
A version of this article was originally published at EE Times' Embedded.com Design Line. It is reprinted here with the permission of EE Times.
Still photos and videos traditionally taken with standalone cameras are increasingly being captured by camera-inclusive smartphones and tablets instead. And the post-capture processing that traditionally required a high-end computer and took a lengthy amount of time can now also take place near-immediately on a mobile electronics device, thanks to the rapidly improving capabilities of embedded vision technology.
Michael McDonald
President, Skylane Technology Consulting
Consultant, Embedded Vision Alliance
Next time you take a "selfie" or a shot of that great meatball entrée you're about to consume at the corner Italian restaurant, you will be contributing to the collection of 880 billion photos that Yahoo expects will be taken in 2014. Every day, Facebook users upload 350 million pictures and Snapchat users upload more than 400 million images. Video is also increasingly popular, with sites like YouTube receiving 100 hours of video every minute. These statistics, forecasted to increase further in the coming years, are indicative of two fundamental realities: people like to take pictures and shoot video, and the increasingly ubiquitous camera phone makes it easy to do so. Cell phone manufacturers have recognized this opportunity, and their cameras' capabilities are increasingly becoming a significant differentiator between models, therefore a notable investment target.
However, image sensor technology is quickly approaching some fundamental limits. The geometries of the sensor pixels are approaching the wavelengths of visible light, making it increasingly difficult to shrink their dimensions further. For example, latest-generation image sensors are constructed using 1,100 nm pixels, leaving little spare room to capture red-spectrum (~700 nm wavelength) light. Also, as each pixel's silicon footprint shrinks, the amount of light it is capable of capturing and converting to a proportional electrical charge also decreases. This decrease in sensitivity increases noise in low-light conditions, and decreases the dynamic range – the ability to see details in shadows and bright areas of images. Since smaller pixel sensors can capture fewer photons, each photon has a more pronounced impact on each pixel’s brightness.
Resolution Ceilings Prompt Refocus On Other Features
Given the challenges of further increases in image sensor resolution, camera phone manufacturers appear reluctant to further promote the feature. As a case in point, Apple’s advertising for the latest iPhone 5s doesn’t even mention resolution, instead focusing generically on image quality and other camera features. Many of these features leverage computational photography – using increasing processing power and sophisticated vision algorithms to make better photographs. After taking pictures, such advanced camera phones can edit them in such a way that image flaws – blur, low light, color fidelity, etc – are eliminated. In addition, computational photography enables brand new applications, such as reproducing a photographed object on a 3D printer, automatically labeling pictures so that you can easily find them in the future, or easily removing that person who walked in front of you while you were taking an otherwise perfect picture.
High Dynamic Range (HDR) is an example of computational photography that is now found on many camera phones. A camera without this capability may be hampered by images with under- and/or over-exposed regions. It can be difficult, for example, to capture the detail found in a shadow without making the sky look pure white. Conversely, capturing detail in the sky can make shadows pitch black. With HDR, multiple pictures are taken at different exposure settings, some optimized for bright regions of the image (such as the sky in the example), while others are optimized for dark areas (i.e. shadows). HDR algorithms then select and combine the best details of these multiple pictures, using them to synthesize a new image that captures the nuances of the clouds in the sky and the details in the shadows. This merging also needs to comprehend and compensate for between-image camera and subject movement, along with determining the optimum amount of light for different portions of the image (Figure 1).

Figure 1. An example of a high dynamic range image created by combining images captured using different exposure times.
Another example of computational photography is Super Resolution, wherein multiple images of a given scene are algorithmically combined, resulting in a final image that delivers finer detail than that present in any of the originals. A similar technique can be used to transform multiple poorly lit images into a higher-quality well-illuminated image. Movement between image frames, either caused by the camera or subject, increases the Super Resolution implementation challenge, since the resultant motion blur must be correctly differentiated from image noise and appropriately compensated for. In such cases, more intelligent (i.e. more computationally intensive) processing, such as object tracking, path prediction, and action identification, is required in order to combine pixels that might be in different locations of each image frame.
Multi-Image Combination and Content Subtraction
Users can now automatically "paint" a panorama image simply by capturing sequential frames of the entire scene from top to bottom and left to right, which are subsequently "stitched" together by means of computational photography algorithms. By means of this technique, the resolution of the resultant panorama picture will far exceed the native resolution of the camera phone's image sensor. As an example, a number of highly zoomed-in still pictures can be aggregated into a single image that shows a detailed city skyline, with the viewer then being able to zoom in and inspect the rooftop of a specific building (Figure 2). Microsoft (with its PhotoSynth application), CloudBurst Research, Apple (with the panorama feature built into latest-generation iPhones), and GigaPan are examples of companies and products that expose the potential of these sophisticated panorama algorithms, which do pattern matching and aspect ratio conversion as part of the "stitching" process.

