
21,592 |
10,418 |
578 |
Analysis
Let’s recap of all the measurements that we gathered so far in this article, shown in table 6.
|
|
Without DALI |
With DALI |
DALI with fused decoder |
|||
|
|
Performance |
Speedup |
Performance |
Speedup |
Performance |
Speedup |
|
DGX-2 |
12,586 |
N/A |
21,034 |
67.12% |
21,592 |
71.56% |
|
AWS P3 |
5,740 |
N/A |
10,138 |
76.62% |
10,418 |
81.50% |
|
TITAN RTX |
553 |
N/A |
575 |
3.98% |
578 |
4.52% |
ResNet50 without DALI is the reference. “Speedup” column shows the performance boost regarding the reference setup. In every hardware configuration tested, we can observe clear performance increases.
The numbers look pretty impressive. We achieved significant speedup for the configurations that represent state-of-the-art hardware for training. Thanks to DALI, ResNet50 trains more than 2 times faster. When training on high-end AWS, minutes shaved off the run are worth every penny (literally). Just using DALI can save 80% of your training costs.
A 5% boost might using TITAN RTX doesn’t seem like an impressive number. Let’s look at the underlying numbers a little more deeply. A rough estimate of training ResNet50 on TITAN RTX using ImageNet takes around 70 hours. Considering that implementing DALI saves you around 5% of that time, overall training shaves off 3.5 hours, which is a significant amount of time.
When to use DALI?
What indicators suggest taking a look at DALI to achieve improved training performance?
Let’s look back at the plain (no-DALI) training of ResNet50. The first test we did checked how the training behaved without preprocessing. We found a significant performance boost for the case without any preprocessing, indicating that the CPU is the bottleneck of the training. However, such observation doesn’t imply that using DALI will enhance the training speed.
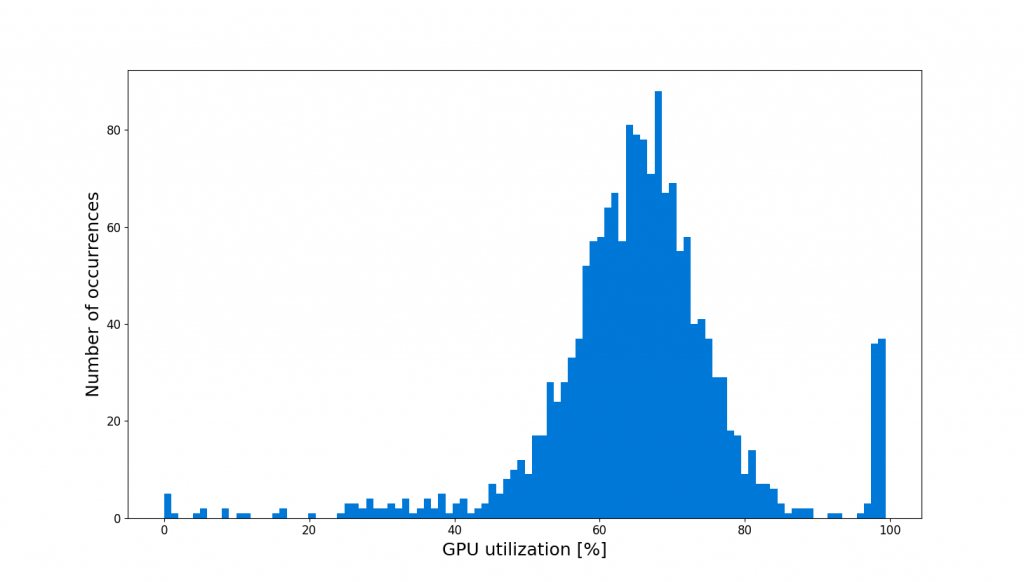
Since DALI transfers preprocessing operations to the GPU, it consumes the resources that could otherwise be used for the training. So does consuming some portion of the GPU resources to speed up preprocessing adversely affect overall training performance? Analyzing the GPU utilization during training answers this dilemma. Figure 3 shows such analysis using nvidia-smi stats -d gpuUtil command during training.