Figure 2. The original version of this "stitched" panorama image is 8 gigapixels in size, roughly 1000x the resolution of a normal camera, and allows you to clearly view the people walking on the street when you zoom into it.
Revolutionary capabilities derived from inpainting, the process of reconstructing lost or deteriorated parts of images and videos, involve taking multiple pictures from slightly different perspectives and comparing them in order to differentiate between objects. Undesirable objects such as the proverbial "photobomb," identified via their location changes from frame to frame, can then be easily removed (Figure 3). Some replacement schemes sample the (ideally uniform) area surrounding the removed object (such as a grassy field or blue sky) and use it to fill in the region containing the removed object. Other approaches use pattern matching and change detection techniques to fill in the resulting image "hole". Alternatively, and similar to the green-screen techniques used in making movies, you can use computational photography algorithms to automatically and seamlessly insert a person or object into a still image or real-time video stream. The latter approach is beneficial in advanced videoconferencing setups, for example.

Figure 3. Object replacement enables the removable of unwanted items in a scene, such as this "photobombing" seal.
Extrapolating the Third Dimension
The ability to use computational photography to obtain "perfect focus" anywhere in a picture is being pursued by companies such as Lytro, Pelican Imaging, and Qualcomm. A technique known as plenoptic imaging involves taking multiple simultaneous pictures of the same scene, with the focus point for each picture set to a different distance. The images are then combined, placing every part of the final image in focus – or not – as desired (Figure 4). As a byproduct of this computational photography process, the user is also able to obtain a complete depth map for 3D image generation purposes, useful for 3D printing and other applications.



Figure 4. Plenoptic cameras enable you to post-capture refocus on near (top), mid (middle), and far (bottom) objects, all within the same image.
Homography is another way of building up a 3D image with a 2D camera using computational photography. In this process, a user moves the camera around and sequentially takes a series of shots of an object and/or environment from multiple angles and perspectives. The subsequent processing of the various captured perspectives is an extrapolation of the stereoscopic processing done by our eyes, and is used to determine depth data. The coordinates of the different viewpoints can be known with high precision thanks to the inertia (accelerometer, gyroscope) and location (GPS, Wi-Fi, cellular triangulation, magnetometer, barometer) sensors now built into mobile phones. By capturing multiple photos at various locations, you can assemble a 3D model of a room you're in, with the subsequent ability to virtually place yourself anywhere in that room and see things from that perspective. Google's recently unveiled Project Tango smartphone exemplifies the 3D model concept. The resultant 3D image of an object can also feed a 3D printer for duplication purposes.
Capturing and Compensating for Action
Every home user will soon have the ability to shoot a movie that's as smooth as that produced by a Hollywood cameraman (Figure 5). Computational photography can be used to create stable photos and videos, free of the blur artifacts that come from not holding the camera steady. Leveraging the movement information coming from the previously mentioned sensors, already integrated into cell phones, enables motion compensation in the final image or video. Furthermore, promising new research is showing that video images can be stabilized in all three dimensions, with the net effect of making it seem like the camera is smoothly moving on rails, for example, even if the photographer is in fact running while shooting the video.