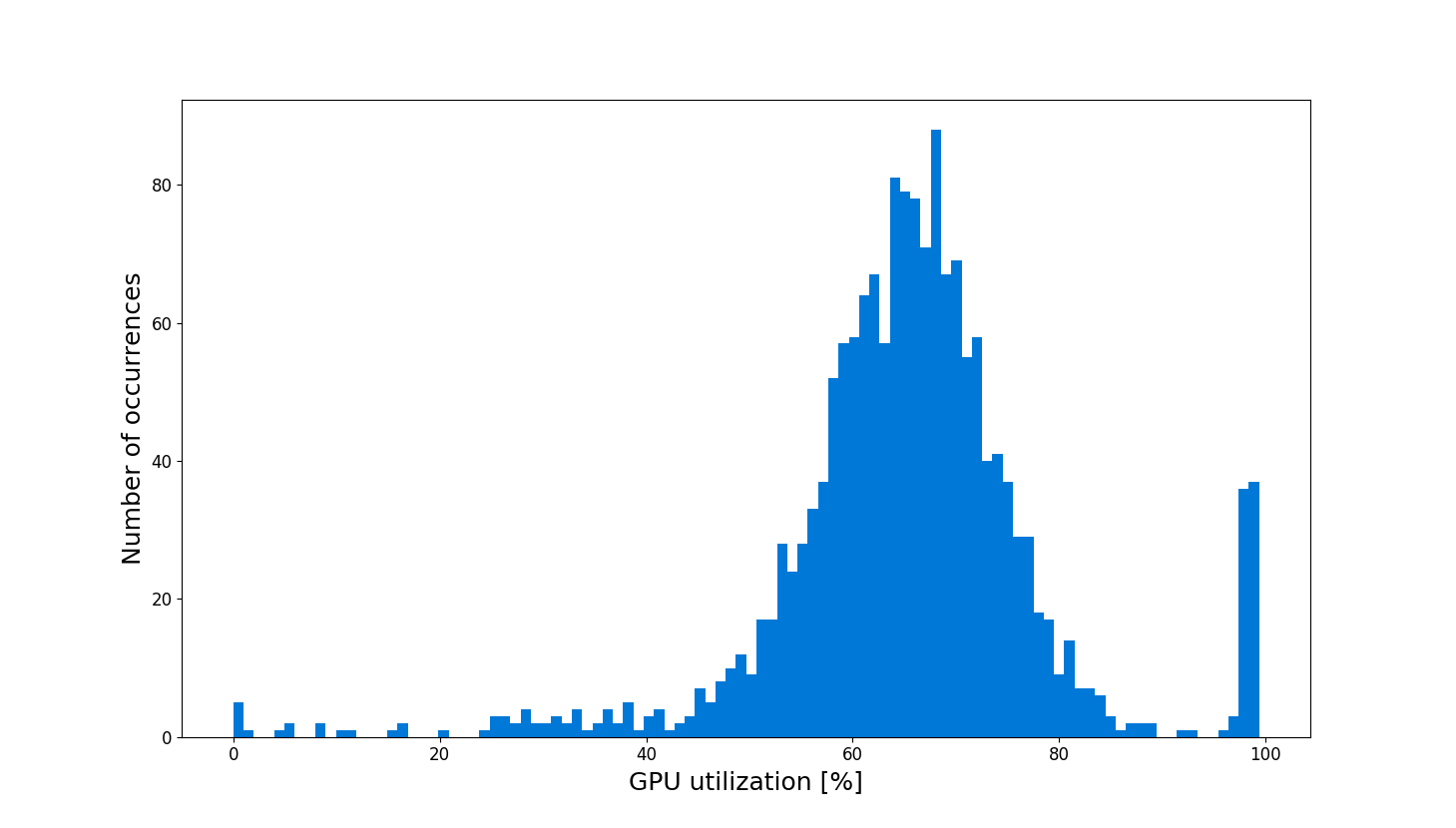
Figure 3. GPU utilization histogram during training without DALI
We observe that the GPU in the no-DALI case often fails to achieve 100% utilization. This means that headroom exists for DALI, which can engage the underutilized GPU resources for preprocessing computations. Figure 4 highlights GPU utilization once we add DALI to the mix.

Figure 4. GPU utilization histogram during training with DALI
Combining both utilization charts helps us make a better comparison, shown in figure 5.