FIgure 5. Motion compensation via vision algorithms enables steady shots with far less equipment than previously required with conventional schemes.
Cinemagraphs are an emerging new art medium that blends otherwise still photographs with minute movements. Think of a portrait where a person's hair is blowing or the subject's eye periodically winks, or a landscape shot that captures wind effects (Figure 6). The Cinemagraphs website offers some great examples of this new type of photography. Action, a Google Auto-Awesome feature, also enables multiple points of time to be combined and displayed in one image. In this way, the full range of motion of a person jumping, for example – lift-off, in flight, and landing – or a bird flying, or a horse running can be captured in a single shot (Figure 7).
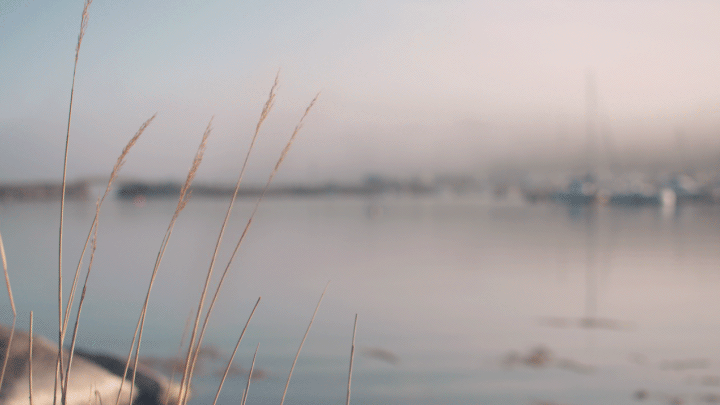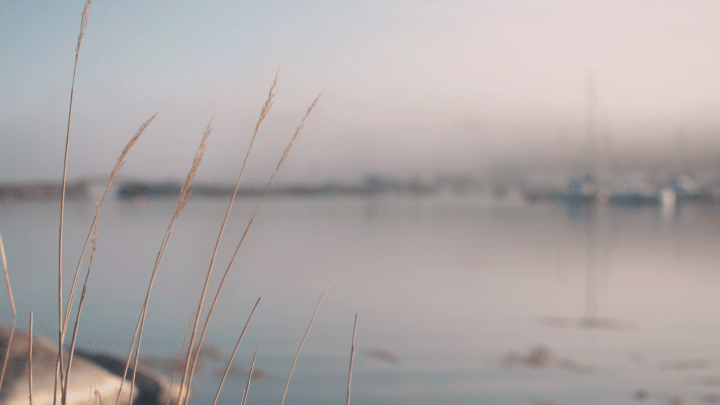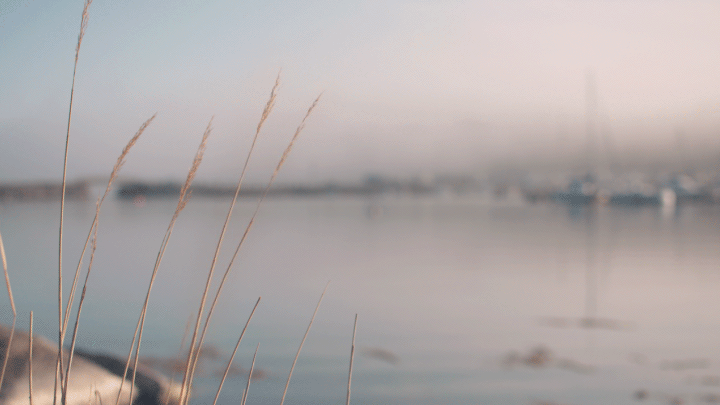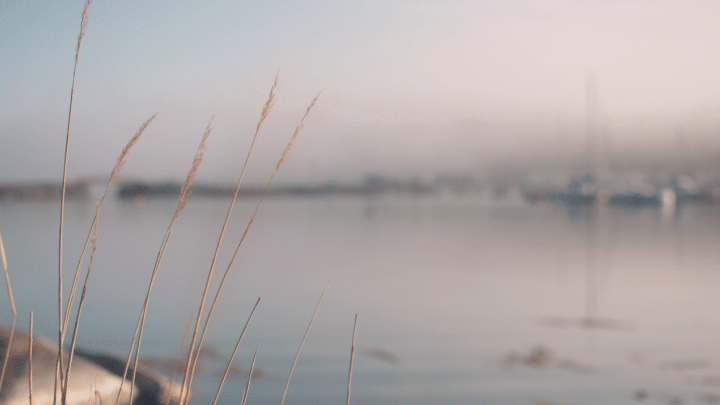
Figure 6. In this cinemagraph created using the animated GIF format, the reed grass is moving in the wind, while the rest of the image is static.


Figure 7. This Google-provided example shows how you can combine multiple shots (top) into a single image (bottom) to show motion over time.
Other advanced features found in the wildly popular GoPro and its competitors are finding their way to your cell phone, as well. Leading-edge camera phones such as Apple's iPhone 5s offer the ability to manipulate time in video; you can watch a person soar off a ski jump in slow motion, or peruse an afternoon's worth of skiing footage in just a few minutes, and even do both in the same video. Slow-motion capture in particular requires faster capture frame rates and high image processing requirements, as well as significantly larger storage requirements (Figure 8). As an alternative to consuming local resources, these needs align well with the increasingly robust ability to wirelessly stream high-resolution captured video to the "cloud" for remote processing and storage.
Figure 8. Extreme slow motion photography creates interesting new pictures and perspectives.
The ability to stream high quality video to the cloud is also enabling improved time-lapse photography and "life logging". In addition to the commercial applications of these concepts, such as a law enforcement officer or emergency professional recording a response situation, personal applications also exist, such as an Alzheimer's patient using video to improve memory recall or a consumer enhancing the appeal of an otherwise mundane home movie. The challenge with recording over extended periods of time is to intelligently and efficiently identify significant and relevant events to include in the video, labeling them for easier subsequent search. Video surveillance companies have already created robust analytics algorithms to initiate video recording based on object movement, face detection, and other "triggers". These same techniques will soon find their way into your personal cell phone.
Object Identification and Reality Augmentation
The ubiquity of cell phone cameras is an enabler for new cell phone applications. For example, iOnRoad – acquired in 2013 by Harman – created a cell phone camera-based application to enable safer driving. With the cell phone mounted to the vehicle dashboard, it recognizes and issues alerts for unsafe driving conditions – following too closely, leaving your lane, etc – after analyzing the captured video stream. Conversely, when not driving, a user might enjoy another application called Vivino, which recognizes wine labels using image recognition algorithms licensed from a company called Kooaba.
Plenty of other object identification applications are coming to market. In early February, for example, Amazon added the "Flow" feature to its mobile app, which identifies objects (for sale in stores, for example) you point the cell phone's camera at, tells you how much Amazon is selling the item for, and enables you to place an order then and there. This is one of myriad ways that the camera in a cell phone (or integrated into your glasses or watch, for that matter) will be able to identify objects and present the user with additional information about them, a feature known as augmented reality. Applications are already emerging that identify and translate signs written in foreign languages, enable a child to blend imaginary characters with real surroundings to create exciting new games, and countless other examples (Figure 9).

FIgure 9. This augmented reality example shows how the technology provides additional information about objects in an image.
And then of course there's perhaps the most important object of all, the human face. Face detection, face recognition and other facial analysis algorithms represent one of the hottest areas of industry investment and development. Just in the past several years, Apple acquired Polar Rose, Google acquired Neven Vision, PittPatt, and Viewdle, Facebook acquired Face.com, and Yahoo acquired IQ Engines. While some of these solutions implement facial analysis "in the cloud", other mobile-based solutions will eventually automatically tag individuals as their pictures are taken. Other facial analysis applications detect that a person is smiling and/or that their eyes are open, triggering the shutter action at that precise moment (Figure 10).

Figure 10. Face detection and recognition and other facial analysis capabilities are now available on many camera phones.
For More Information
The compute performance required to enable computational photography and its underlying vision processing algorithms is quite high. Historically, these functions and solutions have been exclusively deployed on more powerful desktop systems; mobile architectures had insufficient performance or a power budget that limited how much they were able to do. However, with the increased interest and proliferation of these vision and computational photography functions, silicon architectures are being optimized to run these algorithms more efficiently and with lower power. The next article in this series will take a look at some of the emerging changes in processors and sensors that will make computational photography capabilities increasingly prevelant in the future.
Computational photography is one of the key applications being enabled and accelerated by the Embedded Vision Alliance, a worldwide organization of technology developers and providers. Embedded vision refers to the implementation vision technology in mobile devices, embedded systems, special-purpose PCs, and the "cloud". First and foremost, the Alliance's mission is to provide engineers with practical education, information, and insights to help them incorporate embedded vision capabilities into new and existing products. To execute this mission, the Alliance maintains a website providing tutorial articles, videos, code downloads and a discussion forum staffed by technology experts. Registered website users can also receive the Alliance’s twice-monthly email newsletter, among other benefits.
In addition, the Embedded Vision Alliance offers a free online training facility for embedded vision product developers: the Embedded Vision Academy. This area of the Alliance website provides in-depth technical training and other resources to help engineers integrate visual intelligence into next-generation embedded and consumer devices. Course material in the Embedded Vision Academy spans a wide range of vision-related subjects, from basic vision algorithms to image pre-processing, image sensor interfaces, and software development techniques and tools such as OpenCV. Access is free to all through a simple registration process.
The Alliance also holds Embedded Vision Summit conferences in Silicon Valley. Embedded Vision Summits are technical educational forums for product creators interested in incorporating visual intelligence into electronic systems and software. They provide how-to presentations, inspiring keynote talks, demonstrations, and opportunities to interact with technical experts from Alliance member companies. These events are intended to:
- Inspire attendees' imaginations about the potential applications for practical computer vision technology through exciting presentations and demonstrations.
- Offer practical know-how for attendees to help them incorporate vision capabilities into their hardware and software products, and
- Provide opportunities for attendees to meet and talk with leading vision technology companies and learn about their offerings.
The most recent Embedded Vision Summit was held in May 2014, and a comprehensive archive of keynote, technical tutorial and product demonstration videos, along with presentation slide sets, is available on the Alliance website. The next Embedded Vision Summit will take place on April 30, 2015 in Santa Clara, California; please reserve a spot on your calendar and plan to attend.
Michael McDonald is President of Skylane Technology Consulting, which provides marketing and consulting services to companies and startups primarily in vision, computational photography, and ADAS markets. He has over 20 years of experience working for technology leaders including Broadcom, Marvell, LSI, and AMD. He is hands-on and has helped define everything from hardware to software, and silicon to systems. Michael has previously managed $200+M businesses, served as a general manager, managed both small and large teams, and executed numerous partnerships and acquisitions. He has a BSEE from Rice University.