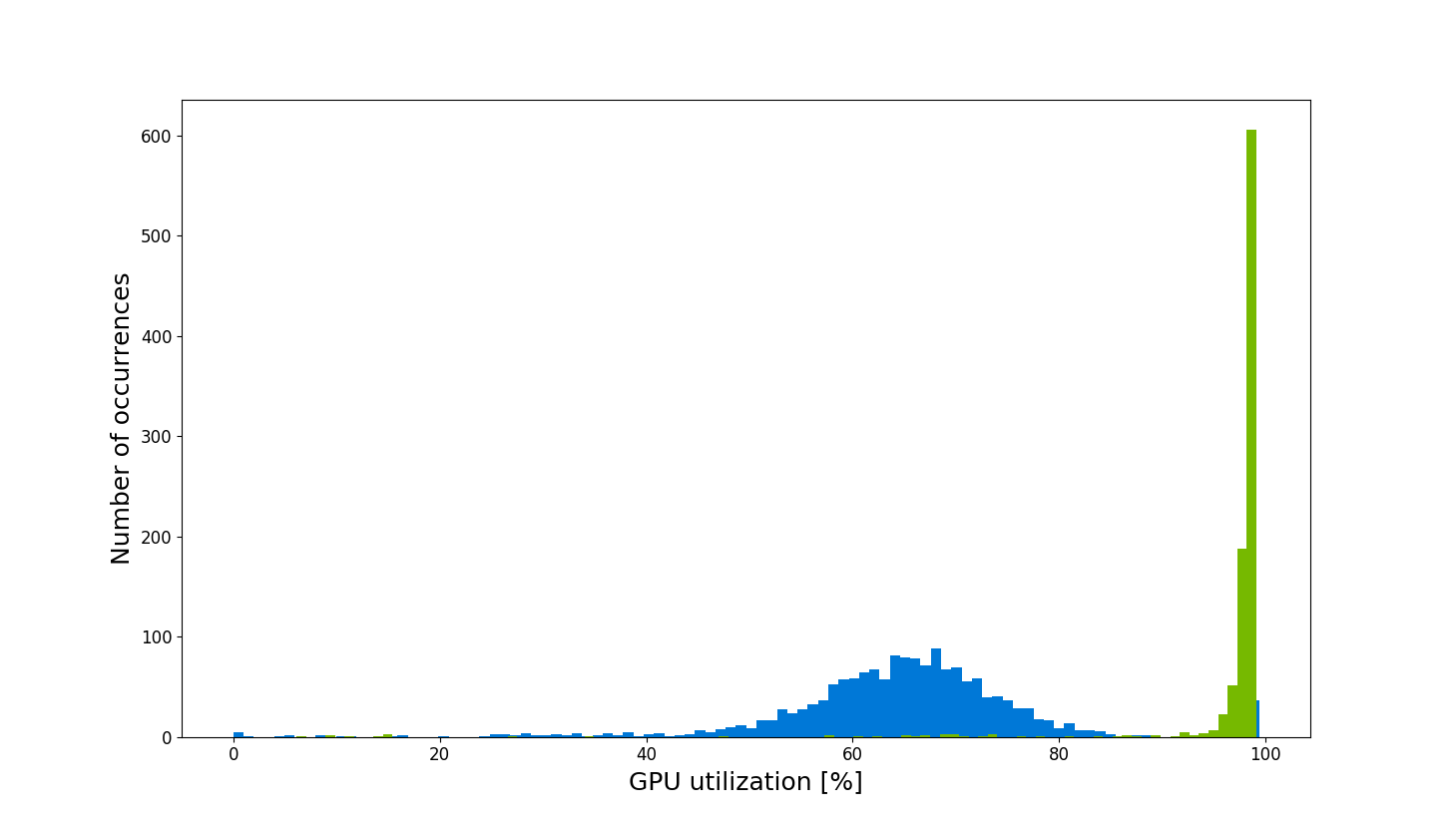
Figure 5. GPU utilization histogram during training with (green) and without (blue) DALI
We observe significant differences in GPU utilization. DALI enables you to really use everything your GPU has to offer in terms of performance.
Hence, consider taking the following steps:
- Make sure that the CPU is in fact the bottleneck of the training (in other words, try the synthetic data preprocessing pipeline).
- If so, also verify that GPU is underutilized throughout the training (nvidia-smi stats -d gpuUtil might come in handy for it).
What happens if any of these conditions isn’t met? You will still find reasons to use our cross-framework library, which supports many data formats. Stay tuned for future articles which elaborate more on why DALI is beneficial and what can be achieved with it.
Tell us what you think!
DALI is available as open source. We encourage your submissions and we’ll be happy to assist you with your contribution. See the DALI Web page and our GTC19 tech talk for more information and for next steps. If you like to use DALI for inference, check out this talk.
DALI is also available in NGC containers so you can download it using pip. We value your feedback, so please leave a comment below if you have any questions or feedback.
Michał Szołucha
Software Engineer, NVIDIA